导入环境
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
读取文件
### 读取数据文件
features = pd.read_csv('temps.csv')
#看看数据长什么样子
features.head(5)
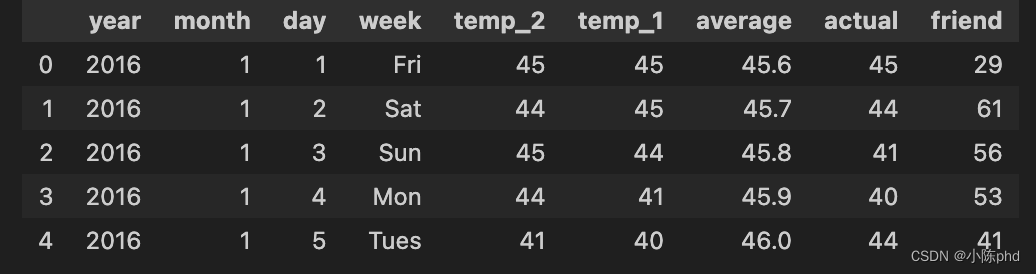
其中
数据表中
- year,moth,day,week分别表示的具体的时间
- temp_2:前天的最高温度值
- temp_1:昨天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:这就是我们的标签值了,当天的真实最高温度
- friend:据说凑热闹
查阅数据维度
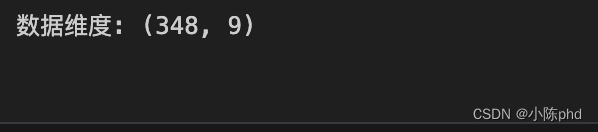
print('数据维度:', features.shape)
时间维度数据进行处理
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
查阅数据
data[:,5]
图像绘制
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)
# 标签值
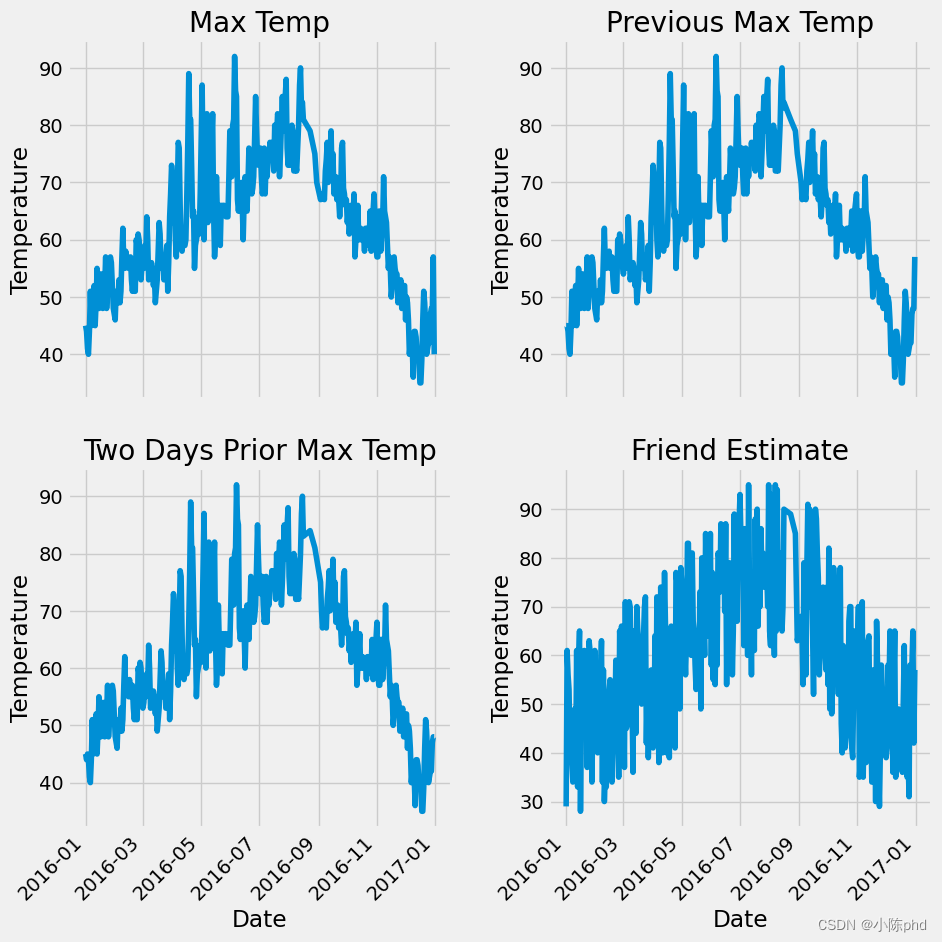
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
# 朋友
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
独热编码
数据需要独热编码(One-Hot Encoding),许多机器学习算法预期输入是数值型的,并且它们在处理数值型数据时表现更好。
独热编码是一种处理分类数据的方法,特别是在分类数据的各个类别之间没有顺序或等级的情况下。以下是使用独热编码的几个原因:
- 避免数值偏见:在很多模型中,如线性模型和神经网络,使用普通的数值标签(如1, 2, 3…)可能导致模型误认为类别之间存在数值上的关系,比如2是1的两倍,这可能会引入模型误解。
- 改善模型性能:通过独热编码,模型可以更明确地捕捉到每个类别的独特性,因为每个类别都由一个独立的特征表示,这有助于提高模型的准确性和学习效率。
- 扩展特征空间:独热编码可以将分类变量转化为一个更大的固定长度的数值型特征向量,这使得算法能够更容易地在这些扩展的特征空间上进行操作和优化。
# 独热编码
features = pd.get_dummies(features)
features.head(5)

