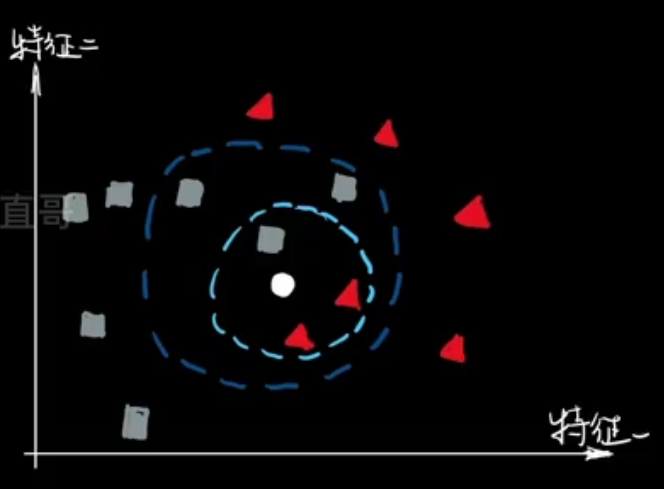
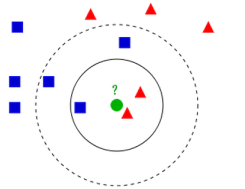
KNN算法概述
KNN(K-最近邻,K-Nearest Neighbors)是一种基本且直观的监督学习算法,用于分类和回归任务。其核心思想是:如果一个样本在特征空间中和其K个最近的邻居比较接近,那么这些邻居的标签可以用于预测该样本的标签。
算法原理
- 训练阶段:KNN算法实际上没有显式的训练过程,它只是简单地存储训练数据。
- 预测阶段:对于每个测试样本,KNN通过以下步骤进行预测:
- 计算距离:计算测试样本与所有训练样本之间的距离。
- 选择邻居:根据计算的距离,从训练集中选择距离最近的K个样本。
- 投票或平均:对于分类任务,选择K个邻居中出现次数最多的标签作为预测结果;对于回归任务,取K个邻居的平均值作为预测结果。
关键步骤详细讲解
距离计算:
最常用的距离度量是欧几里得距离(Euclidean Distance),其公式为:
d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(\mathbf{x}, \mathbf{y}) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} d(x,y)=i=1∑n(xi−yi)2
其中, x \mathbf{x} x和 y \mathbf{y} y是两个样本的特征向量, x i x_i xi和 y i y_i yi是它们在第 i i i个特征上的值。选择K个最近邻居:
对于给定的测试样本,计算它与所有训练样本的距离,并根据距离升序排序,选择前K个样本作为最近邻居。分类与回归:
- 分类任务:对于K个最近邻居中的标签进行投票,选择出现次数最多的标签作为预测结果。假设 y i y_i yi是第 i i i个邻居的标签,那么预测结果 y ^ \hat{y} y^为:
y ^ = arg max c ∈ C ∑ i = 1 K 1 ( y i = c ) \hat{y} = \arg\max_{c \in C} \sum_{i=1}^{K} \mathbf{1}(y_i = c) y^=argc∈Cmaxi=1∑K1(yi=c)
其中, C C C是所有可能的类别集合, 1 ( ⋅ ) \mathbf{1}(\cdot) 1(⋅)是指示函数,当括号内条件为真时取1,否则取0。 - 回归任务:取K个最近邻居标签的平均值作为预测结果。假设 y i y_i yi是第 i i i个邻居的标签,那么预测结果 y ^ \hat{y} y^为:
y ^ = 1 K ∑ i = 1 K y i \hat{y} = \frac{1}{K} \sum_{i=1}^{K} y_i y^=K1i=1∑Kyi
- 分类任务:对于K个最近邻居中的标签进行投票,选择出现次数最多的标签作为预测结果。假设 y i y_i yi是第 i i i个邻居的标签,那么预测结果 y ^ \hat{y} y^为:
代码实现
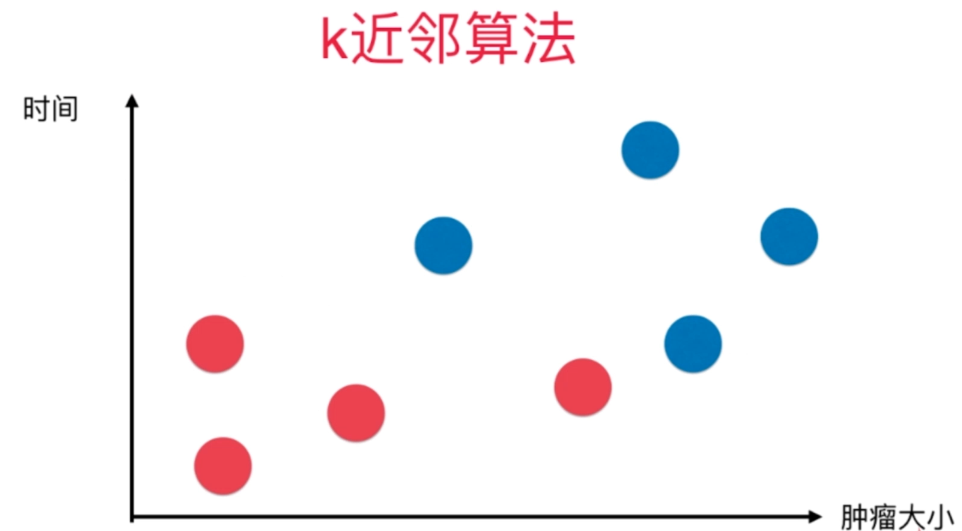
给定癌症数据集,根据数据进行KNN算法预测病人是否患癌。

