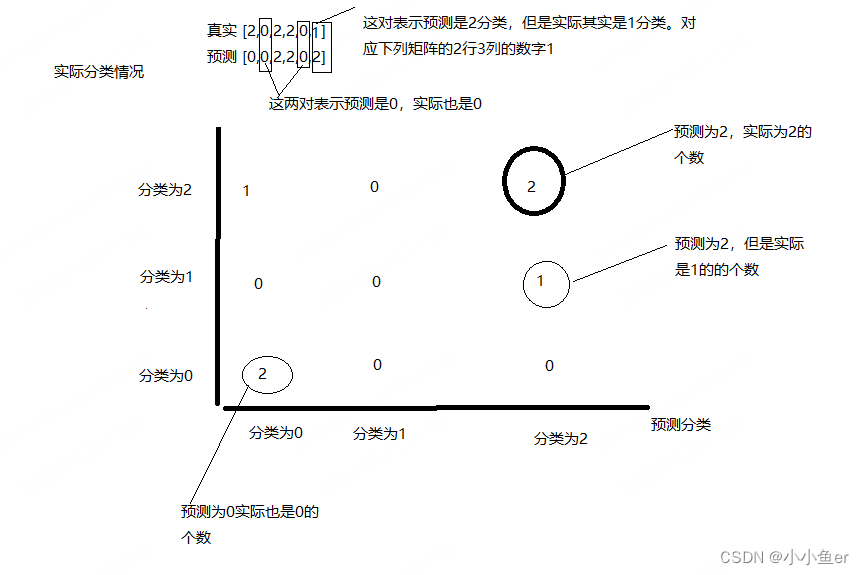
混淆矩阵(Confusion Matrix),又称为错误矩阵,是一种特别适用于监督学习中分类问题评估模型性能的工具。在机器学习领域,混淆矩阵能够清晰地显示算法模型的分类结果和实际情况之间的差异,常用于二分类和多分类问题。
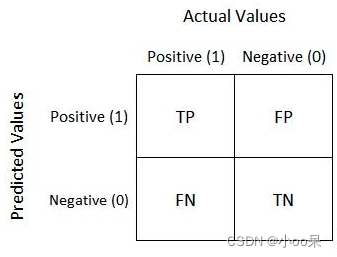
一个基本的二分类混淆矩阵包含四个部分:
- 真正类(True Positive, TP):模型正确预测为正类的样本数。
- 假正类(False Positive, FP):模型错误预测为正类的样本数,实际上它们是负类。
- 真负类(True Negative, TN):模型正确预测为负类的样本数。
- 假负类(False Negative, FN):模型错误预测为负类的样本数,实际上它们是正类。
混淆矩阵通常以表格形式表示,对于二分类问题,其形式如下:

通过混淆矩阵,我们可以计算出多种性能指标来评估分类模型的性能,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)或者真正率(True Positive Rate,TPR)、假正率(False Positive Rate,FPR)以及F1分数等。
准确率(Accuracy)是最直观的性能指标,计算公式为:
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac {TP + TN} {TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
精确率(Precision)关注的是预测为正类的样本中有多少是真正的正类,计算公式为:
P r e c i s i o n = T P T P + F P Precision = \frac {TP }{TP + FP} Precision=TP+FPTP
召回率(Recall)或真正率(TPR)关注的是所有真正的正类样本中有多少被模型预测为正类,计算公式为:
R e c a l l = T P T P + F N Recall = \frac {TP}{TP + FN} Recall=TP+FNTP
F1分数是精确率和召回率的调和平均值,计算公式为:
F 1 = 2 ∗ ( P r e c i s i o n ∗ R e c a l l ) P r e c i s i o n + R e c a l l F1 = \frac {2 * (Precision * Recall) }{Precision + Recall} F1=Precision+Recall2∗(Precision∗Recall)
对于多分类问题,混淆矩阵会更大,每一行代表实际类别,每一列代表预测类别,但计算各项指标的原理与二分类问题相同。
混淆矩阵的优点在于它不仅提供了错误分类的数量,还告诉我们哪些类别的预测错误最多,这对于改进分类算法和模型调优非常有帮助。