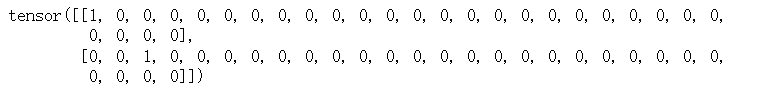1. 神经网络概述
1.1 定义与历史
神经网络是一种模仿人脑神经元结构和功能的计算模型,它由大量的节点(或称为神经元)相互连接构成。每个节点可以接收多个输入信号,通过加权求和后,再通过一个非线性激活函数产生输出信号。神经网络的灵感来源于生物神经网络,其历史可以追溯到20世纪40年代,当时Warren McCulloch和Walter Pitts提出了人工神经元的数学模型。
- 发展阶段:神经网络的发展经历了多个阶段,包括早期的感知机模型、多层感知器(MLP)的兴起与低谷,以及近年来深度学习的兴起。深度学习的出现,特别是卷积神经网络(CNN)和循环神经网络(RNN)的成功应用,使得神经网络在图像识别、语音识别、自然语言处理等领域取得了突破性进展。
1.2 重要性与应用
神经网络在现代人工智能领域扮演着至关重要的角色。其重要性体现在以下几个方面:
- 自动化决策:神经网络能够处理复杂的非线性关系,使得自动化决策成为可能,广泛应用于金融、医疗、交通等领域。
- 模式识别:在图像和语音识别中,神经网络展现出了超越传统算法的性能,极大地推动了相关技术的发展。
- 自然语言处理:神经网络在机器翻译、情感分析、文本生成等自然语言处理任务中发挥着核心作用。
应用案例包括但不限于:
- 图像识别:通过卷积神经网络(CNN),神经网络能够识别和分类图像中的物体,应用于自动驾驶、医疗影像分析等领域。
- 语音识别:循环神经网络(RNN)和长短期记忆网络(LSTM)在语音识别和生成中表现出色,被广泛应用于智能助手和自动翻译服务。
- 推荐系统:神经网络在推荐系统中用于分析用户行为,提供个性化的推荐内容,广泛应用于电商、社交媒体等平台。
2. 使用PyTorch进行简单的实现
2.1 神经网络的基本原理
在PyTorch中实现神经网络之前,需要理解其基本原理,包括前向传播和反向传播。
- 前向传播:输入数据在网络中向前传递,每一层的神经元计算其输入的加权和,然后通过激活函数生成输出,传递给下一层,直至最终的输出层。
- 反向传播:在训练过程中,通过计算损失函数关于网络参数的梯度,反向传播这些梯度,以更新网络的权重和偏置,目的是最小化损失函数。
2.2 PyTorch实现
PyTorch是一个流行的开源机器学习库,它提供了构建和训练神经网络的高级API。
- 定义网络结构:使用PyTorch的
nn.Module类定义网络结构,包括层的类型、激活函数等。 - 初始化权重:网络的权重和偏置需要初始化,通常使用小的随机数。
- 前向传播函数:定义一个前向传播函数,用于计算网络的输出。
- 损失函数:选择合适的损失函数,如均方误差(MSE)或交叉熵损失,用于评估网络的预测与真实值之间的差异。
- 优化器:使用优化器,如SGD或Adam,来更新网络的权重。
以下是一个简单的PyTorch实现示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义网络结构
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 4) # 输入层到隐藏层
self.fc2 = nn.Linear(4, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 初始化网络
model = SimpleNN()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练数据
inputs = torch.tensor([[1.0, 2.0], [2.0, 3.0]])
targets = torch.tensor([[1.0], [2.0]])
# 训练过程
for epoch in range(100):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
在上述代码中,我们定义了一个简单的前馈神经网络,包含一个隐藏层,使用ReLU作为激活函数。我们使用SGD优化器进行训练,并在每轮迭代中计算损失并更新权重。
2. 神经网络基本原理
2.1 神经元模型
神经网络的基本构成单位是神经元(Neuron),它模仿了人脑中神经元的工作机制。每个神经元接收来自其他神经元的输入信号,通过加权求和后,再通过一个非线性激活函数产生输出。
- 数学模型:神经元的数学模型可以用 y = f ( ∑ i w i x i + b ) y = f(\sum_{i} w_i x_i + b) y=f(i∑wixi+b)表示,其中$ x_i是输入信号, w_i 是与输入相关的权重, b 是偏置项, f 是非线性激活函数。

