Masked Autoencoders Are Scalable Vision Learners
研究问题:
本文主要介绍了掩码自编码器( MAE, Masked autoencoders)是视觉领域中可扩展的自监督学习算法。MAE具体操作为随机屏蔽输入image中的patchs,再重建丢失的像素。其基于两个核心操作。第一个是建立不对称的编码器-解码器架构,编码器只对没有屏蔽掉的patchs操作,轻量化的解码器通过潜在表示和屏蔽令牌重建原始图像。第二是发现了一种屏蔽图像patchs的高比例,比如75%。结合这两个操作使我们能够高效地训练大模型,加速了训练过程且提高了准确率。在下游任务的迁移性优于有监督的预训练。
Abstract
本文主要介绍了掩码自编码器( MAE, Masked autoencoders)是视觉领域中可扩展的自监督学习算法。MAE具体操作为随机屏蔽输入image中的patchs,再重建丢失的像素。其基于两个核心操作。第一个是建立不对称的编码器-解码器架构,编码器只对没有屏蔽掉的patchs操作,轻量化的解码器通过潜在表示和屏蔽令牌重建原始图像。第二是发现了一种屏蔽图像patchs的高比例,比如75%。结合这两个操作使我们能够高效地训练大模型,加速了训练过程且提高了准确率。在下游任务的迁移性优于有监督的预训练。

一.Introduction
第一段:深度学习领域已经见证了模型容量和性能持续增长的爆炸性变化。由于硬件发展的支持,从原来的需要借助数亿张不公开的标签数据发展为现在轻松地过拟合出百万张图片。
第二段:NLP领域中处理对数据依赖的问题。在NLP领域中,自监督的训练方法已经解决了对数据依赖的方法,该方法基于GPT中的自回归语言模型和BERT中自掩码编码方法,其概念非常简单,就是随机屏蔽一部分数据后再学习预测出缺失的部分。该方法可以训练包含一千亿参数的可泛化NLP模型。

第三段:介绍掩码自编码器,以及该方法为什么在NLP和CV领域之间不同的原因。带掩码的自编码器是一种去噪编码器的常用方法,在CV中应用很好。在BERT之前视觉领域就有很多关于该方法的研究,但是该方法在CV领域仍然落后与NLP领域。以下为带掩码的自编码器在两个领域中不同的原因:
(1)架构不同。在CV领域,CNN在过去十年中一直占据主导地位,并且在CNN中添加掩码令牌和位置编码都有困难,后边的ViT已经解决了这个问题。
(2)语言和图像中信息密度不同。语言是人制造的且信息密度非常高,相反图片具有很多自然符号和烦杂的信息。在语言中,训练一个模型去预测一个句子中缺失的几个词就会诱发对整个句子的复杂性的理解,而在视觉中,利用周围的patches去重建被屏蔽的patch只产生很少的理解。为了解决这个不同且学习有效的特征,采用随机高比例地屏蔽patches,这种策略就减少的冗余且提高了对图像的整体理解。
(3)解码器在将潜在表示映射回输入的作用不同。在视觉中,解码器恢复缺失像素,对图像很少的语义理解,相反在文本中,需要恢复具有很强语义信息的词,所以需要理解文本。
第四段:简单概括MAE。MAE中具有不对称的编码器-解码器架构,编码器随机地屏蔽掉输入图像的patches,解码器根据潜在表示和掩码令牌恢复缺失的图像。在不对称的编码器-解码器架构中,将掩码令牌加入到轻量级解码器中大大减少了计算量。同时遮掩比(75%)既提高了精度,又使得编码器只需要处理一小部分patches,减少了训练时间和内存损耗。
第五段:展示结果以及在其他任务方面的迁移性。
二.Related Work
