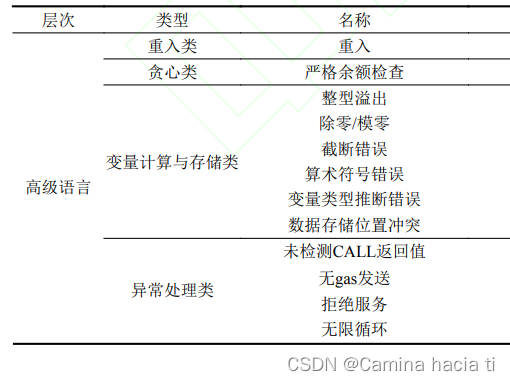
文章目录
英语积累
- Machine learning systems that operate in the real openworld invariably encounter test-time data that is unlike training examples, such as anomalies or rare objects that were insufficiently or even never observed during training. invariably:一贯的
- … can be crisply formulated as … 可以被很清晰的定义/表述为
- an elegant idea is to… 一个绝佳的方法是…
为什么使用GAN系列网络进行开放集检测
综述:Applications of Generative Adversarial Networks in Anomaly Detection: A Systematic Literature Review
GAN网络可以学习数据分布
GAN的基本思想是通过让两个神经网络相互对抗,从而学习到数据的分布。其中一个神经网络被称为生成器(Generator),它的目标是生成与真实数据相似的假数据;另一个神经网络被称为判别器(Discriminator),它的目标是区分真实数据和假数据。两个网络相互对抗,不断调整参数,从而最终生成具有高质量和多样性的假数据。GAN网络有产生新数据的能力,可以大大缓解新颖类检测中缺少新颖类别数据的情况。
摘要
开放集现阶段两大方法:
- 利用一些例外(异常)数据作为开放集,训练一个闭集VS开放集的二分类检测器
- 使用GAN网络无监督学习闭集数据分布,使用该判别器作为开放集的似然函数
两个方法的缺陷:
- 作为开放集使用的异常数据无法穷尽现实世界的所有可能的未知值
- GAN网络训练过程不稳定
解决: 提出OpenGAN
- 使用对抗合成的假数据填充可用的真实开放集训练数据
- 在闭集k-ways的特征基础上建立判别器
1. 前言

算法演变过程:
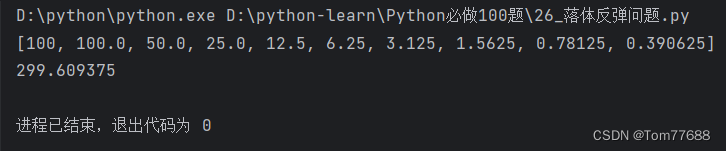
- 使用GAN网络生成fake data,训练一个判别 close data 和 fake data 的二分类判别器;
- 在训练时使用一些真实世界中的离群数据(outlier data) 可以增强网络性能,即训练一个判别close data和open data的判别器;
- O p e n G A N p i x OpenGAN^{pix} OpenGANpix: 结合GAN产生的fake data并且使用真实世界中的outlier data来训练判别器
- O p e n G A N f e a OpenGAN^{fea} OpenGANfea : 不再使用图片的RGB像素进行训练,而是使用off-the-shelf (OTS) features来对GAN网络的训练;
off-the-shelf (OTS) features: 通过闭集检测的网络计算出来的特征
2. 相关工作
开集检测
一般来说,异常数据不会在训练阶段出现。
通用方法:
- 在闭集数据上训练k-ways闭集分类器,然后用于开放集检测
- 开发集成模型: 在闭集数据上训练k-ways闭集分类器 + 训练时使用合成的fake data进行开集检测,会牺闭集检测的准确率
基于GAN网络的开集检测
基于暴露异常数据的开集检测
3. OpenGAN
开放集检测步骤:
- 把测试数据先分类:是开集还是闭集 (关键步骤)
- 对闭集进行K-ways分类
一般的开放集检测都会在训练时设置开放集数据不可见,但是有研究证明在训练阶段将一些异常数据作为开放集数据进行训练可以有限的提升检测性能;
但是由于很难产生覆盖开放世界的训练集数据,而且分类器可能会在异常数据上发生过拟合,因此提出OpenGAN
OpenGAN优势:使用GAN网络产生假数据作为开放集数据的训练集去欺骗分类器
3.1 公式建模
3.1.1 二分类方法
给定一个二元分类器D,它的训练目标是将输入样本分为闭集(closed-set)和开集(open-set)两个类别。
D c l o s e d ( x ) D_{closed}(x) Dclosed(x):在闭集上的数据分布
D o p e n ( x ) D_{open}(x) Dopen(x):在开放集上的数据分布(不属于闭集)
m a x D E x ∼ D c l o s e d [ l o g D ( x ) ] + λ o ⋅ E x ∼ D o p e n [ l o g ( 1 − D ( x ) ) ] max_D E_{x∼D_{closed}} [logD(x)] + λo · E_{x∼D_{open}} [log(1−D(x))] maxDEx∼Dclosed[logD(x)]+λo⋅Ex∼Dopen[log(1−D(x))]
D ( x ) D(x) D(x):这表示分类器D对于给定输入样本x的输出。它表示样本属于闭集类别的概率。也就是说,D(x)是模型对于输入样本属于闭集的估计概率。
E x ∼ D c l o s e d [ l o g D ( x ) ] E_{x∼D_{closed}} [logD(x)] Ex∼Dclosed[logD(x)]:这是第一项,表示对于从闭集数据中抽取的样本x,将其输入到分类器D中,并计算其对数概率logD(x),然后对所有闭集样本取平均。这一项鼓励分类器正确地对闭集样本进行分类,即将闭集样本的概率估计尽可能地提高。