代码详细讲解
这个代码段实现了一个KNN(K-最近邻)算法,用于对前列腺癌数据集进行分类预测。我们先一步步地讲解代码的每个部分,然后指出其中一些可能需要优化的地方。
1. 读取数据
import csv
import random
# 读取
with open('Prostate_Cancer.csv', 'r') as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
这部分代码使用csv.DictReader读取CSV文件,将每一行数据存储为字典,并将所有数据存储在一个列表datas中。
2. 数据分组
# 分组
random.shuffle(datas) # 洗牌
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]
这部分代码将数据集随机打乱,并将其分为训练集(train_set)和测试集(test_set)。其中,测试集占总数据的三分之一。
3. 定义距离函数
# 距离
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry",
"fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
该函数计算两个样本之间的欧几里得距离。使用了前列腺癌数据集中的八个特征:radius、texture、perimeter、area、smoothness、compactness、symmetry 和 fractal_dimension。
4. 定义KNN算法
K = 5
def knn(data):
# 1.距离
res = [
{"result": train['diagnosis_result'], "distance": distance(data, train)}
for train in train_set
]
# 2.排序-升序
sorted(res,key=lambda item:item["distance"])
# 3.取前k个
res2 = res[0:K]
# 4.加权平均
result = {"B":0,"M":0}
# 总距离
sum = 0
for r in res2:
sum += r["distance"]
for r in res2:
result[r["result"]] += 1 - r["distance"]/sum
if result["B"] > result["M"]:
return 'B'
else:
return 'M'
这个函数实现了KNN算法的核心步骤:
- 计算距离:计算测试样本与训练集中每个样本的距离。
- 排序:按距离升序排序。
- 选择最近的K个邻居。
- 加权平均:对前K个邻居的分类结果进行加权平均,距离越近权重越高。根据加权结果决定测试样本的分类。
5. 测试算法
# 测试
correct = 0
for test in test_set:
result = test['diagnosis_result']
result2 = knn(test)
if result == result2:
correct += 1
print("准确率:{:.2f}%".format(correct/len(test_set)*100))
这部分代码遍历测试集,使用KNN算法对每个测试样本进行预测,并计算准确率。
以下是用Python实现KNN算法的完整代码示例:
import csv
import random
# 读取
with open('Prostate_Cancer.csv', 'r') as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
# 分组
random.shuffle(datas) # 洗牌
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]
# KNN
# 距离
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry",
"fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
K = 5
def knn(data):
# 1.距离
res = [
{"result": train['diagnosis_result'], "distance": distance(data, train)}
for train in train_set
]
# 2.排序-升序
sorted(res,key=lambda item:item["distance"])
# 3.取前k个
res2 = res[0:K]
# 4.加权平均
result = {"B":0,"M":0}
# 总距离
sum = 0
for r in res2:
sum += r["distance"]
for r in res2:
result[r["result"]] += 1 - r["distance"]/sum
if result["B"] > result["M"]:
return 'B'
else:
return 'M'
# 测试
correct = 0
for test in test_set:
result = test['diagnosis_result']
result2 = knn(test)
if result == result2:
correct += 1
print("准确率:{:.2f}%".format(correct/len(test_set)*100))
数据集需要的可以后台私信我。
![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]练习-<span style='color:red;'>KNN</span><span style='color:red;'>算法</span>](https://img-blog.csdnimg.cn/direct/b376f7358092469a83ff03caae3d8bb4.png)

![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]<span style='color:red;'>KNN</span>——K邻近<span style='color:red;'>算法</span>实现](https://img-blog.csdnimg.cn/direct/8054effd5f304dc99ac5db8e954295f0.png)

























![[CP_AUTOSAR]_通信服务_CanTp模块(二)](https://i-blog.csdnimg.cn/direct/4eff114339c54b0eb01b893b8517b36e.png#pic_center)