2.2 感知器与多层感知器
感知器是神经网络的早期形式,由单层神经元构成。多层感知器(MLP)则是感知器的扩展,由多个层次的神经元构成,能够学习和表征更复杂的函数。
单层感知器:单层感知器主要用于线性可分问题,通过一个激活函数将输入信号转换为输出。然而,它无法解决非线性问题。

多层感知器:通过增加隐藏层,多层感知器能够学习更复杂的非线性关系。每一层的神经元都与前一层的所有神经元相连,形成了一个全连接的网络结构。

3. 神经网络结构
3.1 输入层
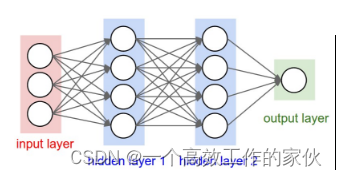
输入层是神经网络的第一层,负责接收外界的输入数据。在输入层,每个神经元对应一个输入特征,并且每个输入特征通过一个权重与后续的神经元相连。权重的初始值通常随机设定,并通过训练过程进行调整。输入层的主要作用是将原始数据传递到网络中,为后续的数据处理和特征提取提供基础。
3.2 隐藏层
隐藏层是神经网络中位于输入层和输出层之间的一个或多个层。这些层对输入数据进行进一步的非线性变换,以提取更高层次的特征。每个隐藏层由多个神经元组成,每个神经元通过激活函数对输入数据进行处理。激活函数,如Sigmoid、Tanh或ReLU,引入非线性,使得网络能够学习和模拟复杂的函数映射。
激活函数的作用
Sigmoid函数:将输入压缩到0和1之间,通常用于二分类问题。
Tanh函数:将输入压缩到-1和1之间,比Sigmoid有更宽的输出范围。
ReLU函数:只对正数进行线性变换,对负数输出0,计算效率高,是当前最流行的激活函数之一。
隐藏层的数量和每个隐藏层中的神经元数量是神经网络设计中的重要超参数,需要根据具体问题进行调整。
3.3 输出层
输出层是神经网络的最后一层,负责产生最终的预测结果。输出层的神经元数量取决于任务的类型。例如,在二分类问题中,输出层可能只有一个神经元,其输出可以表示为概率;而在多分类问题中,输出层的神经元数量等于类别数,每个神经元对应一个类别的得分。
2.3 使用PyTorch进行简单实现
PyTorch是一个流行的深度学习框架,它提供了灵活的计算图和自动求导功能,使得神经网络的实现和训练变得简单。
- 定义网络结构:在PyTorch中,可以通过继承
nn.Module类来定义自己的神经网络结构。例如,一个简单的多层感知器可以这样定义:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(784, 256) # 假设输入是28x28的图像,展平后为784
self.fc2 = nn.Linear(256, 10) # 假设有10个输出类别
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
- 训练过程:训练神经网络包括前向传播、计算损失、反向传播和参数更新。以下是一个简单的训练循环示例:
# 假设已经有了训练数据和标签
train_data = ... # 训练数据
train_labels = ... # 训练标签
model = SimpleMLP()
criterion = nn.CrossEntropyLoss() # 多分类问题使用交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器
for epoch in range(num_epochs):
for data, target in zip(train_data, train_labels):
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
- 评估模型:在训练过程中,通常需要在验证集上评估模型的性能,以监控过拟合和模型的泛化能力。
# 假设已经有了验证数据和标签
val_data = ... # 验证数据
val_labels = ... # 验证标签
correct = 0
total = 0
with torch.no_grad(): # 评估时不需要计算梯度
for data, target in zip(val_data, val_labels):
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f'Accuracy of the model on the validation set: {100 * correct / total}%')
通过上述步骤,可以构建、训练并评估一个简单的神经网络模型。