在批处理统计中,我们可以等待一批数据都到齐后,统一处理。但是在实时处理统计中,我们是来一条就得处理一条,那么我们怎么统计最近一段时间内的数据呢?引入“窗口”。
所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。
一.窗口(Window)
1.1 窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
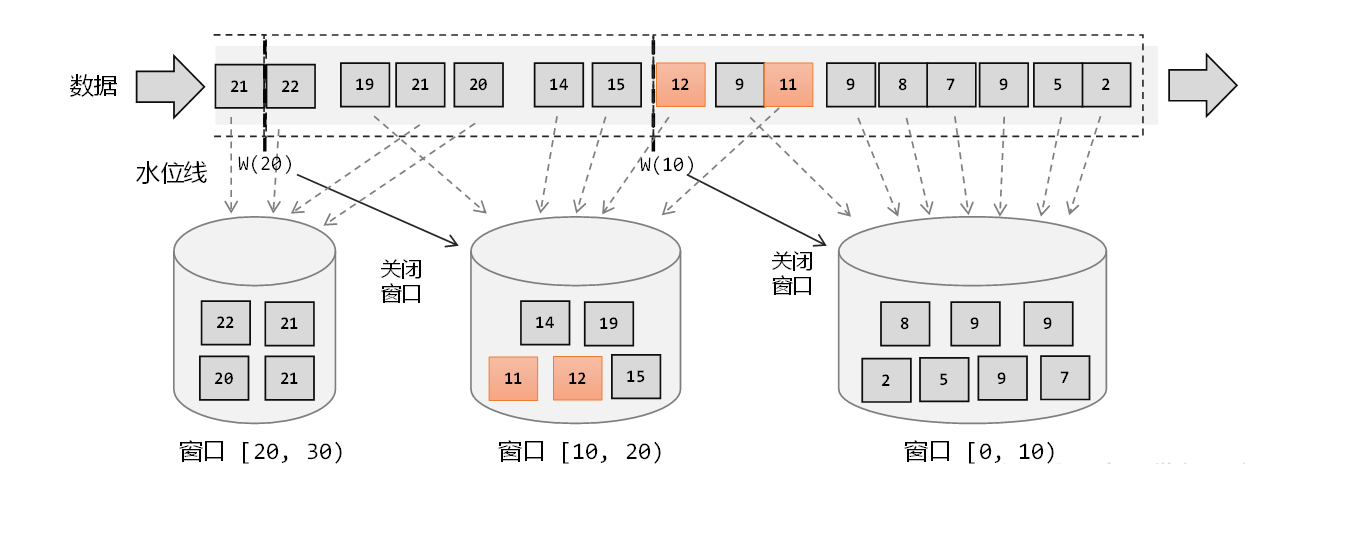
正确理解:在Flink中,窗口其实并不是一个“框”,应该把窗口理解成一个“桶”。在Flink中,窗口可以把流切割成有限大小的多个“存储桶” (bcket): 每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
且Flink 中的窗口并不是事先创建好的,而是动态创建的。当有落在窗口范围中的数据到达时才会创建对应的窗口。
例如需要将数据按照时间进行统计计算,就可以将数据按小时进行分桶,0点~1点放在一个桶中,1点~两点放到一个桶中。
窗口是由窗口分配器和窗口函数组成的。
1.2 窗口的分类
Flink 中除了最简单的时间窗口外,还可以使用各种不同类型的窗口来实现需求。
1.2.1 按照驱动(度量)类型分
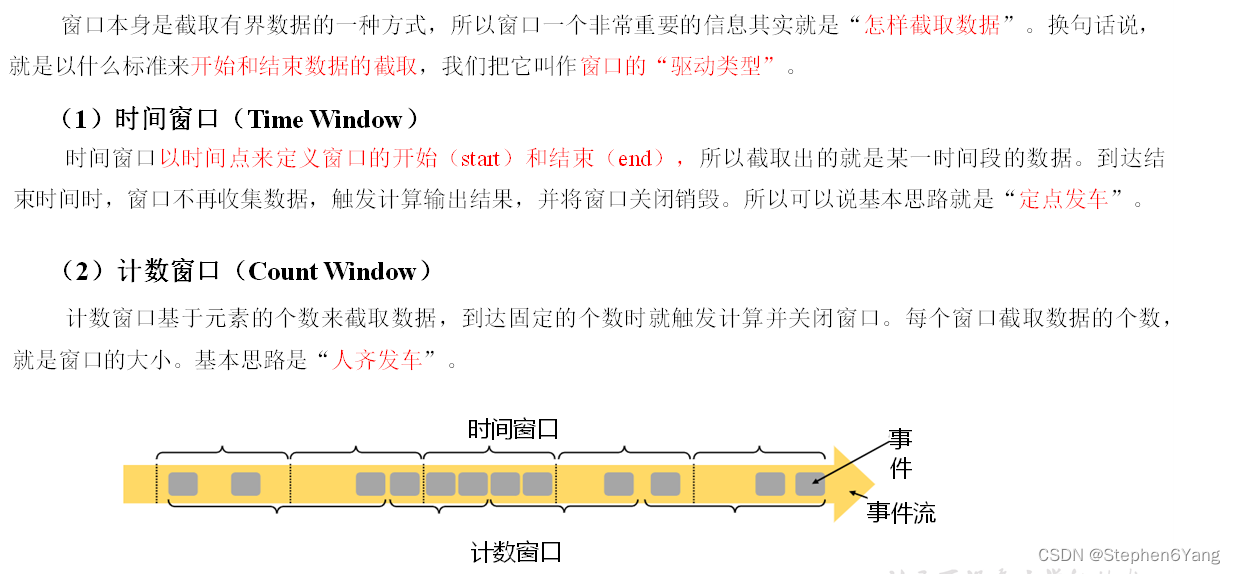
窗口其实截取有界流的一种方式,如何定义截取的开始时机和结束时机,这就叫做窗口的驱动类型。
(1) 时间窗口(Time Window)
时间窗口就是以时间点来定义窗口的开始和结束,截取出的就是某一时间段的数据。到达结束时间,窗口则不再继续收集数据,触发计算输出结果,并将窗口销毁关闭。
时间窗口并不是以第一条数据来的时间+窗口长度为一个窗口,而且整数向下取整。
例如:
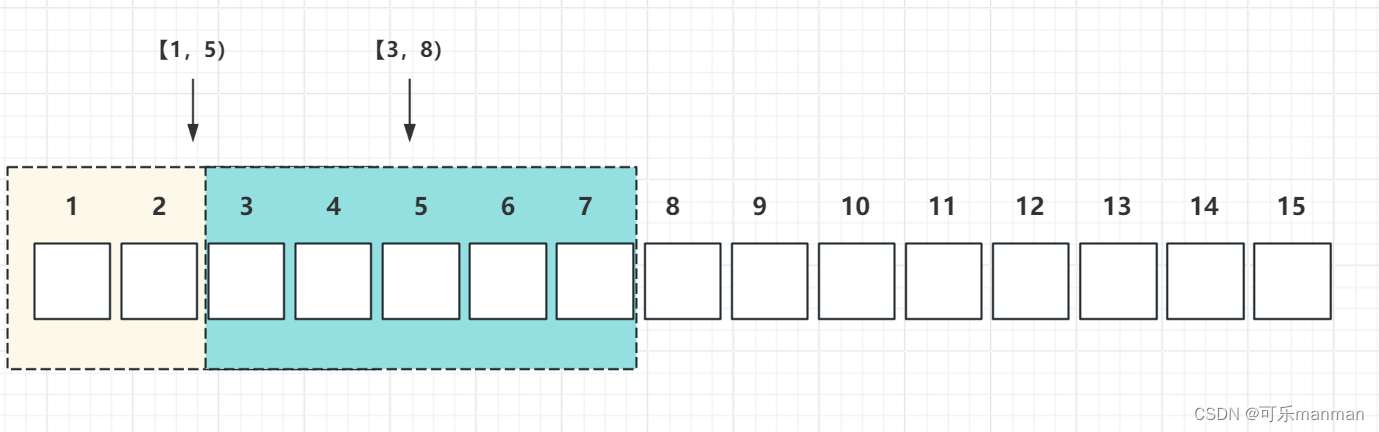
一个基于时间的窗口,且窗口长度为7。
1分12秒一条数据达到,其实这条数据不属于 [ 12 ,19 ),而是属于 [ 10,20 )。
(2) 计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。
1.2.2 按照窗口分配数据的规则分类
根据分配数据的规则,窗口的具体实现可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
(1) 滚动窗口(Tumbling Window)
滚动窗口有固定的大小,是一种对数据的“均匀切分”的划分方式。窗口间不会重叠,也不会产生间隔,每个数据只会属于一个窗口。
滚动窗口可以根据时间和数据个数定义,需要的参数就是窗口大小(window size)。例如可以定义长度为1小时的滚动窗口,则每小时会进行一次统计,也可以定义一个长度为10的滚动计数窗口,则每10个数会进行一次统计。
应用:对每个时间段做聚合统计。
(2) 滑动窗口(Sliding Window)
滑动窗口的大小也是固定的,当窗口间并不一定是无缝连接的,可以错开一定的位置。
定义滑动窗口的参数有两个:除去窗口大小 (window size)之外,还有一个“滑动步长”(window slide)它其实就代表了窗口计算的频率。窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。
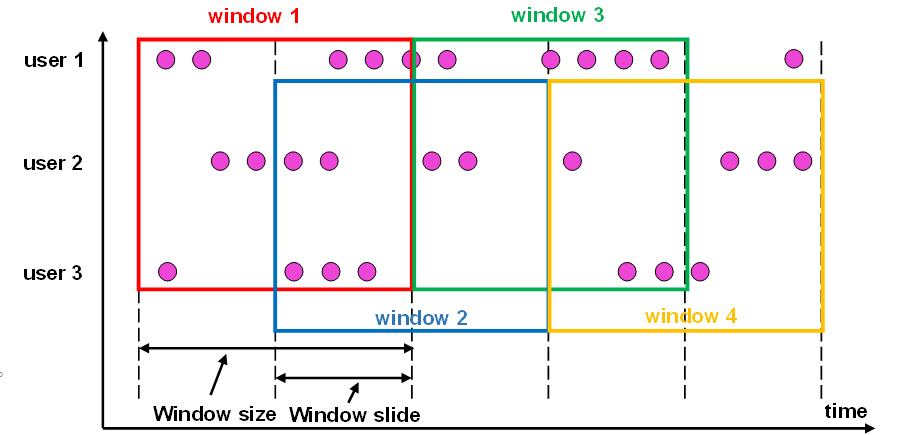
当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数就由窗口大小和滑动步长的比值 (size/slide) 来决定。
滚动窗口也可以看作是一种特殊的滑动窗口一-窗口大小等于滑动步长 (size =slide)。
滑动窗口适合计算结果更新频率非常高的场景。
同样的,滑动窗口也支持以时间和数据个数来定义。
(3) 会话窗口(Session Window)
会话窗口,是基于“会话” (session) 来来对数据进行分组的。会话窗口只能基于时间来定义。
会话窗口中,最重要的参数就是会话的超时时间,也就是两个会话窗口之间的最小距离。如果两条数据达到的间隔小于定义的会话超时时间,那为保持会话,数据都属于同一个窗口;如果两条数据达到的间隔大于定义的会话超时时间,则为两个不同的会话,数据也就不在一个窗口。
(4) 全局窗口(Global Window)
这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中。这种窗口没有结束的时候,
默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”
(Tiigger)
1.2.3 四种时间窗口的演示
(1) 滚动窗口
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1、指定 窗口分配器 使用滚动窗口,窗口长度为10s,每10s的数据在一个窗口内
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
SingleOutputStreamOperator<String> process = sensorWs.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s The key for which this window is evaluated. 该窗口的 Key
* @param context The context in which the window is being evaluated. 窗口上下文
