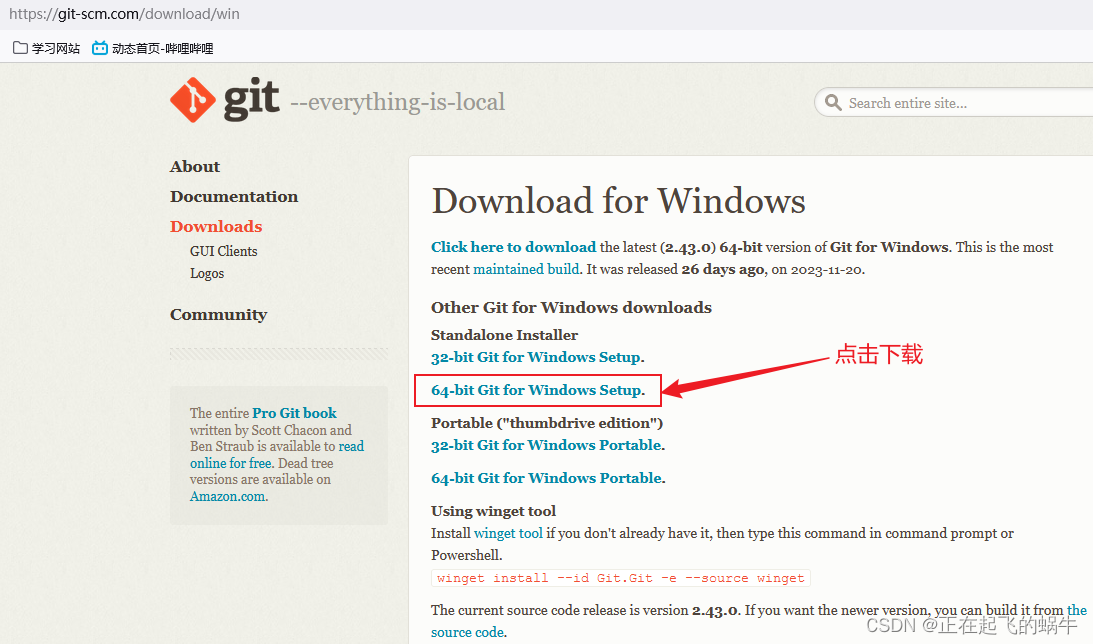
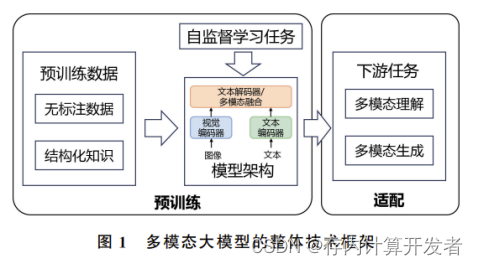
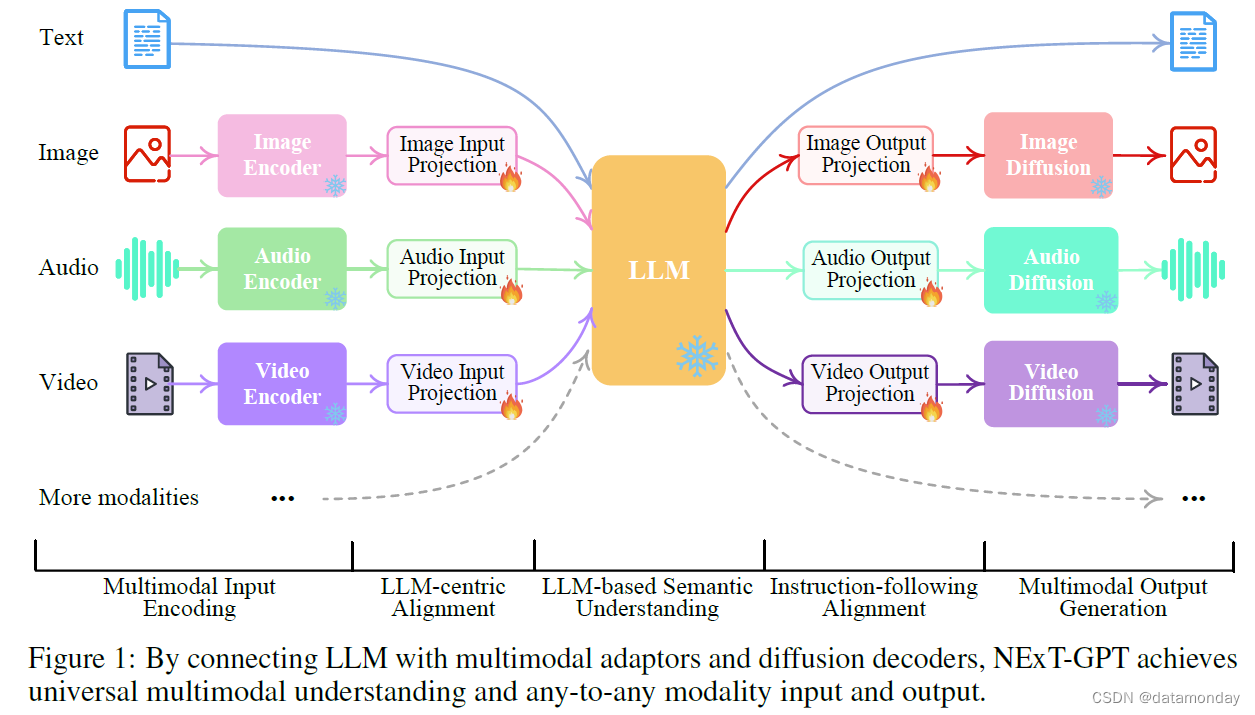
前言:目前视频生成的大部分工作都是只能生成无声音的视频,距离真正可用的视频还有不小的差距。CoDi提出了一种并行多模态生成的大模型,可以同时生成带有音频的视频,距离真正的视频生成更近了一步。相信在不远的将来,可以AI生成的模型可以无缝平替抖音等平台的短视频。这篇博客详细解读一下这篇论文《Any-to-Any Generation via Composable Diffusion》。
目录
前言:目前视频生成的大部分工作都是只能生成无声音的视频,距离真正可用的视频还有不小的差距。CoDi提出了一种并行多模态生成的大模型,可以同时生成带有音频的视频,距离真正的视频生成更近了一步。相信在不远的将来,可以AI生成的模型可以无缝平替抖音等平台的短视频。这篇博客详细解读一下这篇论文《Any-to-Any Generation via Composable Diffusion》。
目录






















![[elementPlus] teleported 在 ElSubMenu中的用途](https://img-blog.csdnimg.cn/direct/34c7ef6084fe4d84a883d3c73a41bb0c.png)