1.图空间(Space)操作
1.1创建图空间,指定vid_type为整形
CREATE SPACE play_space (partition_num = 10, replica_factor = 1, vid_type = INT64) COMMENT = "运动员库表空间";1.2创建图空间,指定vid_type为字符串
CREATE SPACE play_space (partition_num = 10, replica_factor = 1, vid_type = FIXED_STRING(32)) COMMENT = "运动员库表空间";1.3删除图空间
drop SPACE play_space;2.标签(Tag)操作
2.1创建点
CREATE tag player (name string NULL COMMENT "姓名", age int8 NULL COMMENT "年龄") COMMENT = "球员";
CREATE tag team (name string NULL COMMENT "球队名称") COMMENT = "归属球队";2.2查看库下面的点
SHOW TAGS;2.2查看某个点的属性
describe TAG player;2.3基于标签创建点
单条插入示例:
insert vertex player(name,age) values 100:("詹姆斯",38);
insert vertex player(name,age) values 101:("库里",34);
insert vertex player(name,age) values 102:("杜兰特",34);批量插入示例:
insert vertex team(name) values 200:("洛杉矶湖人队"),201:("金州勇士队"),202:("布鲁克林篮网队");2.4查看点
指定属性查看示例:
fetch prop on player 100,101,102 YIELD properties(vertex).name,properties(vertex).age;查询全部属性示例 :
fetch prop on team 200,201,202 YIELD properties(vertex);2.5删除点
delete vertex 100;3.边(Edge)操作
3.1创建边
CREATE edge follow (attention_rate int16 NULL COMMENT "关注度") COMMENT = "球员关注度关联表";
CREATE edge service (start_time int32 NULL COMMENT "开始时间", end_time int32 NULL COMMENT "结束时间") COMMENT = "球员服役时间关联表";3.2查看库下面的边
SHOW edges;3.3查看边的属性
describe edge service;3.4插入边
单条插入示例:
insert edge follow(attention_rate) values 100->101:(20);
insert edge follow(attention_rate) values 101->102:(50);
insert edge follow(attention_rate) values 102->103:(80);批量插入示例:
insert edge service(start_time,end_time) values 100->200:(2003,2023),101->201:(2009,2023),102->203:(2007,2023);3.5查看边
单条查看示例:
fetch prop on follow 100->101 YIELD properties(edge);批量查看示例:
fetch prop on service 100->200,101->201 YIELD properties(edge).start_time,properties(edge).end_time;4.查看图谱关系图
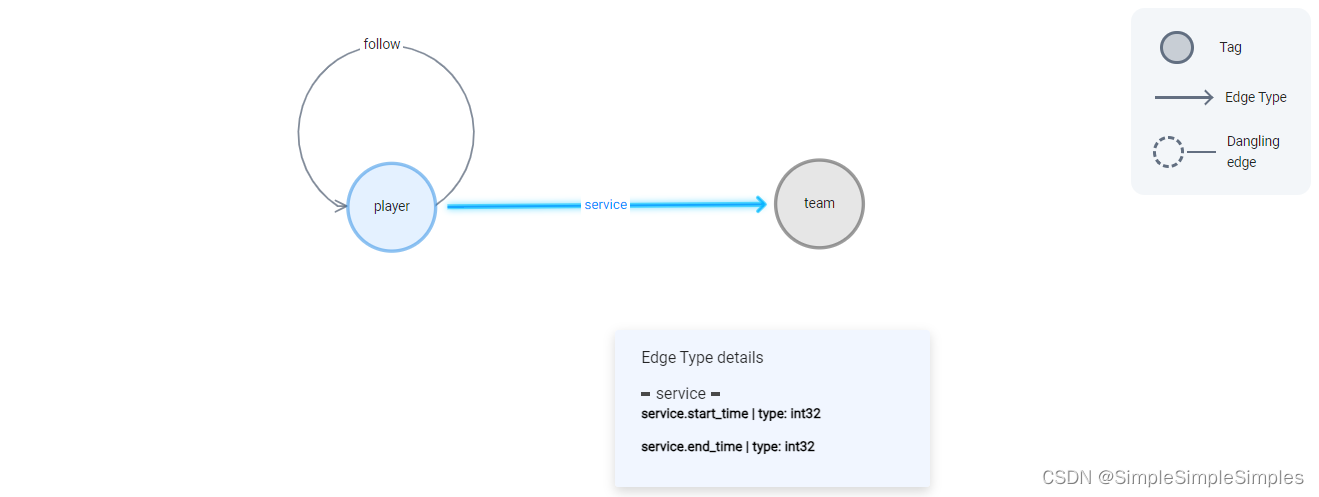
5.索引创建
5.1创建索引
CREATE {TAG | EDGE} INDEX [IF NOT EXISTS] <index_name>
ON {<tag_name> | <edge_name>} ([<prop_name_list>]) [COMMENT = '<comment>'];示例
//点
CREATE TAG INDEX IF NOT EXISTS index_player ON player(name(30), age);
//边
CREATE EDGE INDEX IF NOT EXISTS index_follow ON follow(attention_rate);
5.2重建索引
REBUILD {TAG | EDGE} INDEX <index_name>;示例
//点
REBUILD TAG INDEX index_name;
//边
REBUILD EDGE INDEX index_follow;6.常用查询
6.1Go语句查询
语句从一个或多个点开始,沿着一条或多条边遍历,返回YIELD子句中指定的信息。
GO [[<M> TO] <N> STEPS ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD [DISTINCT] <return_list>
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];从vid为100的球员开始找,沿着service边找到终点vid,输出起点vid和终点vid及其信息
GO FROM 100 OVER service YIELD id($^),properties($^),id($$),properties($$);
备注:
$^ :表示边的起点
$$ :表示边的终点
properties() :返回点/边的所有属性
6.2FETCH语句查询
可以获得点或边的属性
6.2.1查看点
查看点
语法:
FETCH PROP ON {<tag_name>[, tag_name ...] | *}
<vid> [, vid ...]