* @param elements The elements in the window being evaluated. 窗口中所有的数据
* @param out A collector for emitting elements. 采集器
* @throws Exception
*/
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
});
process.print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5
s1,6,6
结果:

(2) 滑动窗口
// 2、 滑动窗口,窗口长度为10s,滑动步长为 5s (窗口重叠 5s)
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)));
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5
s1,6,6
s1,7,7
输出:

(3) 会话窗口
// 3、会话窗口,会话超时时间为 10s
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
// 等待10s
s1,4,4
s1,5,5
s1,6,6
// 等待十秒
s1,7,7
输出:

(4) 动态会话窗口
// 4、动态会话窗口,可以动态指定会话超时时间
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(ProcessingTimeSessionWindows.withDynamicGap(
new SessionWindowTimeGapExtractor<WaterSensor>() {
@Override
public long extract(WaterSensor element) {
// 根据数据中的属性自定义指定会话超时间,会话单位是毫秒
// 以数据中的 vc * 1000 毫秒为会话超时间
return element.getVc() * 1000;
}
}
));1.2.4 两种计数窗口的演示
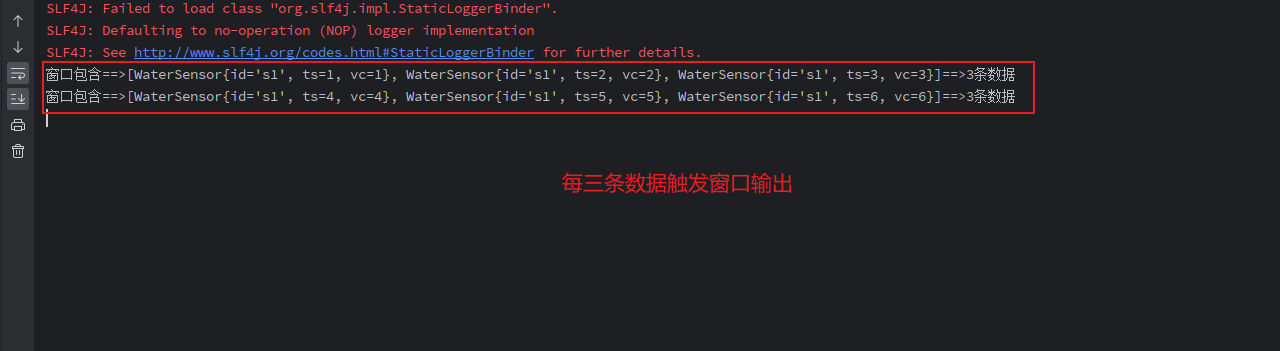
(1) 滚动窗口
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 计数窗口
// 滚动窗口:每3条为一个窗口
WindowedStream<WaterSensor, String, GlobalWindow> sensorWs = sensorKS.countWindow(3);
SingleOutputStreamOperator<String> process = sensorWs.process(new ProcessWindowFunction<WaterSensor, String, String, GlobalWindow>() {
@Override
public void process(String s, ProcessWindowFunction<WaterSensor, String, String, GlobalWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
out.collect("窗口包含==>" + elements.toString() + "==>" + elements.spliterator().estimateSize() + "条数据");
}
});
process.print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3,
s1,4,4
s1,5,5
s1,6,6
输出:
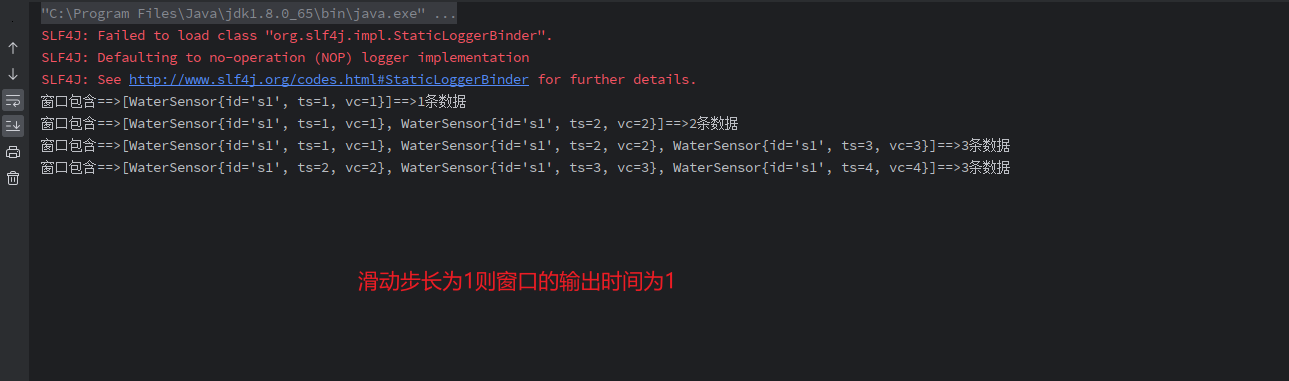
(2) 滑动窗口
// 滑动窗口:窗口长度为3,滑动步长为1
WindowedStream<WaterSensor, String, GlobalWindow> sensorWs = sensorKS
.countWindow(3,1);输入:
[root@VM-55-24-centos ~]# nc -lk 8877
s1,1,1
s1,2,2
s1,3,3
s1,4,4
输出:
1.3 窗口API概览
(1) 按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先要确定数据流有没有进行 KeyBy 操作。
(1.1) 非按键分区(Non-Keyed Windows)
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了1。
基于DataStream调用.windowAll()定义窗口
stream.windowAll(...)(1.2) 按键分区窗口(Keyed Windows)
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的处理。所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
例如有 Key分别为红、黄、蓝的三种数据,需要按照时间分桶,则在1点~2点之间,红、黄、蓝会各自单独创建一个桶,桶与桶之间互不干扰,到下一个时间点,则会各自创建对应的桶。
需要先对DataStream调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...).window(...)
