- 研究目的 根据用户的app使用情况,用户的流量使用情况,用户通话记录,用户的短信记录,判定用户号码是否是诈骗号码。
- 数据集
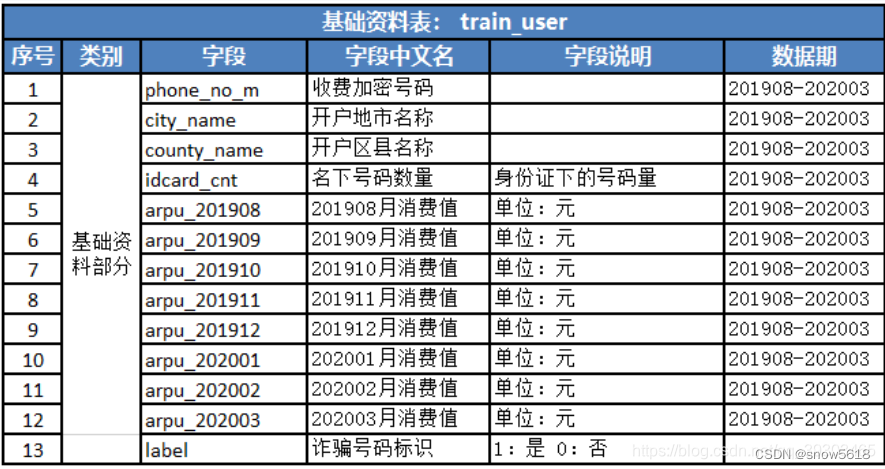
- train:
train_app.csv:app使用情况 .
train_user.csv:基本信息 .
train_voc.csv:通话 .
train_sms.csv:短信- test:
test_app.csv:app使用情况 .
test_user.csv:基本信息 .
test_voc.csv:通话
test_sms.csv:短信
2. 导入包
# 计算
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习库
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier,AdaBoostClassifier,BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.model_selection import train_test_split,cross_val_predict,StratifiedKFold
from sklearn import metrics
from scipy import stats
from scipy.cluster.hierarchy import dendrogram,linkage
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = ['SimHei']
train_user = pd.read_csv('train/train_user.csv')
train_app = pd.read_csv('train/train_app.csv')
train_voc = pd.read_csv('train/train_voc.csv')
train_sms = pd.read_csv('train/train_sms.csv')
train_user.shape,train_app.shape,train_voc.shape,train_sms.shape
3. 数据预处理
3.1 特征衍生
观察 数据发现 用户表中有6000多条数据,但是其他三个表中数据很大,为此我们对其他表数据进行预处理,特征工程。
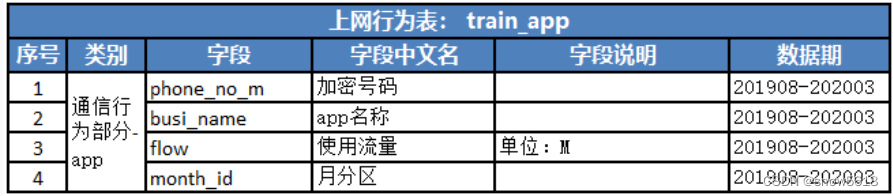
- 1.1 train_app 表中包含 app,流量,月份的情况,我们可以转换成 .每个用户涉及的app个数 app_counts, .统计每个用户的流量使用情况,total_flow .统计每个用户活跃月份个数,months .统计每个用户活跃月流量使用情况
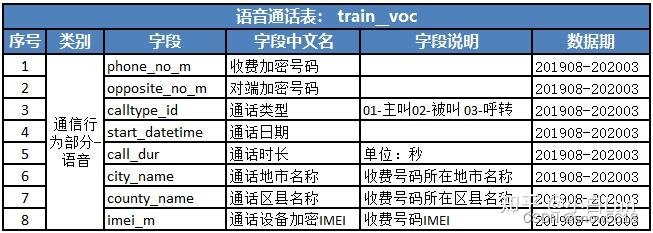
total_flow/months .统计每个用户平均app使用情况, app_flow- 1.2 voc通话数据处理:原有特征包括:对端通话号码,通话开始时间,通话时长,涉及城市,涉及乡镇,涉及设备编码
- 统计每个用户涉及的对端通话号码个数 nunique
- 统计每个用户每个对端平均通话时长 avg_user_call, sum
- 统计每个月平均通话时长 avg_month_call, total_call/month_count
- 涉及设备个数 imei_count,nunique
- 涉及城市个数 city_count,nunique
- 涉及乡镇个数 county_count,nunique
- 活跃月份个数 month_count,nunique
- 通话总时长 total_call sum
- count是统计所有次数,nunique统计唯一出现次数(每个类别只统计一次)
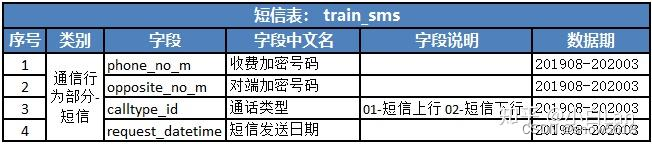
- 1.3 短信处理方式也类似。
1. app数据处理
train_app['month_id'] = pd.to_datetime(train_app['month_id'],format='%Y-%m-%d')
train_app['month'] = train_app['month_id'].dt.month
app_count = train_app.groupby(['phone_no_m'])['busi_name'].agg(app_count='nunique')
total_flow = train_app.groupby(['phone_no_m'])['flow'].agg(total_flow='sum')
total_month = train_app.groupby(['phone_no_m'])['month'].agg(total_month='nunique')
# 与用户表聚合
new_train_user = pd.merge(train_user,app_count,on='phone_no_m',how='left')
new_train_user = pd.merge(new_train_user,total_flow,on='phone_no_m',how='left')
new_train_user = pd.merge(new_train_user,total_month,on='phone_no_m',how='left')
new_train_user['avg_flow'] = new_train_user['total_flow']/new_train_user['total_month']
new_train_user['app_flow'] = new_train_user['total_flow']/new_train_user['app_count']
new_train_user.head()
# 2. voc通话记录
train_voc['start_datetime'] = pd.to_datetime(train_voc['start_datetime'],format='%Y-%m-%d %H:%M:%S')
train_voc['month'] = train_voc.start_datetime.dt.month
# 只考虑主叫
train_voc_1 = train_voc[train_voc['calltype_id']==1]
total_call = train_voc_1.groupby(['phone_no_m'])['call_dur'].agg(total_call='sum')
month_count = train_voc_1.groupby(['phone_no_m'])['month'].agg(month_count='nunique')
user_count = train_voc_1.groupby(['phone_no_m'])['opposite_no_m'].agg(user_count='nunique')
