这是一款通用视觉多模态大模型,支持从视觉理解到视觉生成、从低层次到高层次的一系列视觉任务,解决了困扰大语言模型产业已久的图像/视频模型割裂问题,提供了一个全面统一静态图像与动态视频内容的理解、生成、分割、编辑等任务的像素级通用视觉多模态大模型。
项目主页&Demo:https://vitron-llm.github.io/
论文链接:https://is.gd/aGu0VV
开源代码:https://github.com/SkyworkAI/Vitron
Vitron作为一个统一的像素级视觉多模态大语言模型,实现了从低层次到高层次的视觉任务的全面支持,能够处理复杂的视觉任务,并理解和生成图像和视频内容,提供了强大的视觉理解和任务执行能力。
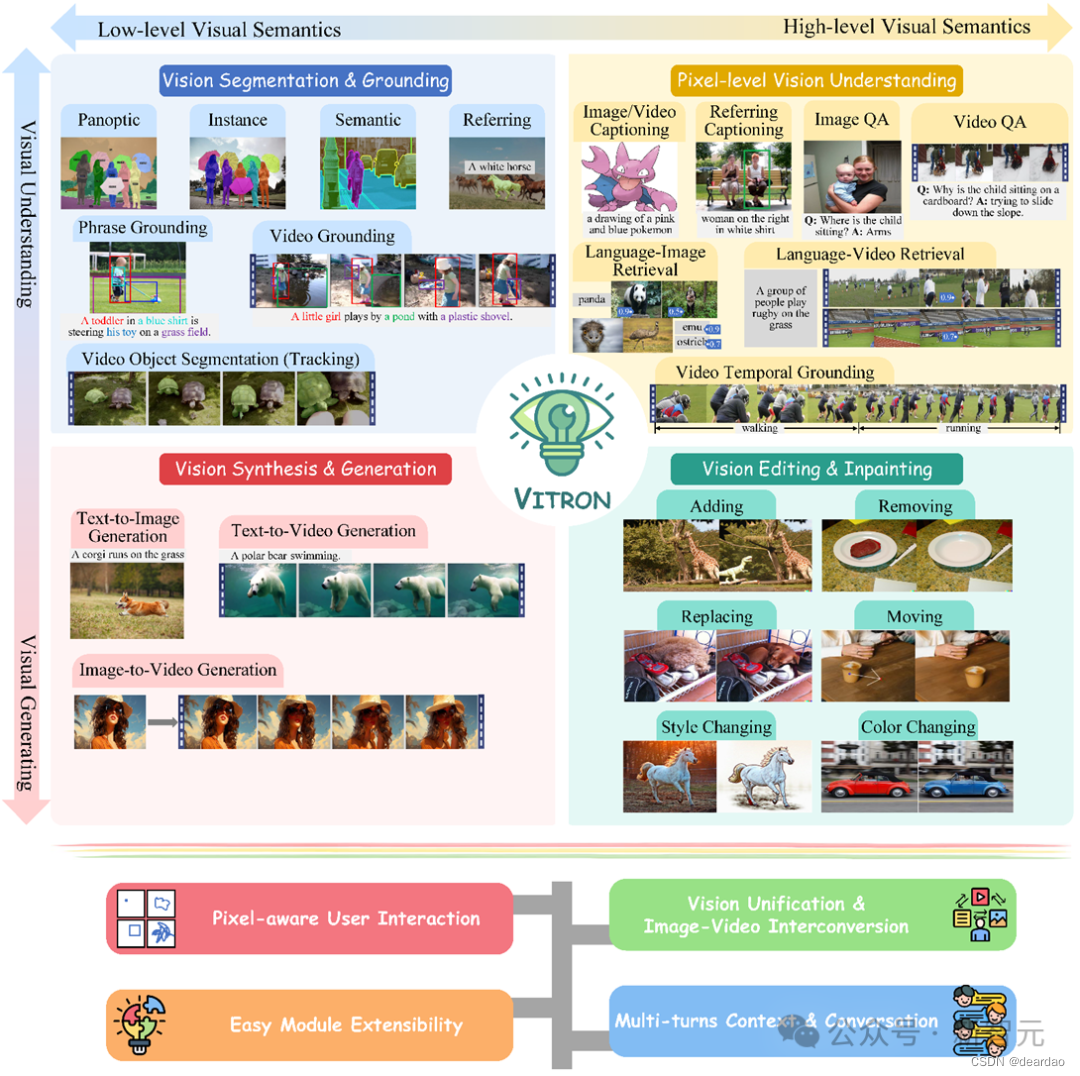
多模态大语言模型(MLLMs)在多个社区火爆发展且迅速出圈,通过引入能进行视觉感知的模块,扩展纯语言基础LLMs至MLLMs,众多在图像理解方面强大卓越的MLLMs被研发问世,例如BLIP-2、LLaVA、MiniGPT-4等等。与此同时,专注于视频理解的MLLMs也陆续面世,如VideoChat、Video-LLaMA和Video-LLaVA等等。
研究人员主要从两个维度试图进一步扩展MLLMs的能力。一方面,研究人员尝试深化MLLMs对视觉的理解,从粗略的实例级理解过渡到对图像的像素级细粒度理解,从而实现视觉区域定位(Regional Grounding)能力,如GLaMM、PixelLM、NExT-Chat和MiniGPT-v2等。
另一方面,研究人员尝试扩展MLLMs可以支持的视觉功能。部分研究已经开始研究让MLLMs不仅理解输入视觉信号,还能支持生成输出视觉内容。比如,GILL、Emu等MLLMs能够灵活生成图像内容,以及GPT4Video和NExT-GPT实现视频生成。

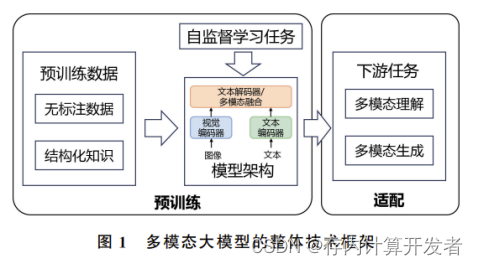
训练过程: Ref
- 视觉-语言整体对齐学习。将输入的视觉语言特征映射到一个统一的特征空间中,从而使其能够有效理解输入的多模态信号。
- 细粒度的时空视觉定位指令微调。提出了一种细粒度的时空视觉定位指令微调训练,核心思想是使LLM能够定位图像的细粒度空间性和视频的具体时序特性。
- 输出端面向命令调用的指令微调。让系统具备精确执行命令的能力,允许LLM生成适当且正确的调用文本。


























![[ESP32]:TFLite Micro推理CIFAR10模型](https://img-blog.csdnimg.cn/direct/13ff412ca6214a059ef91d78c12f2a7d.png#pic_center)