(2) 代码中窗口API的调用
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种
1.4 窗口分配器
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。所以可以说,窗口分配器其实就是在指定窗口的类型。
窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
窗口分配器就是根据是否进行了 KeyBy 操作,直接调用 window() / windowAll()。
... sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1.1 基于时间的窗口
// 滚动窗口,窗口长度为10s,每10s的数据在一个窗口内
sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 滑动窗口,窗口长度为10s,滑动步长为2s(窗口重叠2s)
sensorKS.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(2)));
// 会话窗口,会话间隔为10s
sensorKS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));
// 1.2 基于计数的窗口
// 滚动窗口,窗口长度为10个元素(每10个元素在一个窗口内)
sensorKS.countWindow(10);
// 滑动窗口,窗口长度为10个元素,滑动步长为2个元素
sensorKS.countWindow(10,2);
// 全局窗口,计数窗口的底层实现,自定义窗口时使用
sensorKS.window(GlobalWindows.create()); 1.5 窗口函数
第一步用窗口分配器将数据收集在窗口中后,则需要定义窗口函数对窗口收集的数据进行计算操作。
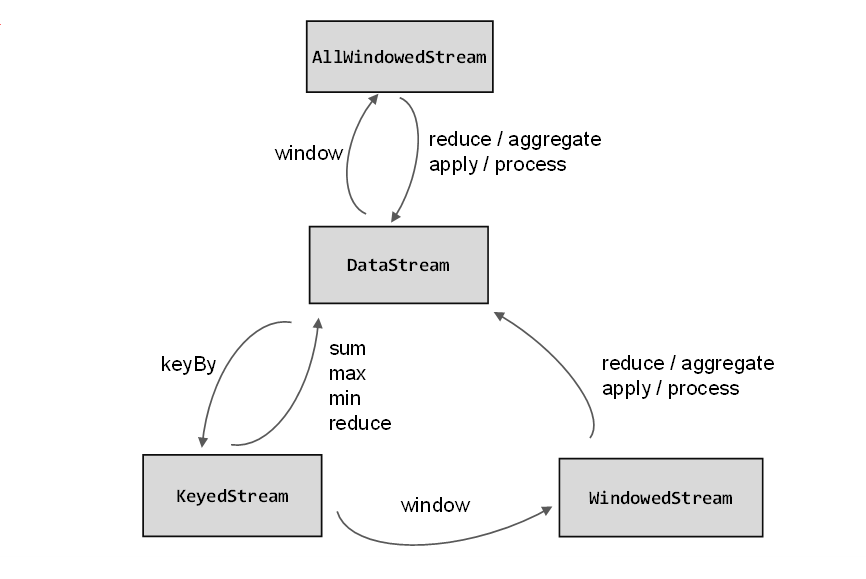
窗口函数根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
1.5.1 增量聚合函数(ReduceFunction / AggregateFunction)
窗口将数据收集起来,最基本的处理操作就是进行聚合。每来一条数据,就在之前的结果上聚合一次,这就是“增量聚合”。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
(1) 规约函数(ReduceFunction)
需求案例:读取 Socket 的水位数据,计算每30s中的VC 累加和 , 并在窗口触发时输出结果。
/**
* 窗口函数:增量聚合 Reduce
*/
public class WindowReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1、指定 窗口分配器 使用滚动窗口,窗口长度为30s,每30s的数据在一个窗口内
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(30)));
// 2、窗口函数: 增量聚合 Reduce
/**
* 窗口函数的 Reduce :
* 1、相同的 Key 的第一条数据来的时候,不会调用 Reduce 方法
* 2、增量聚合的意思是:数据来一条就基于上次的结果计算一次,但不会输出
* 3、在窗口触发(结束)时,才会输出窗口的最终计算结果
*/
SingleOutputStreamOperator<WaterSensor> reduce = sensorWs.reduce(new ReduceFunction<WaterSensor>() {
@Override
public WaterSensor reduce(WaterSensor v1, WaterSensor v2) throws Exception {
System.out.println("调用 Reduce 方法:上一条数据:" + v1 + "-----当前数据:" + v2);
return new WaterSensor(v1.getId(), v1.getTs(), v1.getVc() + v2.getVc());
}
});
// 输出窗口计算结果
reduce.print();
env.execute();
}
}输入:
/**
* 30s内输入完成
*
* 因为使用的KeyBy,相同Key才会被分配到一个窗口中,所以id要一致
*
*/
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5
s1,6,6
结果:
调用 Reduce 方法:上一条数据:WaterSensor{id='s1', ts=1, vc=1}-----当前数据:WaterSensor{id='s1', ts=2, vc=2}
调用 Reduce 方法:上一条数据:WaterSensor{id='s1', ts=1, vc=3}-----当前数据:WaterSensor{id='s1', ts=3, vc=3}
调用 Reduce 方法:上一条数据:WaterSensor{id='s1', ts=1, vc=6}-----当前数据:WaterSensor{id='s1', ts=4, vc=4}
调用 Reduce 方法:上一条数据:WaterSensor{id='s1', ts=1, vc=10}-----当前数据:WaterSensor{id='s1', ts=5, vc=5}
调用 Reduce 方法:上一条数据:WaterSensor{id='s1', ts=1, vc=15}-----当前数据:WaterSensor{id='s1', ts=6, vc=6}
WaterSensor{id='s1', ts=1, vc=21}Reduce小结:
相同的 Key 的第一条数据来的时候,不会调用 Reduce 方法
增量聚合的意思是:数据来一条就基于上次的结果计算一次,但不会输出
在窗口触发(结束)时,才会输出窗口的最终计算结果
(2) 聚合函数(AggregateFunction)
ReduceFunction可以解决大多数归约聚合的问题,而AggregateFunction可以看作是ReduceFunction的通用版本,所以AggregateFunction使用更为灵活,在ReduceFunction中,输入类型、中间状态存储类型、输出类型都必要保持类型一致,而AggregateFunction有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT),三种类型都可以不同。
与上面需求一致:
/**
* 窗口函数:增量聚合 Aggregate
*/
public class WindowAggregateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1、指定 窗口分配器 使用滚动窗口,窗口长度为30s,每30s的数据在一个窗口内
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(30)));
// 2、窗口函数: 增量聚合 Aggregate
/**
* 1、本窗口的第一条数据达到时,创建窗口、初始化累加器
* 2、增量聚合:数据来一条计算一次(调用add方法)
* 3、窗口输出时调用一次getResult方法
* 4、输入类型、累加器、输出类型 三者可以类型不一致
*/
SingleOutputStreamOperator<String> aggregate = sensorWs.aggregate(new AggregateFunction<WaterSensor, Integer, String>() { // 输入类型, 累加器类型(存储中间计算值), 输出类型
/**
* 初始化累加器
*/
@Override
public Integer createAccumulator() {
System.out.println("初始化累加器");
return 0;
}
/**
* 具体的聚合逻辑
*/
@Override
public Integer add(WaterSensor waterSensor, Integer integer) {
System.out.println("调用add方法 当前数据:" + waterSensor);
return integer + waterSensor.getVc();
}
/**
* 窗口触发时获取最终计算结果并输出
*/
@Override
public String getResult(Integer integer) {
System.out.println("调用getResult方法");
return integer.toString();
}
@Override
public Integer merge(Integer integer, Integer acc1) {
// 只有会话窗口才会调用
System.out.println("调用merge方法");
return null;
}
});
// 输出窗口计算结果
aggregate.print();
env.execute();
}
}输入:
/**
* 30s内输入完成
*/
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5
s1,6,6
s1,7,7
输出结果:
初始化累加器
调用add方法 当前数据:WaterSensor{id='s1', ts=1, vc=1}
调用add方法 当前数据:WaterSensor{id='s1', ts=2, vc=2}
调用add方法 当前数据:WaterSensor{id='s1', ts=3, vc=3}
调用add方法 当前数据:WaterSensor{id='s1', ts=4, vc=4}
调用add方法 当前数据:WaterSensor{id='s1', ts=5, vc=5}
调用add方法 当前数据:WaterSensor{id='s1', ts=6, vc=6}
调用add方法 当前数据:WaterSensor{id='s1', ts=7, vc=7}
调用getResult方法
28Aggregate 小结:
1.三个需实现的接口,一个会话窗口需实现的接口
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
merge():合并两个累加器,并将合并后的状态作为一个累加器返回。(会话窗口使用)
getResult():从累加器中提取聚合的输出结果。
add():将输入的元素添加到累加器中。
2.本窗口的第一条数据达到时,创建窗口、初始化累加器
3.增量聚合:数据来一条计算一次(调用add方法)
4.窗口输出时调用一次getResult方法
5.输入类型、累加器、输出类型 三者可以类型不一致
1.5.2 全窗口函数(full window functions)
全窗口函数与增量聚合函数不同,增量聚合函数是数据来一条处理一条,而全窗口函数是将数据全部收集起来,等到窗口触发时才统一计算。并且全窗口函数的可以获取更多的信息,例如窗口的上下文信息(比如窗口的结束时间)。
在Flink中,全窗口函数也有两种:WindowFunction(不推荐)和ProcessWindowFunction。
(1) 窗口函数(WindowFunction)
WindowFunction 是老版本的通用窗口函数接口,但是没有提供更多的信息,也没有提供高级的功能,所以不推荐使用,可以被ProcessWindowFunction全覆盖。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
(2) 处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction是Window API中最底层的通用窗口函数接口。除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得ProcessWindowFunction更加灵活、功能更加丰富,其实就是一个增强版的WindowFunction。