city_count = train_voc_1.groupby(['phone_no_m'])['city_name'].agg(city_count='nunique')
county_count = train_voc_1.groupby(['phone_no_m'])['county_name'].agg(county_count='nunique')
imei_count = train_voc_1.groupby(['phone_no_m'])['imei_m'].agg(imei_count='nunique')
# 合并数据
new_train_user_voc = pd.merge(new_train_user,total_call,on='phone_no_m',how='left')
new_train_user_voc = pd.merge(new_train_user_voc,month_count,on='phone_no_m',how='left')
new_train_user_voc = pd.merge(new_train_user_voc,user_count,on='phone_no_m',how='left')
new_train_user_voc = pd.merge(new_train_user_voc,city_count,on='phone_no_m',how='left')
new_train_user_voc = pd.merge(new_train_user_voc,county_count,on='phone_no_m',how='left')
new_train_user_voc = pd.merge(new_train_user_voc,imei_count,on='phone_no_m',how='left')
new_train_user_voc['avg_user_call'] = new_train_user_voc['total_call']/new_train_user_voc['user_count']
new_train_user_voc['avg_month_call'] = new_train_user_voc['total_call']/new_train_user_voc['month_count']
new_train_user_voc['avg_county_call'] = new_train_user_voc['total_call']/new_train_user_voc['county_count']
new_train_user_voc.head()
# 3. sms统计短信收发个数
train_sms['request_datetime'] = pd.to_datetime(train_sms['request_datetime'],format='%Y-%m-%d %H:%M:%S')
train_sms['month'] = train_sms.request_datetime.dt.month
month_count = train_sms.groupby(['phone_no_m'])['month'].agg(month_count2='nunique')
user_count = train_sms.groupby(['phone_no_m'])['opposite_no_m'].agg(user_count2='nunique')
total_count = train_sms.groupby(['phone_no_m'])['opposite_no_m'].agg(sms_count='count') # 每个用户通话次数统计
new_train_user_voc_sms = pd.merge(new_train_user_voc,month_count,on='phone_no_m',how='left')
new_train_user_voc_sms = pd.merge(new_train_user_voc_sms,user_count,on='phone_no_m',how='left')
new_train_user_voc_sms = pd.merge(new_train_user_voc_sms,total_count,on='phone_no_m',how='left')
new_train_user_voc_sms['avg_sms_user_count'] = new_train_user_voc_sms['sms_count']/new_train_user_voc_sms['user_count2']
new_train_user_voc_sms['avg_sms_month_count'] = new_train_user_voc_sms['sms_count']/new_train_user_voc_sms['month_count2']
new_train_user_voc_sms.head()
数据预处理 测试集
test
test_user = pd.read_csv('test/test_user.csv')
test_app = pd.read_csv('test/test_app.csv')
test_voc = pd.read_csv('test/test_voc.csv')
test_sms = pd.read_csv('test/test_sms.csv')
# 1. app
test_app['month_id'] = pd.to_datetime(test_app['month_id'],format='%Y-%m-%d')
test_app['month'] = test_app['month_id'].dt.month
app_count = test_app.groupby(['phone_no_m'])['busi_name'].agg(app_count='nunique')
total_flow = test_app.groupby(['phone_no_m'])['flow'].agg(total_flow='sum')
total_month = test_app.groupby(['phone_no_m'])['month'].agg(total_month='nunique')
# 2. voc
test_voc['start_datetime'] = pd.to_datetime(test_voc['start_datetime'],format='%Y-%m-%d %H:%M:%S')
test_voc['month'] = test_voc.start_datetime.dt.month
# 只考虑主叫
test_voc_1 = test_voc[test_voc['calltype_id']==1]
total_call = test_voc_1.groupby(['phone_no_m'])['call_dur'].agg(total_call='sum')
month_count1 = test_voc_1.groupby(['phone_no_m'])['month'].agg(month_count1='nunique')