处理标签
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
# 名字单独保存一下
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)
features.shape

机器学习建模
数据标准化
标准化的作用:
消除量纲影响:在很多数据集中,不同的特征可能具有完全不同的量纲和单位(如公里、千克、百分比等)。未经标准化的数据如果直接用于模型训练,可能会因为量纲的差异而影响模型的性能,使得某些特征的权重过大或过小。
提高算法表现:很多机器学习算法(尤其是基于距离的算法如K-最近邻、支持向量机等)在处理数据时,会受到特征尺度的影响。通过标准化处理,可以确保每个特征对模型的影响是均衡的,从而提高算法的精确度和效率。
加速模型收敛:在使用梯度下降等优化算法时,如果数据集的特征尺度差异较大,可能会导致优化过程中步长的不均匀,使得收敛速度变慢。标准化后,由于所有特征都处在相同的尺度上,有助于加快学习算法的收敛速度。
应对异常值:标准化过程通常包括消除异常值的影响,比如通过将数据缩放到一个固定的范围(如0到1之间),或者通过z-score方法(即减去平均值,除以标准差)来减少某些极端值对整体数据分布的影响。
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[0]

torch搭建MLP模型
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype = float)
# 权重参数初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True)
learning_rate = 0.001
losses = []
for i in range(1000):
# 计算隐层
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2) + biases2
# 通计算损失
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
# 打印损失值
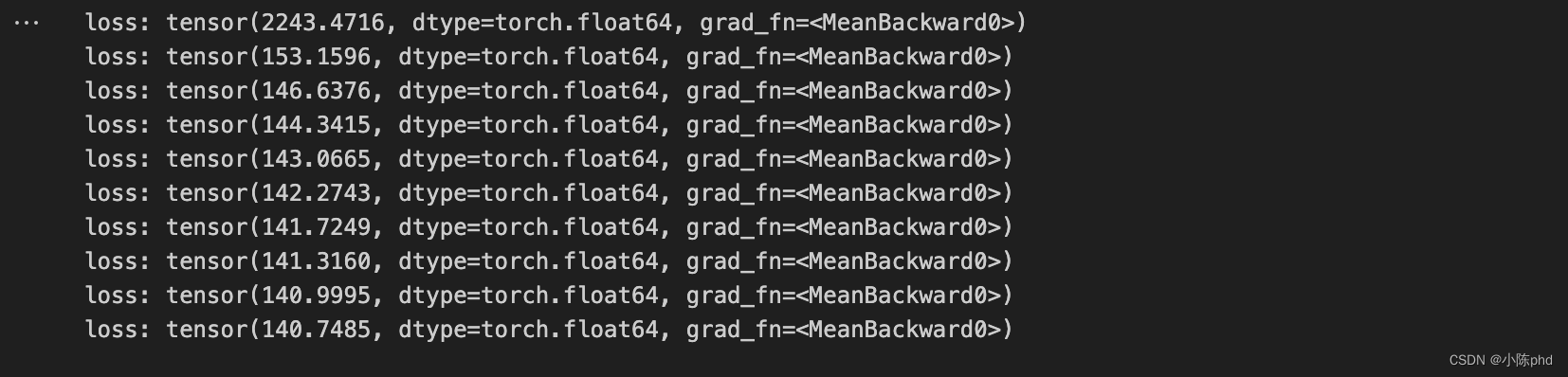
if i % 100 == 0:
print('loss:', loss)
#返向传播计算
loss.backward()
#更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代都得记得清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
预测结果
predictions.shape

整体模型
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)
# 训练网络
losses = []
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype = torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype = torch.float, requires_grad = True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))

预测结果
x = torch.tensor(input_features, dtype = torch.float)
predict = my_nn(x).data.numpy()
日期转换
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
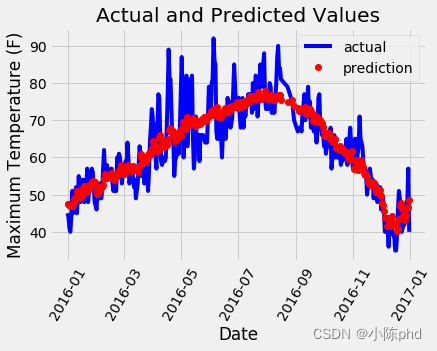
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
























![[通俗易懂]《动手学强化学习》学习笔记2-第2、3、4章](https://img-blog.csdnimg.cn/direct/467a2cc871084a53ad2b700c0fd320f0.png)