/**
* 窗口函数:全窗口函数 Process
*/
public class WindowProcessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1、指定 窗口分配器 使用滚动窗口,窗口长度为10s,每10s的数据在一个窗口内
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(30)));
SingleOutputStreamOperator<String> process = sensorWs.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s The key for which this window is evaluated. 该窗口的 Key
* @param context The context in which the window is being evaluated. 窗口上下文
* @param elements The elements in the window being evaluated. 窗口中所有的数据
* @param out A collector for emitting elements. 采集器
* @throws Exception
*/
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
});
process.print();
env.execute();
}输入:
[root@VM-55-27-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5输出:
窗口的开始时间:2023-11-18 11:13:30 000--窗口的结束时间:2023-11-18 11:13:00 000
--key 为s1的窗口数据包含
[
[WaterSensor{id='s1', ts=1, vc=1},
WaterSensor{id='s1', ts=2, vc=2},
WaterSensor{id='s1', ts=3, vc=3},
WaterSensor{id='s1', ts=4, vc=4},
WaterSensor{id='s1', ts=5, vc=5}]
]
5条数据
1.5.3 增量聚合和全窗口函数的结合使用
增量函数的优点是数据来一条处理一条,只存储中间计算值,所以占用的空间少。而全窗口需要储存窗口内的所有数据,最后再进行统一计算,但可以上下文获取到更多的窗口信息。在实际开发中,则可以结合这两者的优点。
在调用WindowedStream的.reduce()和.aggregate()方法时,不止可以传入一个ReduceFunction或AggregateFunction进行增量聚合,其实还可以传入第二个参数:一个全窗口函数,可以是WindowFunction或者ProcessWindowFunction。
public class WindowAggregateAndProcessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(WaterSensor::getId);
// 1、指定 窗口分配器 使用滚动窗口,窗口长度为10s,每10s的数据在一个窗口内
WindowedStream<WaterSensor, String, TimeWindow> sensorWs = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(30)));
/**
* 增量聚合函数 与 全窗口函数 一起使用
*/
SingleOutputStreamOperator<String> aggregate = sensorWs.aggregate(
new MyAggregateFunc(),
new MyProcessFunc()
);
// 输出窗口计算结果
aggregate.print();
env.execute();
}
private static class MyAggregateFunc implements AggregateFunction<WaterSensor, Integer, String>{
@Override
public Integer createAccumulator() {
System.out.println("初始化累加器");
return 0;
}
@Override
public Integer add(WaterSensor waterSensor, Integer integer) {
System.out.println("调用add方法 当前数据:" + waterSensor);
return integer + waterSensor.getVc();
}
@Override
public String getResult(Integer integer) {
System.out.println("调用getResult方法");
return integer.toString();
}
@Override
public Integer merge(Integer integer, Integer acc1) {
System.out.println("调用merge方法");
return null;
}
}
private static class MyProcessFunc extends ProcessWindowFunction<String,String,String, TimeWindow> {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含" + elements + " " + count + "条数据");
}
}
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,5,5
输出:
初始化累加器
调用add方法 当前数据:WaterSensor{id='s1', ts=1, vc=1}
调用add方法 当前数据:WaterSensor{id='s1', ts=2, vc=2}
调用add方法 当前数据:WaterSensor{id='s1', ts=3, vc=3}
调用add方法 当前数据:WaterSensor{id='s1', ts=4, vc=4}
调用add方法 当前数据:WaterSensor{id='s1', ts=5, vc=5}
调用getResult方法
窗口的开始时间:2023-11-18 11:51:30 000--窗口的结束时间:2023-11-18 11:52:00 000 --key 为s1的窗口数据包含[15] 1条数据增量聚合和全窗口函数的结合使用的效果:增量聚合结束后将计算结果(只有一条)发给全窗口函数进行处理。
二.时间语义
2.1 Flink中的时间语义
数据在网络传输中会存在一定的延迟,也意味着数据从生产到Flink真正处理的时间也存在延迟。数据被生产的时刻则被称为“事件时间”,数据被Flink真正处理的时刻被称为“处理时间”,到底以哪一种时间作为衡量标准,就是所谓的“时间语义”。
在实际应用中,事件时间往往会被作为参数传递,例如MySQL数据表的 create_time 字段,或者是前端传来的时间戳。使用事件时间更能保证数据的准确性。
从 Flink 1.12 版本开始,事件时间为默认的时间语义。
三. 水位线(Watermark)
3.1事件时间和窗口
在窗口的处理过程中,我们可以基于数据的时间戳,自定义一个“逻辑时钟”。这个时钟代表的是数据的时间进展,而不会随着系统时间而自动流逝,而是靠新数据的时间戳来推动的,且只会向前推进。
这样的好处在于,在 Flink 的计算过程中可以完全不依赖系统时间,不论何时进行统计处理,都可以靠着逻辑时钟保证窗口计算的正确性。
3.2 什么是水位线
在Flink中,用来衡量事件时间进展的标记,就被称作“水位线”(Watermark)。
具体实现上,水位线其实就是一个时间戳,作为数据流的标记,用来指示当前的事件时间,当某个数据到来之后,就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
水位线是会被 Flink 存储的。
(1) 有序流中的水位线
1、理想状态(数据量小):数据可以按照生成顺序进入流中,每条数据产生一个水位线。
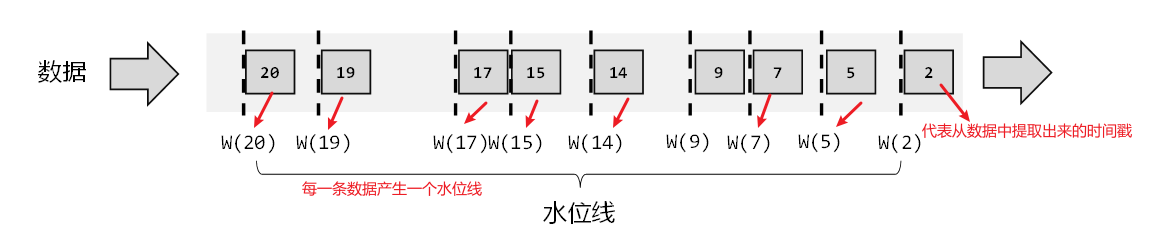
2、实际应用中,如果当前数据量非常大,数据间的时间差非常小, 如果也按照每条数据产生一个水位线则会非常影响效率。所以为了提高效率,一般可以每隔一段时间生成一个水位线。

(2) 乱序流中的水位线
在分布式系统中,由于网络传输的不确定性,可能导致数据达到的时间并不是有序的,这就是“乱序数据”。

1、乱序流+数据量小
还是靠数据来驱动,来一条数据就提取其时间戳作为水位线插入,不过现在是乱序数据,在生成水位线前,需要先判断当前数据的时间戳是否大于之前的水位线,如果大于才生成新的水位线,否则就不生成新的水位线。也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。

2、乱序流+数据量大
数据量大则可以周期性的生成水位线来提升效率。并且保存之前数据的最大时间戳,需要插入水位线时,可以将这个最大时间戳作为水位线插入。

3、乱序流+迟到数据
迟到数据指的是,例如有一个第9秒生产的数据,但是第11秒才到达Flink,那么则会落到[ 10 , 20 ) 的窗口中。
我们无法正确处理“迟到”的数据。为了让窗口能够正确收集到迟到的数据,我们也可以等上一段时间,比如2秒;也就是用当前已有数据的最大时间戳减去2秒,就是要插入的水位线的时间戳。这样的话,9秒的数据到来之后,事件时钟不会直接推进到9秒,而是进展到了7秒。必须等到11秒的数据到来之后,事件时钟才会进展到9秒,这时迟到数据也都已收集齐,0~9秒的窗口就可以正确计算结果了。

现在我们知道,水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要
3.3 水位线和窗口的工作原理
在 Flink 中,窗口其实并不是一个固定位置的框,而是理解为一个“桶”,在Flink中,窗口可以把流切割成有限大小的多个“存储桶”(对应窗口);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
3.4 生成水位线
3.4.1 生成水位线的总体原则
完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。不过如果要保证绝对正确,就必须等足够长的时间,这会带来更高的延迟。
如果希望处理更快、实时性更强,则可以将水位线延迟设置得低些,不过这样会导致很多迟到数据被窗口遗漏,计算结果不准确;如果计算结果的准确性有要求,则可以将水位线延迟设置得高些,这样会导致处理延迟增加。
所以Flink中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。
3.4.2 水位线生成策略
在 Flink 的 DataStream API 中,有一个单独用于生成水位线的方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间。
DataStream<Event> stream = env.addSource(new DataSource());
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(<WatermarkStrategy>);
说明:WatermarkStrategy作为参数,这就是所谓的“水位线生成策略”。WatermarkStrategy是一个接口,该接口中包含了一个“时间戳分配器”TimestampAssigner和一个“水位线生成器”WatermarkGenerator。
3.4.3 Flink内置水位线
(1) 有序流(时间戳单调递增)中内置水位线设置