user_count1 = test_voc_1.groupby(['phone_no_m'])['opposite_no_m'].agg(user_count1='nunique')
city_count = test_voc_1.groupby(['phone_no_m'])['city_name'].agg(city_count='nunique')
county_count = test_voc_1.groupby(['phone_no_m'])['county_name'].agg(county_count='nunique')
imei_count = test_voc_1.groupby(['phone_no_m'])['imei_m'].agg(imei_count='nunique')
# 3. sms
test_sms['request_datetime'] = pd.to_datetime(test_sms['request_datetime'],format='%Y-%m-%d %H:%M:%S')
test_sms['month'] = test_sms.request_datetime.dt.month
month_count2 = test_sms.groupby(['phone_no_m'])['month'].agg(month_count2='nunique')
user_count2 = test_sms.groupby(['phone_no_m'])['opposite_no_m'].agg(user_count2='nunique')
total_count = test_sms.groupby(['phone_no_m'])['opposite_no_m'].agg(sms_count='count') # 每个用户通话次数统计
# 合并数据
new_test_app = pd.merge(test_user,app_count,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,total_flow,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,total_month,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,total_call,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,month_count1,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,user_count1,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,city_count,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,county_count,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,imei_count,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,month_count2,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,user_count2,on='phone_no_m',how='left')
new_test_app = pd.merge(new_test_app,total_count,on='phone_no_m',how='left')
new_test_app['avg_user_call'] = new_test_app['total_call']/new_test_app['user_count1']
new_test_app['avg_month_call'] = new_test_app['total_call']/new_test_app['month_count1']
new_test_app['avg_county_call'] = new_test_app['total_call']/new_test_app['county_count']
new_test_app['avg_flow'] = new_test_app['total_flow']/new_test_app['total_month']
new_test_app['app_flow'] = new_test_app['total_flow']/new_test_app['app_count']
new_test_app['avg_sms_user_count'] = new_test_app['sms_count']/new_test_app['user_count2']
new_test_app['avg_sms_month_count'] = new_test_app['sms_count']/new_test_app['month_count2']
new_test_app.head()
3.2 缺失值处理
从3.1 处理后的数据中查看可以发现部分数据是inf无穷大,此时我们先需要将其转换成nan,在当缺失值处理。
undefined.无穷大 统计:np.isinf().sum()
undefined.无穷大 替换:df.replace([np.inf,-np.inf],np.nan,inplace=True)
X_train.replace([np.inf,-np.inf],np.nan,inplace=True)
X_test.replace([np.inf,-np.inf],np.nan,inplace=True)
# 中位数值填充
X_test.isnull().sum()
X_train.fillna(X_train.median(),inplace=True)
X_train.isnull().sum()
X_test.fillna(X_test.median(),inplace=True)
3.3 异常值检测和特征一致性
测试集中是20年4月份的arpu,训练集中没有,通过展示arpu值,发现每个月分布相似,故选择20年2月份当作4月份的arpu
- 将宽列表arpu[2018,2019,2020] 转变成长列表,[year,arpu]
,year是新列名,arpu是存放之前列的值- melt函数:id_vars不需要转变的列,value_vars需要转变的列,var_name新列名,value_name存在旧列值
arpu_columns = ['phone_no_m','arpu_201908','arpu_201909','arpu_201910','arpu_201911','arpu_201912','arpu_202001','arpu_202002','arpu_202003']