第一段:Masked Language modeling(掩码语言模型)和自回归模型,例如GPT的自回归语言模型和BERT的掩码语言建模在NLP领域都取得了很大的成功。这些方法都是保留输入序列的一部分,去预测缺失的部分。这些方法具有很强的扩展性且已经证明可以广泛应用到各种下游任务中去。
第二段:Auto encoders(自编码器)是学习表示中一种经典的方法。其中编码器将输入映射到潜在表示,解码器恢复输入信息。去噪自编码器是一种破坏输入信号,学习恢复输出信号的自编码器。MAE就是一种去噪自编码器。
第三段:掩码图像编码
第四段:Self-supervised learning(自监督学习)
三.Approach
总:介绍MAE,MAE与传统的自编码器的相同和不同。和传统的自编码器一样,MAE包含编码器和解码器,编码器将给定的观测值映射到潜在表示(可以理解为在语义空间上的一种表示),解码器根据潜在表示重建原始信号。和传统的编码器不同在于含有不对称的编码器-解码器架构,编码器可以仅仅处理未被屏蔽掉的信号,大大减少了计算复杂度,而轻量级解码器根据潜在表示和掩码令牌重建原始信号。
Masking
学习ViT中操作,将图片打散成若干不重叠的patches。再按照随机分布来对patches进行采样,进而屏蔽掉其他的patches。采用较高的遮掩比例既大大减少的数据冗余,减少计算量,又避免了通过邻近patches简单恢复缺失patch的问题。均匀分布也避免了中心缺失。
MAE Encoder:
是一个仅对未被屏蔽的输入信号进行操作的ViT。和标准的ViT一样,对输入的图片进行线性编码,后加上位置编码,最后通过一系列的ViT块对数据操作。这里的编码器仅需要处理未被屏蔽掉的信号,大大减少计算量,这就可以再较少的内存和计算量上训练更大的编码器。
MAE Decoder
解码器的输入是输入信号中未被屏蔽的部分和掩码令牌的总和。所有的掩码令牌都是共享的,其学习的向量就是被屏蔽掉的掩码令牌预测的向量。最后需要对所有的令牌(屏蔽掉和未屏蔽掉的)加上位置编码,否则掩码令牌就会没有在原始图像的位置信息。由于解码器只在预训练过程中用于重建图像,所以可以用一种独立于编码器且灵活的方式涉及,使解码器更窄、更浅,这样所有的令牌进入一个轻量级的解码器就会大大减少预训练的时间。
Reconstruction target
MAE通过预测像素值来为每一个被屏蔽的patch重构输入。解码器输出的每个元素都是代表一个patch的像素值向量。解码器的最后一层是线性投影层,其输出通道的个数就是patch中像素值的个数。对解码器的输出重构得到重构图像。损失函数在像素空间中计算重构图像和原始图像的均方误差,类似于BERT,只计算被屏蔽的patches。本文还研究了一种变体,其重构目标为每一个被屏蔽patch归一化的结果。具体操作是对每一个屏蔽的patch求均值和平方差,用其对该patch归一化,后表示效果更好。
Simple implementation
MAE的预训练非常简单,不需要任何稀疏操作。首先,为每个Patch生成令牌(穿过线性投射层并添加位置编码)。然后打乱这个序列,按照遮掩比例屏蔽掉一部分的Patches,这个过程对编码器相当与取样而非替换,减少计算。编码完成后,往已经编码的patches中添加掩码令牌,此时不打乱顺序并且使其和目标令牌对齐。解码器应用于整个序列。
四.ImageNet Experiments
先在ImageNet-1K上做自监督预训练,再在同样的数据集上做有标号的监督训练。有两种方法:(1)基于end to end 的微调,允许改模型中所有可学习参数(2)linear probing:只允许改最后一层的线性输出层
4.1. Main Properties
A.讲解表1:
ft表示所有可以学习的参数都跟着调,lin表示只调最后一个线性层
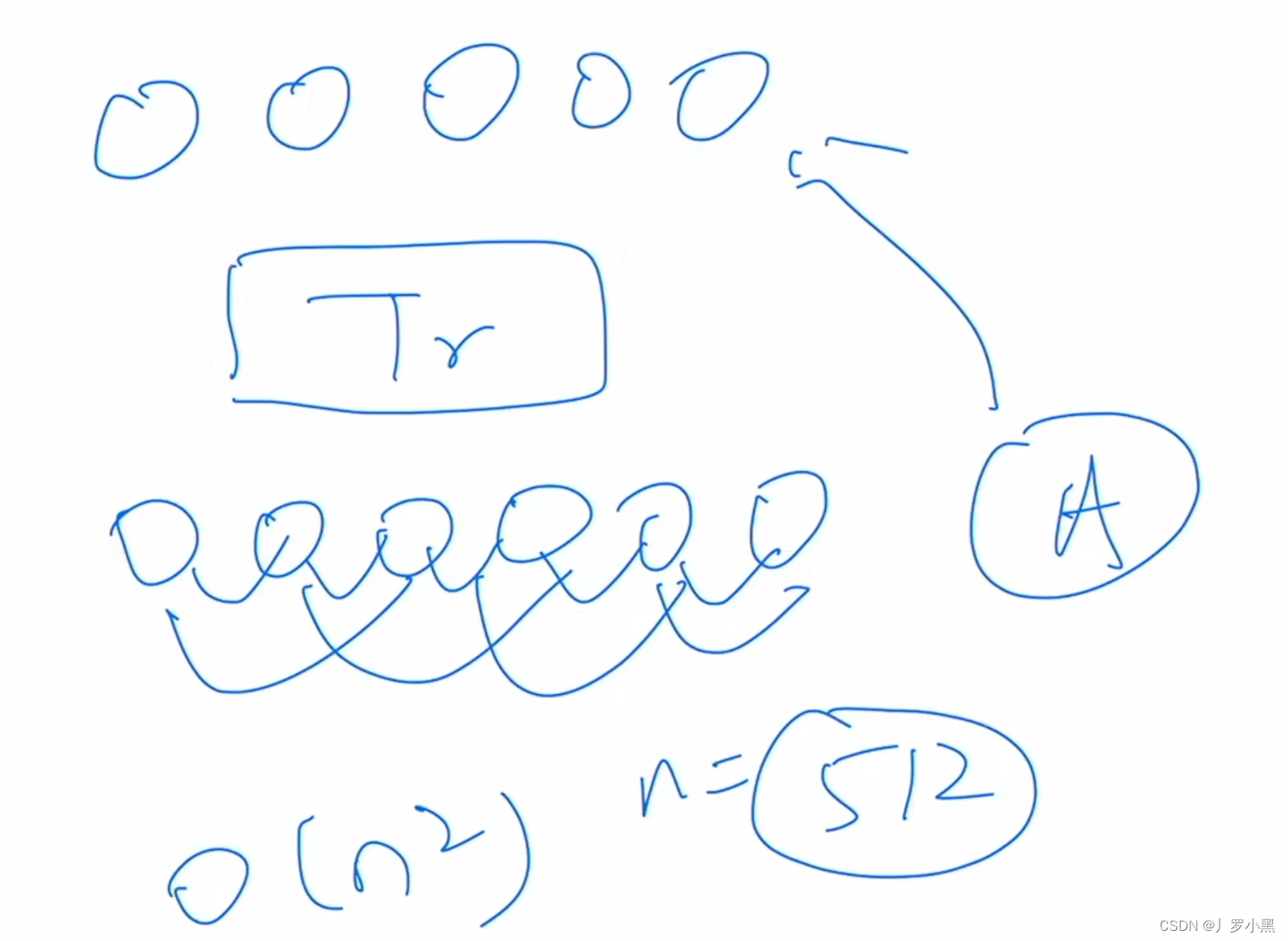
(1)表a表示解码器的深度(transformer的块数):前者比较贵,但是效果比较好。
(2)表b表示解码器的宽度(每个token表示成多长的一个向量):结果显示512比较好
(3)表c表示在编码器中要不要加入被盖住的那些块。结果显示,不加入掩码的patches,精度反而更高一些,而且计算量更少。
(4)表d表示重构目标对比。
(5)表e表示做数据增强:对比不做、按照固定大小裁剪、随机裁剪图片和加颜色的变化。结果表示简单的随机大小裁剪效果就很好,所以MAE对数据增强不敏感。
(6)表f讲的是采样策略。随机采样、按块采样和按网格采样。随机采样这种做法最简单,效果也最好。
B.掩码率

掩码率越大,不管是对fine-tune也好,还是对于只调最后一层来讲也好,效果都是比较好的。特别是只调最后一层的话,对掩码率相对来讲更加敏感一点。
C.在ImageNet-1k上训练1000个数据轮的话,仍然有精度的提升,说明在一直训练的情况下,过拟合也不是特别严重
4.2. Comparisons with Previous Results
和前人工作相比,MAE效果是最好的。
4.3. Partial Fine-tuning
五.Transfer Learning Experiment
六.Discussion and Conclusion
扩展性好的简单算法是深度学习的核心。在NLP领域中,自监督学习可以从指数型缩放模型中取得良好的效果。但在CV领域中,尽管无监督学习取得了很大的进步,但是实际的预训练范式仍然是监督学习。在本文中提出自编码器,类似于NLP领域中自监督方法。
另一方面,我们需要注意到语言和图像是不同类型的信号,而其中的差异需要认真对待。语言是含有完整的语义信息的,而图片的patch没有完整的语义信息。所以MAE重构像素并非语义。
创新点
1.写论文时,题目二选一:Scalable(模型大) OR Efficient(算法很快)。可以借鉴文章题目“**是**”,采用读者角度,将文章结论浓缩成title。
2.视觉方面的论文有图片是加分项。
3.本文采用问答式结构,问问题-回答问题-介绍出自己的观点。由于在架构上拓展少,所以回到最本质的问题,将BERT从NLP引入到CV领域中困难之处。一般的写作一定要讲清楚为什么这样做。
4.相关工作部分,需要清楚介绍别人做的和自己做的区别。
5.目前发现,一般很大的模型需要巨大的数据集来训练,如果加上合适的正则化,小的数据集也可以取得不错的效果。
知识点补充
1.自编码器:包含编码器和解码器。编码器用于将输入映射到潜在表示,解码器用于恢复输入。MAE(Masked Autoencoder)和DAE (Denoising Autoencoder)都是自编码器的变种。MAE是屏蔽掉部分输入信息,要求模型来恢复缺失部分;DAE是在输入信息中添加噪声训练模型,要求模型在恢复数据时去除噪声。
2.自***,自编码器、自回归模型:表示x和y来自于同一个东西。比如在语言模型中,预测的词和输入都是来自于该句子中的词。
核心结论
不对称的编码器-解码器结构+高比例的屏蔽图像patches
MAE的算法利用vit来做和BERT一样的自监督学习,本文在vit基础之上提出了前两点:
一是需要盖住更多的块,使得剩下的那些块,块与块之间的冗余度没有那么高,这样整个任务就变得复杂一点
二是使用一个transformer架构的解码器,直接还原原始的像素信息,使得整个流程更加简单一点
三是加上vit工作之后的各种技术,使得它的训练更加鲁棒一点。