对于有序流,主要特点就是时间戳单调增长,而不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// ***定义 WaterMark 策略
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
// 单调递增的事件时间,没有延迟时间
.<WaterSensor>forMonotonousTimestamps()
// 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
/**
*
* @param waterSensor 当前数据
* @param l
* @return
*/
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
System.out.println("当前数据:" + waterSensor + " ==> l:" + l);
// 从数据中返回的时间戳(毫秒))
return waterSensor.getTs() * 1000L;
}
});
// ***指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy);
sensorWithWaterMark
.keyBy(WaterSensor::getId)
// ***使用事件时间的窗口,而非处理时间的窗口 10s的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
}).print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s1,4,4
s1,7,7
s1,9,9
s1,10,10
s1,15,15
s1,20,20
输出:
当前数据:WaterSensor{id='s1', ts=1, vc=1} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=2, vc=2} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=3, vc=3} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=4, vc=4} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=7, vc=7} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=9, vc=9} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=10, vc=10} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=2, vc=2}, WaterSensor{id='s1', ts=3, vc=3}, WaterSensor{id='s1', ts=4, vc=4}, WaterSensor{id='s1', ts=7, vc=7}, WaterSensor{id='s1', ts=9, vc=9}]] 6条数据
当前数据:WaterSensor{id='s1', ts=15, vc=15} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=20, vc=20} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:10 000--窗口的结束时间:1970-01-01 08:00:20 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=10, vc=10}, WaterSensor{id='s1', ts=15, vc=15}]] 2条数据有序流的水位线设置非常简单,就是把数据中表示事件时间的属性返回。
(2) 乱序流中内置水位线设置
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟时间的结果再-1。调用WatermarkStrategy. forBoundedOutOfOrderness()传入最大延迟时间。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// ***定义 WaterMark 策略
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
// 乱序的事件时间,需设置最大等待时间(当前窗口水位线 = 当前窗口最大事件时间 - 等待时间)
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
// 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
/**
*
* @param waterSensor 当前数据
* @param l
* @return
*/
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
System.out.println("当前数据:" + waterSensor + " ==> l:" + l);
// 返回的时间戳(毫秒))
return waterSensor.getTs() * 1000L;
}
});
// ***指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy);
sensorWithWaterMark
.keyBy(WaterSensor::getId)
// ***使用事件时间的窗口,而非处理时间的窗口 10s的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
}).print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1 // 水位线 = -2
s1,2,2 // 水位线 = -1
s1,6,6 // 水位线 = 3
s1,8,8 // 水位线 = 5
s1,5,5 // 水位线 = 2
s1,9,9 // 水位线 = 6
s1,10,10 // 水位线 = 7
s1,7,7 // 水位线 = 4
s1,12,12 // 水位线 = 9
s1,3,3 // 水位线 = 0
s1,13,13 // 水位线 = 10 窗口触发关闭
输出:
当前数据:WaterSensor{id='s1', ts=1, vc=1} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=2, vc=2} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=6, vc=6} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=8, vc=8} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=5, vc=5} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=9, vc=9} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=10, vc=10} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=7, vc=7} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=12, vc=12} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=3, vc=3} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=13, vc=13} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=2, vc=2}, WaterSensor{id='s1', ts=6, vc=6}, WaterSensor{id='s1', ts=8, vc=8}, WaterSensor{id='s1', ts=5, vc=5}, WaterSensor{id='s1', ts=9, vc=9}, WaterSensor{id='s1', ts=7, vc=7}, WaterSensor{id='s1', ts=3, vc=3}]] 8条数据(3) 内置水位线生成原理
- 都是周期性生成水位线的,默认200ms
- 有序流水位线生成:当前最大事件时间 - 1ms
- 乱序流水位线生成:当前最大事件时间 - 最大等待时间 - 1ms
- 有序流就是一种特殊的乱序流,最大等待时间为0
3.4.4 自定义水位线生成器
(1) 周期性水位线生成器(Periodic Generator)
需要自定义周期性水位线生成器则可以实现WatermarkGenerator<T>中的onEvent 记录事件时间、onPeriodicEmit 周期性生成水位线。
public class MyPeriodWatermarkGenerator<T> implements WatermarkGenerator<T> {
private Long maxTs; // 当前最大时间戳
private Long delayTime; // 等待时间
public MyPeriodWatermarkGenerator(Long delayTime) {
this.delayTime = delayTime;
maxTs = Long.MIN_VALUE - this.delayTime - 1 ;
}
/**
* 每条数据来都会调用一次该方法。主要用于记录、更新当前最大的时间戳
* @param t
* @param l
* @param watermarkOutput
*/
@Override
public void onEvent(T t, long l, WatermarkOutput watermarkOutput) {
maxTs = Math.max(maxTs , l);
}
/**
* 周期性调用,主要用于周期性生成 Watermark
* @param watermarkOutput
*/
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
watermarkOutput.emitWatermark(new Watermark(maxTs));
}
}在选择水位线生成器时,则可以使用这个自定义水位线生成器。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.addSource(new DataSource())
.map(new MyMapFunctionImpl());
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
.<WaterSensor>forGenerator(new WatermarkStrategy<WaterSensor>() {
@Override
public WatermarkGenerator<WaterSensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
// 使用自定义水位生成器并设置等待时间
return new MyPeriodWatermarkGenerator<>(3000l);
}
})
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
// 事件时间提取器
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
return waterSensor.getTs() * 1000L;
}
});(2) 断点式水位线生成器(Punctuated Generator)