var_columns = ['arpu_201908','arpu_201909','arpu_201910','arpu_201911','arpu_201912','arpu_202001','arpu_202002','arpu_202003']
data_arpu = pd.melt(train_data[arpu_columns],id_vars=['phone_no_m'],value_vars=var_columns,var_name='month',value_name='arpu')
data_arpu.describe().T
# 异常值检测
sns.catplot(data=data_arpu,x='month',y='arpu',kind='boxen')
# 根据3sigma原则删除异常值
data_arpu = data_arpu[abs(data_arpu['arpu']-data_arpu['arpu'].mean())<3*data_arpu['arpu'].std()]
data_arpu.describe().T
# 绘制每月的arpu分布情况
g = sns.catplot(data=data_arpu,x='month',y='arpu',kind='box')
g.set_xticklabels(rotation=90)
train_data.rename(columns={
'arpu_202002':'arpu_202004'},inplace=True)
train_data.drop(['phone_no_m','city_name','county_name'],axis=1,inplace=True)
var_columns = ['arpu_201908','arpu_201909','arpu_201910','arpu_201911','arpu_201912','arpu_202001','arpu_202003']
train_data.drop(columns=var_columns,axis=1,inplace=True)
test_data.drop(['phone_no_m','city_name','county_name'],axis=1,inplace=True)
3.4 数据归一化
由于个别数值差别很大,因此采用数据归一化进行处理。
# 标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
# 划分数据集
X_train,X_val,y_train,y_val = train_test_split(X_train,y_train,test_size=0.3)
4. 建模
- 多建立几个模型更加交叉验证选出最好的模型后,在进行参数调优
- 根据预测的结果,采用验证集预测,设置阈值范围,获取最优的auc
from sklearn.model_selection import cross_val_score
# 1. 建模
kfold = StratifiedKFold(n_splits=10)
Classifiers = []
Classifiers.append(AdaBoostClassifier())
Classifiers.append(BaggingClassifier())
Classifiers.append(DecisionTreeClassifier())
Classifiers.append(ExtraTreesClassifier())
Classifiers.append(RandomForestClassifier())
Classifiers.append(XGBClassifier())
Classifiers.append(LGBMClassifier())
# 2. 训练
results = []
labels = []
for classifier in Classifiers:
results.append(cross_val_score(classifier,X_train,y_train,scoring='accuracy',cv=kfold,n_jobs=1))
labels.append(classifier.__class__.__name__)
res_mean = []
res_std = []
for res in results:
res_mean.append(res.mean())
res_std.append(res.std())
res_data = pd.DataFrame({
'model':labels,'means':res_mean,'std':res_std})
res_data.head()
g = sns.catplot(data=res_data,y='means',x='model',kind='bar')
g.set_xticklabels(rotation=60)
# 调优
pagrams = {
'max_depth':[6,8,10],
'ccp_alpha':[0.0,0.1,0.01,100],
'random_state':[1,10]
}
from sklearn.model_selection import GridSearchCV
rf_model = GridSearchCV(RandomForestClassifier(),param_grid=pagrams,scoring='accuracy',cv=kfold,n_jobs=1)
rf_model.fit(X_train,y_train)
# 预测
y_pred_proc = rf_model.predict_proba(X_val)
thresholds = [0.3,0.49,0.55,0.58,0.5,0.6,0.8,0.9,1]
for i in thresholds:
# 选出第二列:类别1的概率值 满足条件返回True,不然就是False,若是True astype(int)=1,false=0
y_pred = (y_pred_proc[:,1]>i).astype(int)
# 计算精确读
print("au:{},\t thresholds:{}".format(metrics.accuracy_score(y_val,y_pred),i)
5. 输出结果
X_test1 = X_test.copy()
X_test1.drop(['phone_no_m','city_name','county_name'],axis=1,inplace=True)
X_test1 = sc.fit_transform(X_test1)
y_ = rf_model.predict_proba(X_test1)
y_label = (y_[:,1]>0.55).astype(int)
X_test['label'] = y_label
X_test.head()
X_test.to_csv('results.csv',index=None)
6. 致谢
图片和数据预处理思路来源于https://zhuanlan.zhihu.com/p/323280016utm_psn=1715065426093146112