E x ∼ D o p e n [ l o g ( 1 − D ( x ) ) ] E_{x∼D_{open}} [log(1−D(x))] Ex∼Dopen[log(1−D(x))]:这是第二项,表示对于从开集数据中抽取的样本x,将其输入到分类器D中,并计算其对数概率log(1−D(x)),然后对所有开集样本取平均。这一项鼓励分类器正确地将开集样本排除在闭集之外,即将开集样本的概率估计尽可能地降低。
λ o λo λo:这是一个超参数,用于调节第二项(开集样本)相对于第一项(闭集样本)的权重。通过调整λo的值,可以控制分类器在训练过程中对于闭集和开集样本的重视程度。
存在问题
二分类方法的有效性取决于开集训练样本是否能够代表分类器在测试时遇到的开集数据。 如果开集训练样本不能充分涵盖开放世界数据中的变化和多样性,那么分类器在面对未见过的开集样本时可能表现不佳。
如何解决
使用GAN网络生成数据。
3.1.2 使用合成数据
G ( z ) G(z) G(z) : 一个可以生成图像的生成网络,生成器网络 G 接收从高斯正态分布中随机采样得到的噪声输入 z,并使用这个噪声向量生成合成的图像。
这些合成图像可以被视为额外的负例或开放集样本,然后将它们添加到用于训练分类器D的训练数据池中。D ( D i s c r i m i n a t o r ) D(Discriminator) D(Discriminator): 判别器,负责判断输入的数据是真实的还是生成的。
为防止生成器网络 G 合成的图片过于简单,使用对抗性训练(adversarial training)的方法来训练生成器网络 G,以生成具有欺骗性的困难示例,使分类器 D 难以将其分类为开放集数据。
GAN的损失如下所示:
m i n G E z ∼ N [ l o g ( 1 − D ( G ( z ) ) ) ] min_G E_{z∼N} [ log (1 - D(G(z))) ] minGEz∼N[log(1−D(G(z)))]
该损失函数的意思是,生成器G最小化判别器D对生成的合成数据不是开放集数据的分类概率;也就是说,生成器G试图生成合成数据,使得判别器D将其误判为开放集数据的概率最大化。 通过这个过程,生成器G学会生成更难以分辨的合成数据,从而提高了判别器D在面对开放集数据时的性能和鲁棒性。
存在问题
开放集判别是指判别器 D 能够正确识别已知类别的图像,并将未知类别的图像标记为“未知”或“开放集”。然而,如果生成器 G 生成的图像与已知类别的图像非常相似,判别器 D 可能会错误地将其分类为已知类别(close-set),而无法准确识别为开放集。
如何解决
设计一些技术或方法,使得生成器 G 不仅生成逼真的图像,还能生成具有一定挑战性的图像,使判别器 D 能够有效地进行开放集判别。
这样,判别器 D 就能够准确地将开放集的数据标记为“未知”,而不是错误地将其分类为已知类别。
3.1.3 OpenGAN
通过使用真实的开放集和封闭集数据,以及生成的开放集数据,对判别器D和生成器G进行联合训练。
OpenGAN方法采用了一种类似GAN的最小最大优化过程,同时优化判别器D和生成器G。 公式如下所示。
m a x D m i n G E x ∼ D c l o s e d [ l o g D ( x ) ] + λ o ⋅ E x ∼ D o p e n [ l o g ( 1 − D ( x ) ) ] + λ G ⋅ E z ∼ N [ l o g ( 1 − D ( G ( z ) ) ) ] max_D min_G E_{x∼D_{closed}} [logD(x)] + λ_o · E_{x∼D_{open}} [log(1−D(x))] + λ_G · E_{z∼N} [log(1 − D(G(z)))] maxDminGEx∼Dclosed[logD(x)]+λo⋅Ex∼Dopen[log(1−D(x))]+λG⋅Ez∼N[log(1−D(G(z)))]
- E x ∼ D c l o s e d [ l o g D ( x ) ] E_{x∼D_{closed}} [logD(x)] Ex∼Dclosed[logD(x)] : 表示使用封闭集数据训练判别器D,使其正确区分封闭集数据。
- E x ∼ D o p e n [ l o g ( 1 − D ( x ) ) ] E_{x∼D_{open}} [log(1−D(x))] Ex∼Dopen[log(1−D(x))]:表示使用真实的开放集数据训练判别器D,使其将开放集数据识别为开放集。
- E z ∼ N [ l o g ( 1 − D ( G ( z ) ) ) ] E_{z∼N} [log(1 − D(G(z)))] Ez∼N[log(1−D(G(z)))]:表示使用生成器G生成的假开放集数据训练判别器D,使其能够正确区分生成的假开放集数据。
- λ o λ_o λo 控制了真实开放集数据对于训练的贡献,而 λ G λ_G λG 控制了生成器G生成的假开放集数据对于训练的贡献。
当没有真实的开放集训练样本时( λ o = 0 λ_o=0 λo=0),上述最小最大优化问题仍然可以训练一个用于开放集分类的判别器D。在这种情况下,训练OpenGAN等效于训练一个普通的GAN,并使用其判别器作为开放集的似然函数。
3.1.4 模型验证
由于对抗生成训练会导致判别器D无法区分闭集中的真实数据和由生成器G产生的fake image,因此需要使用真实的异常数据来进行模型的验证
3.2 先前基于GAN方法的总结
3.2.1 生成器vs判别器
之前的方法中主要是利用生成器生成图像来扩充训练集,但是该方法主要是利用判别器来判别闭集图像和开集图像。
3.2.2 Features vs. Pixels
直接利用features训练GAN网络比使用RGB图像的效果更好。