断点式生成器会不停地检测onEvent()中的事件,当发现带有水位线信息的事件时,就立即生成水位线。我们把生成水位线的逻辑写在onEvent方法当中即可。
/**
* 断点式水位线
*/
public class MyPuntuatedWatermarkGenerator<T> implements WatermarkGenerator<T> {
private Long maxTs; // 当前最大时间戳
private Long delayTime; // 等待时间
public MyPuntuatedWatermarkGenerator(Long delayTime) {
this.delayTime = delayTime;
maxTs = Long.MIN_VALUE - this.delayTime - 1 ;
}
/**
* 每条数据来都会调用一次该方法。主要用于记录、更新当前最大的时间戳,并且立即更新当前水位线
* @param t
* @param l
* @param watermarkOutput
*/
@Override
public void onEvent(T t, long l, WatermarkOutput watermarkOutput) {
maxTs = Math.max(maxTs , l);
watermarkOutput.emitWatermark(new Watermark(maxTs));
}
/**
* 周期性调用,断点式不需要
* @param watermarkOutput
*/
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
watermarkOutput.emitWatermark(new Watermark(maxTs));
}
}(3) 在数据源中生成水位线
我们可以直接在自定义的数据源中抽取事件时间,然后生成水位线。这里要注意的是,在自定义数据源中发送了水位线以后,就不能再在程序中使用assignTimestampsAndWatermarks方法来生成水位线了。在自定义数据源中生成水位线和在程序中使用assignTimestampsAndWatermarks方法生成水位线二者只能取其一。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("input/words.txt")).build();
// 在数据源中发送水位线 乱序流-延迟3s
env.fromSource(fileSource,WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)),"file").print();
env.execute();
}3.5 水位线的传递
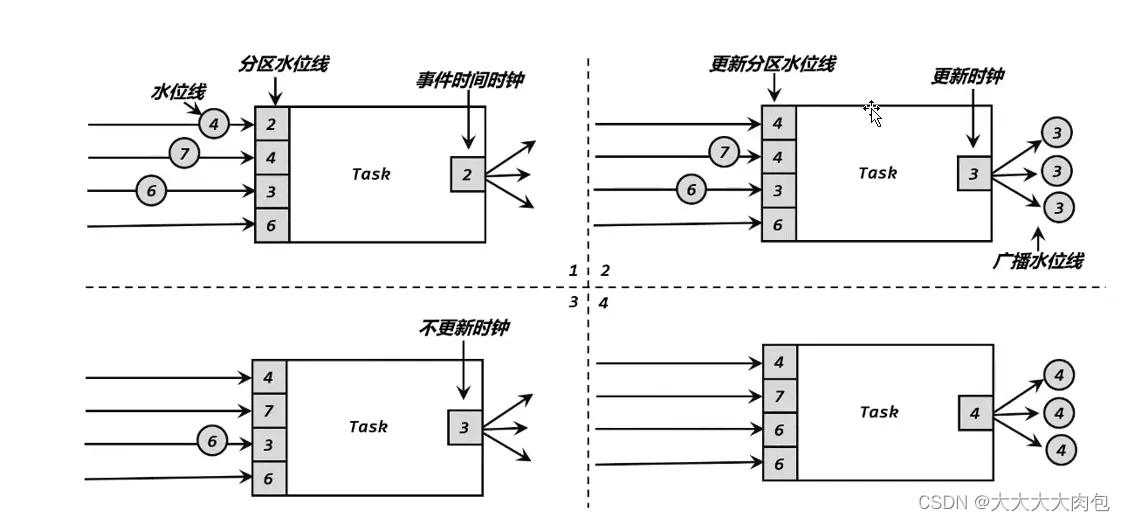
水位线并不能代表整个程序的处理进度,而是只能代表某个子任务的处理进度,因为水位线会随着数据往下游传递,也就是说不同节点的处理进度是不一样的。
在多并行度下的流处理中,上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。而当一个任务接收到多个上游并行任务传递来的水位线时,会以最小的那个作为当前任务的事件时钟,向下游传递。
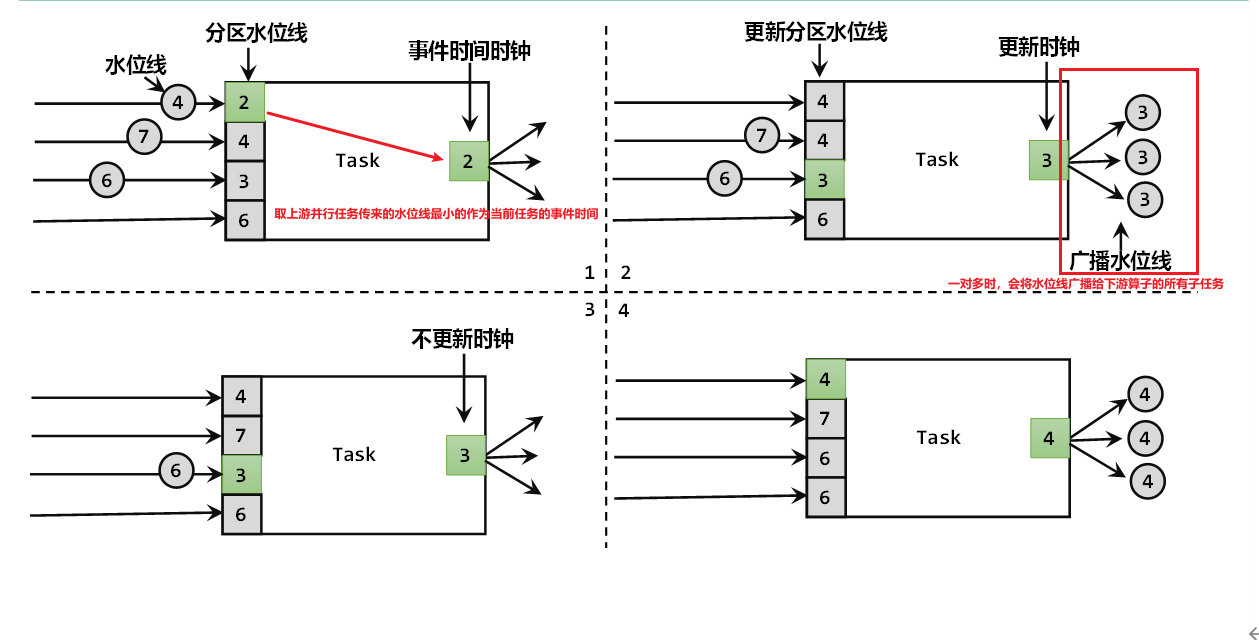
例子:并行度为2,算子链为:source -> map -> 水位线乱序 延迟3s -> 时间滚动窗口 大小为10
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// ***定义 WaterMark 策略
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
// 乱序的事件时间,需设置最大等待时间(当前窗口水位线 = 当前窗口最大事件时间 - 等待时间)
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
// 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
/**
*
* @param waterSensor 当前数据
* @param l
* @return
*/
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
System.out.println("当前数据:" + waterSensor + " ==> l:" + l);
// 返回的时间戳(毫秒))
return waterSensor.getTs() * 1000L;
}
});
// ***指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy);
sensorWithWaterMark
.keyBy(WaterSensor::getId)
// ***使用事件时间的窗口,而非处理时间的窗口 10s的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
}).print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,5,5
s1,7,7
s1,9,9
s1,10,10
s1,11,11
s1,12,12
s1,13,13
s1,14,14
输出:
当前数据:WaterSensor{id='s1', ts=1, vc=1} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=2, vc=2} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=5, vc=5} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=7, vc=7} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=9, vc=9} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=10, vc=10} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=11, vc=11} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=12, vc=12} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=13, vc=13} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=14, vc=14} ==> l:-9223372036854775808
2> 窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=2, vc=2}, WaterSensor{id='s1', ts=5, vc=5}, WaterSensor{id='s1', ts=7, vc=7}, WaterSensor{id='s1', ts=9, vc=9}]] 5条数据
可以看到,在并行度为2下,水位线为10 (13-3) 时,并没有触发窗口输出,这就是因为在多并行度下,一个任务接收到多个上游并行任务传递来的水位线时,会以最小的那个作为当前任务的事件时钟,向下游传递。
分析:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1 // 水位线:-2
s1,2,2 // 水位线: -1,多并行度下,向下传递最小的水位线 -2
s1,5,5 // 水位线: 2, 多并行度下,向下传递最小的水位线 -1
s1,7,7 // 水位线: 4, 多并行度下,向下传递最小的水位线 2
s1,10,10 // 水位线: 7, 多并行度下,向下传递最小的水位线 4
s1,11,11 // 水位线: 8, 多并行度下,向下传递最小的水位线 7
s1,12,12 // 水位线: 9, 多并行度下,向下传递最小的水位线 8
s1,13,13 // 水位线: 10,多并行度下,向下传递最小的水位线 9
s1,14,14 // 水位线: 11,多并行度下,向下传递最小的水位线 10 触发[ 0 , 10 )窗口输出3.5.1 水位线的空闲等待
在多个上游并行任务中,如果有其中一个没有数据,由于当前Task是以最小的那个作为当前任务的事件时钟,就会导致当前Task的水位线无法推进,就可能导致窗口无法触发。这时候可以设置空闲等待。
例子:将数据以奇偶的规则放在不同的 KeyBy 分区,观察水位线推进
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// !并行度为2
env.setParallelism(2);
SingleOutputStreamOperator<Integer> socketDs = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
// 重分区:当前数据 % 下游算子并行度
.partitionCustom(new MyPartitioner(), r -> r)
// 将输入的字符串转为整型
.map(r -> Integer.parseInt(r))
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Integer>forMonotonousTimestamps() // 单调递增的事件时间
.withTimestampAssigner((r, ts) -> r * 1000l) // 水位线提取器,将数据*1000作为水位线
);
socketDs.keyBy( r -> r % 2) // 将数据奇偶划分,在两个不同的分区
.window(TumblingEventTimeWindows.of(Time.seconds(10))) // 开窗:十秒的滑动窗口
.process(new ProcessWindowFunction<Integer, String, Integer, TimeWindow>() {
@Override
public void process(Integer integer, ProcessWindowFunction<Integer, String, Integer, TimeWindow>.Context context, Iterable<Integer> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + integer + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
}).print();
env.execute();输入奇数:
[root@VM-55-24-centos ~]# nc -lk 1234
3
5
7
9
11
13
结果:控制台并无任何输出,也就意味着 [ 0 , 10 )窗口并没有被触发。
这是因为在多个上游并行任务中,当前task会以最小的那个作为当前任务的事件时钟,而将数据分为奇偶,则奇数在一个分区,偶数在一个分区,只输入奇数,那么另一个分区为空,就会导致当前水位线一直是 Long.MIN_VALUE ,从而无法正常推进水位线。
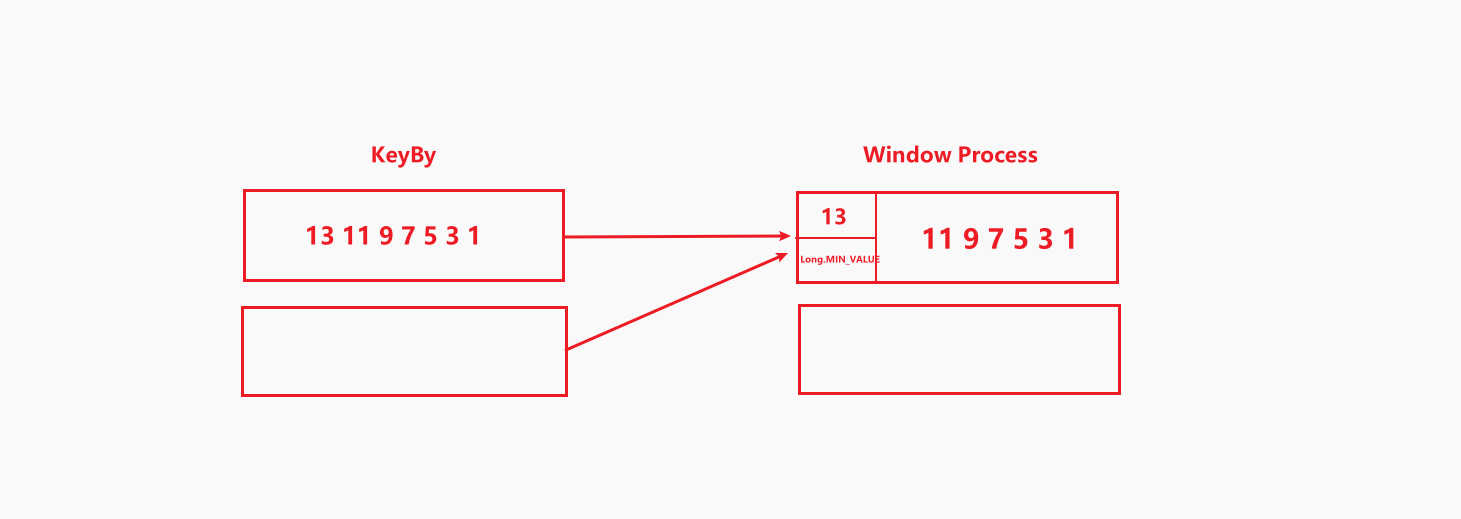
解决这个问题则可以通过设置空闲窗口时间withIdleness:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
// 设置空闲窗口时间为3s 窗口空闲3s则将空窗口的水位线标记为闲置
.withIdleness(Duration.ofSeconds(3));官方介绍:
There are two places in Flink applications where a WatermarkStrategy can be used: 1) directly on sources and 2) after non-source operation.