YIELD <return_list> [AS <alias>];
示例:
fetch prop on player 100 YIELD properties(vertex);6.2.2查看边
语法:
FETCH PROP ON <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid> ...]
YIELD <output>;
示例:
fetch prop on follow 100->101 YIELD properties(edge);6.3LOOKUP查找
语句是基于索引的,和WHERE子句一起使用,查找符合特定条件的数据,要先创建索引
LOOKUP ON {<vertex_tag> | <edge_type>}
[WHERE <expression> [AND <expression> ...]]
YIELD <return_list> [AS <alias>];
<return_list>
<prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];a.找出点中名称为詹姆斯的球员
LOOKUP ON player WHERE player.name == "詹姆斯" YIELD properties(vertex); 
b.找出球员中名字经库里开始,并且年龄在34和38两个值之前的球员
LOOKUP ON player WHERE player.name STARTS WITH "库里" AND player.age IN [34,38] YIELD properties(vertex).name, properties(vertex).age; 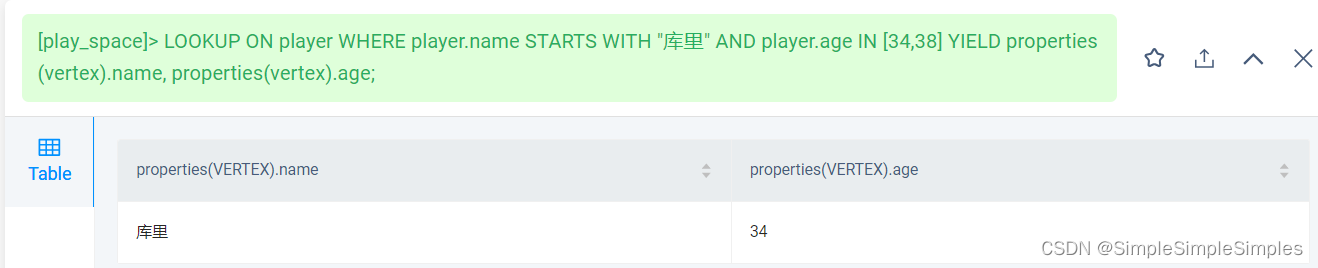
c.根据条件查看边
LOOKUP ON follow WHERE follow.attention_rate > 20 YIELD properties(edge); 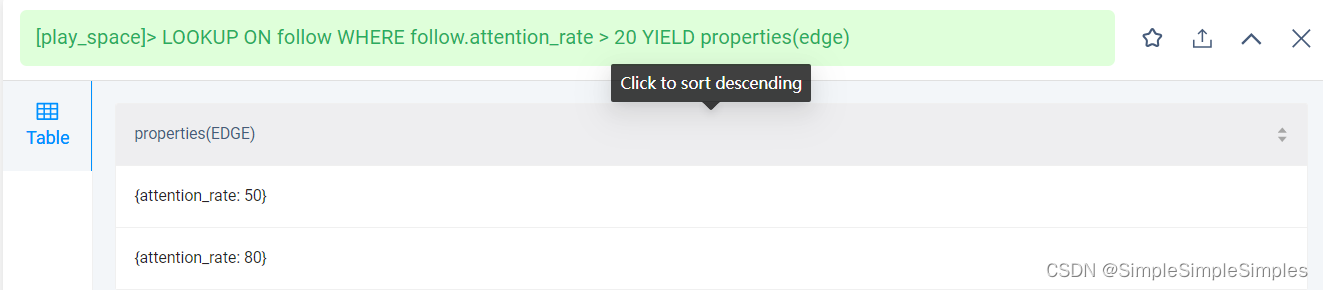
d.统计边或者点的数量
LOOKUP ON player YIELD id(vertex)| YIELD COUNT(*) AS Player_Number;
LOOKUP ON follow YIELD edge AS e| YIELD COUNT(*) AS Follow_Number;
6.4MATCH查找
可以灵活的描述各种图模式,但是它依赖索引去匹配 Nebula Graph 中的数据模型,性能也还需要调优,要先创建索引
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
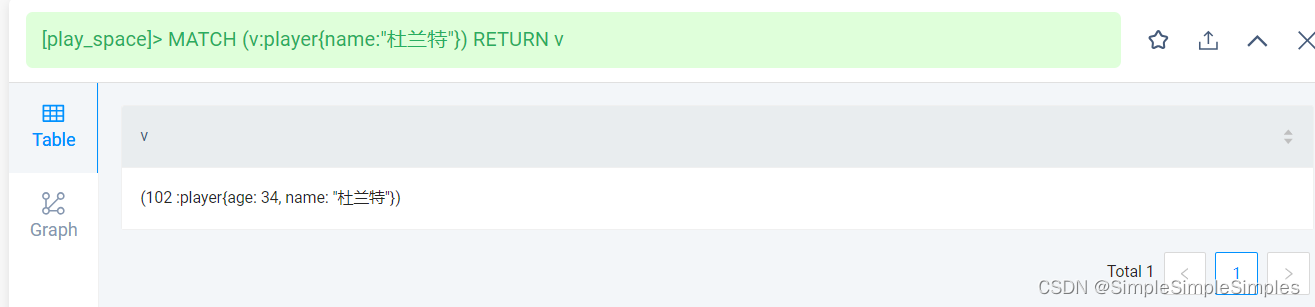
查找球员名称为的点并返回
MATCH (v:player{name:"杜兰特"}) RETURN v