### 1. **混淆矩阵简介**
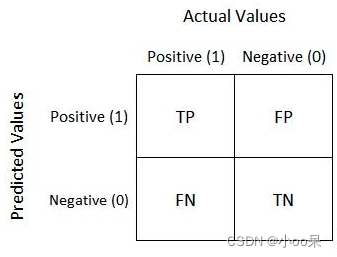
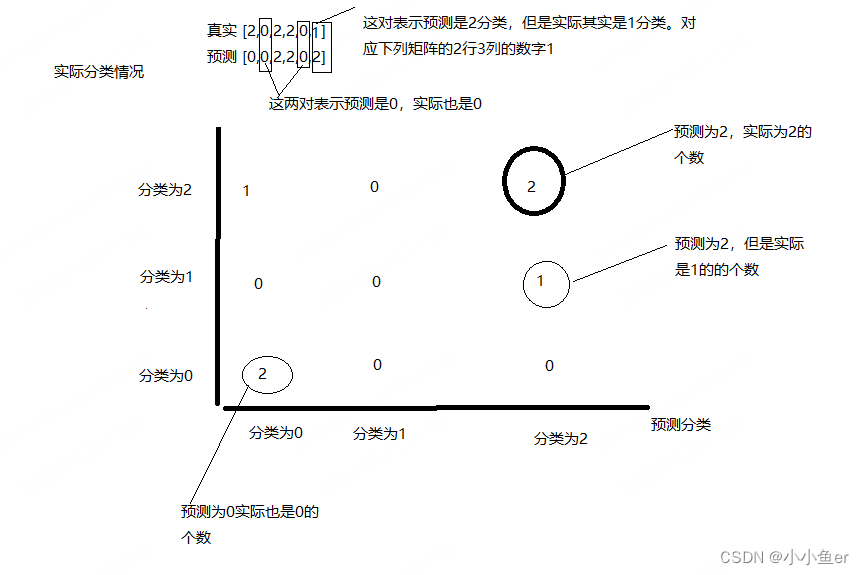
混淆矩阵是评估分类模型性能的一种表格布局,用于展示模型预测的准确性。它特别适用于监督学习算法中的分类问题。混淆矩阵不仅帮助我们理解模型在正确分类和错误分类方面的表现,而且还提供了判断模型是否有偏差的依据。
### 2. **混淆矩阵的组成**
混淆矩阵由四个部分组成:
- **真正例 (True Positives, TP)**:模型正确预测为正例的数量。
- **假正例 (False Positives, FP)**:模型错误预测为正例的数量。
- **真负例 (True Negatives, TN)**:模型正确预测为负例的数量。
- **假负例 (False Negatives, FN)**:模型错误预测为负例的数量。
这四个元素构成了混淆矩阵的基础,帮助我们深入理解模型的分类能力。
### 3. **性能指标**
通过混淆矩阵,我们可以计算多个重要的性能指标:
- **准确度 (Accuracy)**:所有分类正确的观测值占总观测值的比例。
- **召回率 (Recall)**:在所有实际正例中,被正确识别为正例的比例。
- **精确度 (Precision)**:在所有预测为正例的观测值中,实际为正例的比例。
- **F1分数 (F1 Score)**:精确度和召回率的调和平均值,用于衡量模型的整体性能。
### 4. **实际应用示例**
假设在医疗诊断测试中,混淆矩阵可以帮助医生了解疾病筛查测试的性能。例如,高召回率表示大多数实际病患被正确诊断,而高精确度则意味着被诊断为病患的人中真实病患的比例较高。
### 5. **混淆矩阵的局限性**
尽管混淆矩阵是一个强大的工具,但它也有局限性。例如,它不适用于处理非平衡数据集,即其中一类的观测值数量远多于另一类的情况。
### 6. **总结**
混淆矩阵提供了一种直观的方式来理解分类模型的性能。通过深入分析TP、FP、TN和FN,我们不仅能评估模型的准确度,还能洞察其潜在的偏差和局限性。虽然它不是解决所有问题的万能钥匙,但在许多情况下,混淆矩阵都是理解和改进分类模型不可或缺的工具。



















![力扣每日一题day33[111. 二叉树的最小深度]](https://img-blog.csdnimg.cn/img_convert/9ef108bb12725c2cf7697039e386c61d.jpeg)



![[GPT]Andrej Karpathy微软Build大会GPT演讲(下)--该如何使用GPT助手](https://img-blog.csdnimg.cn/direct/e8820b713a1e45a7b80e3fff9ca6a1dc.png)