The first option is preferable, because it allows sources to exploit knowledge about shards/partitions/splits in the watermarking logic. Sources can usually then track watermarks at a finer level and the overall watermark produced by a source will be more accurate. Specifying a WatermarkStrategy directly on the source usually means you have to use a source specific interface/ Refer to Watermark Strategies and the Kafka Connector for how this works on a Kafka Connector and for more details about how per-partition watermarking works there.
The second option (setting a WatermarkStrategy after arbitrary operations) should only be used if you cannot set a strategy directly on the source:
如果其中一个输入分割/分区/碎片有一段时间不携带事件,这意味着水印生成器也不能获得任何新的信息来为水印做基础。我们称之为空闲输入或空闲源。这是一个问题,因为您的一些分区可能仍然带有事件。在这种情况下,水印将被保留,因为它被计算为所有不同的平行水印的最小值。
为了解决这个问题,你可以使用一个 WatermarkStrategy 来检测闲置状态并将输入标记为闲置。为此,WatermarkStrategy 提供了一个方便的帮助器:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
3.6 迟到数据的处理
迟到数据与乱序不同:乱序指的是数据到达Flink时的事件时间并不一定是顺序的;而迟到数据指的是当前数据的事件时间小于当前水位线,例如上一个窗口已经关闭了,属于上一个窗口的数据才达到。
3.6.1 推迟水位线推进
在水位线产生时,设置一个乱序容忍度(延迟时间),推迟系统时间的推进,保证窗口计算被延迟执行,为乱序的数据争取更多的时间进入窗口。
// 水位线生成延时10s
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));3.6.2 设置窗口延迟关闭
窗口的生命周期是:触发计算 -> 销毁/关闭窗口。设置窗口延迟时间其实就是延长窗口的销毁/关闭时间。
设置窗口延迟时间也就是允许数据迟到。当触发了窗口计算后,会先计算当前的结果,但是此时并不会关闭窗口。以后每来一条迟到数据,就触发一次这条数据所在窗口计算(增量计算)。直到wartermark 超过了窗口结束时间+推迟时间,此时窗口会真正关闭。
未设置窗口延迟关闭:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// ***定义 WaterMark 策略
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
// 乱序的事件时间,需设置最大等待时间(当前窗口水位线 = 当前窗口最大事件时间 - 等待时间)
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
// 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
/**
*
* @param waterSensor 当前数据
* @param l
* @return
*/
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
System.out.println("当前数据:" + waterSensor + " ==> l:" + l);
// 返回的时间戳(毫秒))
return waterSensor.getTs() * 1000L;
}
});
// ***指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy);
sensorWithWaterMark
.keyBy(WaterSensor::getId)
// ***使用事件时间的窗口,而非处理时间的窗口 10s的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
}).print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,5,5
s1,10,10
s1,12,12
s1,13,13
s1,3,3
输出:
当前数据:WaterSensor{id='s1', ts=1, vc=1} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=5, vc=5} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=10, vc=10} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=12, vc=12} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=13, vc=13} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=5, vc=5}]] 2条数据
当前数据:WaterSensor{id='s1', ts=3, vc=3} ==> l:-9223372036854775808可以看到,当 s1,13,13 到来时,触发了 [ 0 , 10 ) 的窗口关闭,随后来的 s1,3,3 并不会再被 [ 0 , 10 ) 窗口计算。
设置窗口延迟关闭:
sensorWithWaterMark
.keyBy(WaterSensor::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.seconds(3)) // 允许窗口延迟3s关闭输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,2,2
s1,8,8
s1,13,13
s1,14,14
s1,5,5
输出:
当前数据:WaterSensor{id='s1', ts=2, vc=2} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=8, vc=8} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=13, vc=13} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=2, vc=2}, WaterSensor{id='s1', ts=8, vc=8}]] 2条数据
当前数据:WaterSensor{id='s1', ts=14, vc=14} ==> l:-9223372036854775808
当前数据:WaterSensor{id='s1', ts=5, vc=5} ==> l:-9223372036854775808
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=2, vc=2}, WaterSensor{id='s1', ts=8, vc=8}, WaterSensor{id='s1', ts=5, vc=5}]] 3条数据
1.窗口允许迟到,则在关窗前,每一条迟到的数据达到,都会被窗口触发计算输出。
2.窗口真正被关闭后,迟到数据则无法再进入窗口。
3.6.3 使用侧流接收迟到的数据
利用之前的推迟水位线推进或设置窗口延迟关闭的方法,对于真正关窗的迟到数据都无法进行处理,Flink 提供了 sideOutputLateData() 将关窗后的迟到数据放入侧输出流。
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
.sideOutputLateData(lateWS)
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// ***定义 WaterMark 策略
WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy
// 乱序的事件时间,需设置最大等待时间(当前窗口水位线 = 当前窗口最大事件时间 - 等待时间)
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
// 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
/**
*
* @param waterSensor 当前数据
* @param l
* @return
*/
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
// 返回的时间戳(毫秒))
return waterSensor.getTs() * 1000L;
}
});
// ***指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy);
// ***指定侧输出流存放关窗后的迟到数据
OutputTag outputTag = new OutputTag("late-data", Types.POJO(WaterSensor.class));
SingleOutputStreamOperator<String> process = sensorWithWaterMark
.keyBy(WaterSensor::getId)
// ***使用事件时间的窗口,而非处理时间的窗口 10s的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.seconds(3)) // 允许窗口延迟3s关闭
.sideOutputLateData(outputTag)
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s,
ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss SSS");
long count = elements.spliterator().estimateSize();
out.collect("窗口的开始时间:" + windowStart + "--窗口的结束时间:" + windowEnd + " --key 为" + s + "的窗口数据包含[" + elements.toString() + "] " + count + "条数据");
}
});
// 获取侧输出流
process.getSideOutput(outputTag).printToErr("测输出流中的迟到数据" + outputTag.getTypeInfo());
process.print();
env.execute();
}输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,5,5
s1,10,10
s1,9,9
s1,13,13
s1,15,15
s1,16,16
s1,8,8
s1.12.12
输出:
窗口的开始时间:1970-01-01 08:00:00 000--窗口的结束时间:1970-01-01 08:00:10 000 --key 为s1的窗口数据包含[[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=5, vc=5}, WaterSensor{id='s1', ts=9, vc=9}]] 3条数据
·测输出流中的迟到数据PojoType<com.lc.bean.WaterSensor, fields = [id: String, ts: Long, vc: Integer]>> WaterSensor{id='s1', ts=8, vc=8}
·测输出流中的迟到数据PojoType<com.lc.bean.WaterSensor, fields = [id: String, ts: Long, vc: Integer]>> WaterSensor{id='s1', ts=12, vc=12}可以看到,在输入 s1,16,16 时已经关闭了 [ 0 , 10 ) 的窗口,后面迟到的数据放入了侧输出流。
乱序、迟到的数据处理设置经验:
- watermark等待时间不宜设置过大,一般是秒级别,在乱序和延迟之间取舍。
- 设置一定的窗口允许迟到,只考虑大部分迟到数据,不考虑极端小部分的迟到数据。
- 极端小部分迟到数据,放入侧输出流,获取后做处理。
三.基于时间的合流——双流联结(Join)
可以发现,根据某个key合并两条流,与关系型数据库中表的join操作非常相近。事实上,Flink中两条流的connect操作,就可以通过keyBy指定键进行分组后合并,实现了类似于SQL中的join操作;另外connect支持处理函数,可以使用自定义实现各种需求,其实已经能够处理双流join的大多数场景。
不过处理函数是底层接口,所以尽管connect能做的事情多,但在一些具体应用场景下还是显得太过抽象了。比如,如果我们希望统计固定时间内两条流数据的匹配情况,那就需要自定义来实现——其实这完全可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink的DataStrema API提供了内置的join算子。
3.1 窗口联结(Window Join)
Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并将两条流中匹配公共键(key)的数据放在窗口中进行配对处理。
3.1.1 窗口联结的调用
用法:
stream1.join(stream2)
.where(<KeySelector>) // 指定流1要连接的Key
.equalTo(<KeySelector>) // 指定流2要连接的Key
.window(<WindowAssigner>) // 两条流一起开窗
.apply(<JoinFunction>) // 处理逻辑
例子:两条流,匹配出同一时间内的Key相同的数据。
/**
* Window Join
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 数据流 1
SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(
new Tuple2<>("a", 1),
new Tuple2<>("a", 2),
new Tuple2<>("b", 3),
new Tuple2<>("b", 4),
new Tuple2<>("c", 4)
).assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Integer>>forMonotonousTimestamps() // 单调递增的事件时间
.withTimestampAssigner((v, ts) -> v.f1 * 1000)); // 水位线提取器
// 数据流 1
SingleOutputStreamOperator<Tuple3<String, Integer , Integer>> ds2 = env.fromElements(
new Tuple3<>("a", 3 , 11),
new Tuple3<>("a", 11 , 22),
new Tuple3<>("b", 6 , 3),
new Tuple3<>("b", 9 , 13),
new Tuple3<>("c", 10 , 12)
).assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple3<String, Integer , Integer>>forMonotonousTimestamps() // 单调递增的事件时间
.withTimestampAssigner((v, ts) -> v.f1 * 1000)); // 水位线提取器
/**
* Window Join
* 1、落在同一时间窗口内的数据才能匹配
* 2、根据数据中的某个Key进行匹配
* 3、只能获取匹配成功的数据
* 4、类似 Inner Join
*/
DataStream<String> join = ds1 // 第一条流
.join(ds2) // join 第二条流
.where(r1 -> r1.f0) // 第一条流中要匹配的key
.equalTo(r2 -> r2.f0) // 第一条流中要匹配的key
.window(TumblingEventTimeWindows.of(Time.seconds(10))) // 十秒滚动窗口
.apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {
@Override
public String join(Tuple2<String, Integer> v1, Tuple3<String, Integer, Integer> v2) throws Exception {
return v1 + "<===匹配===>" + v2;
}
});
env.execute();
}结果:
(a,1)<===匹配===>(a,3,11)
(a,2)<===匹配===>(a,3,11)
(b,3)<===匹配===>(b,6,3)
(b,3)<===匹配===>(b,9,13)
(b,4)<===匹配===>(b,6,3)
(b,4)<===匹配===>(b,9,13)
只有Key匹配,且落在同一时间窗口的数据才能匹配。
3.1.2 间隔联结(Interval Join)
在有些场景下,我们要处理的时间间隔可能并不是固定的。这时显然不应该用滚动窗口或滑动窗口来处理,因为数据很可能卡在窗口的两侧边缘,例如 a,5 与 a,11 ,虽然Key相匹配,但是a,11属于 [ 10 , 20 ] 的窗口,则无法匹配,显然基于时间的窗口联合无能为力。
为了应对这样的需求,Flink提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
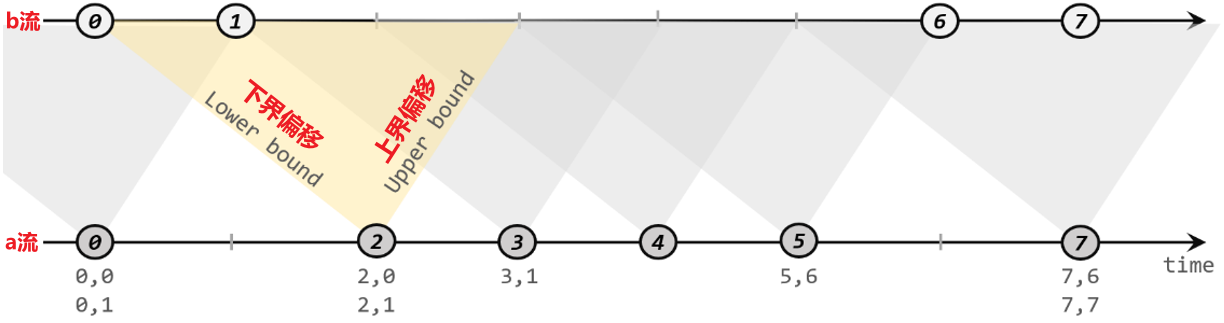
下方的流a去间隔联结上方的流b,所以基于A的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2毫秒,上界为1毫秒。于是对于时间戳为2的A中元素,它的可匹配区间就是[0, 3],流B中有时间戳为0、1的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A中时间戳为3的元素,可匹配区间为[1, 4],B中只有时间戳为1的一个数据可以匹配,于是得到匹配数据对(3, 1)。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 数据流 1
SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env
.socketTextStream("xxx.xxx.xxx", 1234)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] data = s.split(",");
return Tuple2.of(data[0],Integer.valueOf(data[1]));
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Integer>>forMonotonousTimestamps() // 单调递增的事件时间
.withTimestampAssigner((v, ts) -> v.f1 * 1000)
); ;
// 数据流 2
SingleOutputStreamOperator<Tuple3<String, Integer , Integer>> ds2 = env
.socketTextStream("xxx.xxx.xxx", 4321)
.map(new MapFunction<String, Tuple3<String, Integer,Integer>>() {
@Override
public Tuple3<String, Integer ,Integer> map(String s) throws Exception {
String[] data = s.split(",");
return Tuple3.of(data[0],Integer.valueOf(data[1]),Integer.valueOf(data[2]));
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple3<String, Integer , Integer>>forMonotonousTimestamps() // 单调递增的事件时间
.withTimestampAssigner((v, ts) -> v.f1 * 1000)
); // 水位线提取器;
// 两条流分别KeyBy,Key就是关联条件
KeyedStream<Tuple2<String, Integer>, String> ks1 = ds1.keyBy(k1 -> k1.f0);
KeyedStream<Tuple3<String, Integer, Integer>, String> ks2 = ds2.keyBy(k2 -> k2.f0);
// 定义两个侧输出流存放左右流的迟到数据
OutputTag<Tuple2<String, Integer>> leftLateTag = new OutputTag<>("left-late", Types.TUPLE(Types.STRING, Types.INT));
OutputTag<Tuple3<String, Integer, Integer>> rightLateTag = new OutputTag<>("right-late", Types.TUPLE(Types.STRING, Types.INT,Types.INT));
// 调用 Interval join 间隔联合
SingleOutputStreamOperator<String> process = ks1.intervalJoin(ks2)
.between(Time.seconds(-2), Time.seconds(2)) // 上界偏移-2s,下界偏移2s
.sideOutputLeftLateData(leftLateTag) // 第一条流的迟到数据放入侧输出流
.sideOutputRightLateData(rightLateTag) // 第二条流的迟到数据放入侧输出流
.process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {
/**
*
* @param left join左边的流
* @param right join右边的流
* @param ctx 上下文信息
* @param out 采集器
* @throws Exception
*/
@Override
public void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>.Context ctx, Collector<String> out) throws Exception {
out.collect(left + "<---匹配--->" + right);
}
});
process.getSideOutput(leftLateTag).printToErr("左流迟到数据");
process.getSideOutput(rightLateTag).printToErr("右流迟到数据");
process.print();
env.execute();
}输入:
[root@VM-12-13-centos ~]# nc -lk 1234
1> a,6
3> a,10
[root@VM-12-13-centos ~]# nc -lk 4321
2> a,5,5
4> a,12,12
5> a,4,4
输出:
(a,6)<---匹配--->(a,5,5)
(a,10)<---匹配--->(a,12,12)
右流迟到数据> (a,4,4)Interval join
1、只支持事件时间
2、指定上界、下界的偏移,负号代表时间往前,正号代表时间往后
3、process中,只能处理匹配上的数据
4、两条流关联后的watermark,以两条流中最小的为准
5、如果 当前数据的事件时间 < 当前的watermark,就是迟到数据, 主流的process不处理
=> between后,可以指定将 左流 或 右流 的迟到数据 放入侧输出流