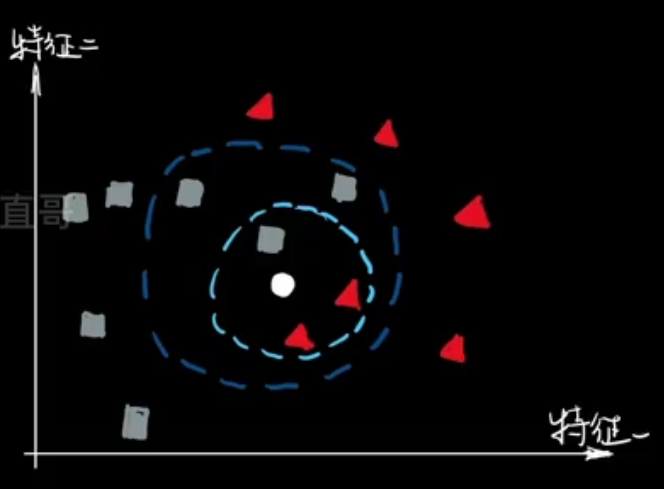
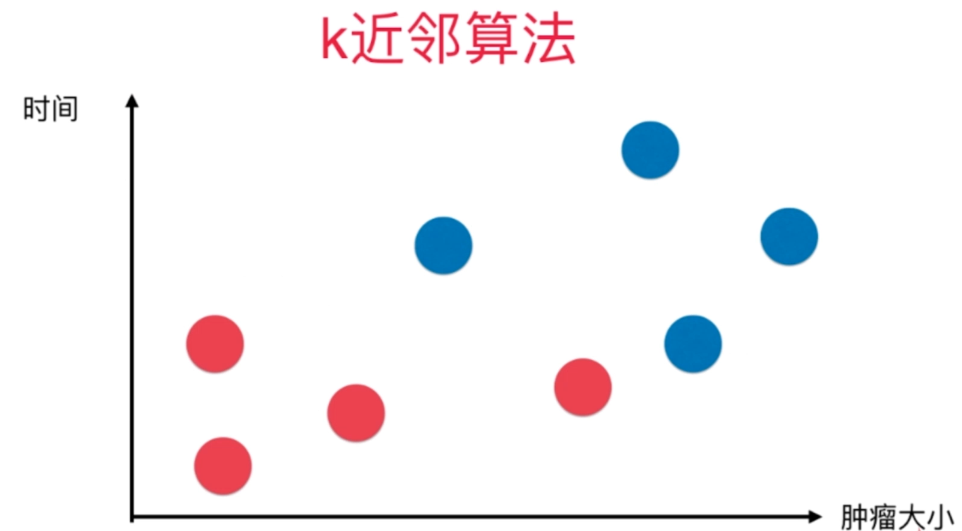
KNN(K-Nearest Neighbors)算法是一种基本的、易于理解的机器学习算法,用于分类和回归问题。在 KNN 中,一个对象的分类或值是基于其k个最近邻居的多数投票或平均值来决定的。
基本原理
- 距离度量:首先,KNN 算法需要一种方式来度量数据点之间的距离。常用的距离度量包括欧氏距离、曼哈顿距离等。
- 选择k值:k是一个超参数,表示要考虑的最近邻居的数量。k值的选择对算法的性能有很大影响。较小的k值可能导致过拟合,而较大的k值可能导致欠拟合。
- 确定邻居:对于数据集中的每个点,KNN算法都会找到其k个最近的邻居。
- 分类或回归:
- 分类:对于分类问题,KNN算法会查看k个最近邻居的类别,并将该点分类为最常见的类别。
- 回归:对于回归问题,KNN算法会计算k个最近邻居的平均值或加权平均值,并将该值作为预测值。
特点
- 简单性:KNN算法易于理解和实现。
- 懒惰学习:KNN算法属于懒惰学习或基于实例的学习,因为它不会在训练时立即进行学习,而是在查询时进行计算。
- 参数敏感:KNN算法的性能对
k值的选择和距离度量的选择非常敏感。 - 计算量大:对于大型数据集,KNN算法的计算量可能很大,因为需要计算每个查询点与所有训练点之间的距离。
应用
KNN算法在许多领域都有应用,包括图像识别、文本分类、推荐系统等。然而,由于其计算量大和参数敏感性,它可能不是所有问题的最佳选择。
优化
为了提高KNN算法的性能,可以采取以下优化措施:
- 使用KD树或球树:KD树和球树是用于在多维空间中组织点的数据结构,可以加速KNN算法中最近邻居的搜索过程。
- 调整k值:通过实验选择最适合数据集的k值。
- 特征缩放:通过标准化或归一化特征来确保所有特征在相似尺度上,从而避免某些特征对距离度量产生过大的影响。
- 减少特征数量:通过特征选择或降维技术减少特征数量,可以加快KNN算法的计算速度并提高性能。
- 使用近似算法:对于非常大的数据集,可以使用近似KNN算法来加快计算速度,例如基于哈希的近似算法或基于图的近似算法。
对于给定的实现 KNN 算法,下面使用 Python 代码来做一个简单的实现。
import random
from scipy.spatial import distance
# 设置样本集和预测数据
myDataset = {'data': [[2, 3, 0, 0], [3, 4, 0, 0], [4, 4, 0, 1], [5, 6, 0, 0]],
'target': [2, 1, 0, 1]}
x_train, y_train = myDataset['data'], myDataset['target']
x_test = [[6, 6, 0, 0], [1, 2, 0, 0]]
def knn_pre(k, x, y_train, x_train):
dis_list = []
for idx, x_train_point in enumerate(x_train):
# 计算待预测数据与各个训练数据之间的距离,这里使用欧式距离来计算
euclidean_distance = distance.euclidean(x, x_train_point)
dis_list.append((euclidean_distance, y_train[idx]))
# 按照距离的递增关系进行排序
sort_list = sorted(dis_list, key=lambda x: x[0])
# 选取与待预测数据距离最小前 K 个点
tmp_list = sort_list[:k]
# 确定前 K 个点所在类别的出现频率
fre_dict = {}
for p in tmp_list:
fre_dict[p[1]] = fre_dict.get(p[1], 0) + 1
max_value = max(fre_dict.values())
max_keys = [k for k, v in fre_dict.items() if v == max_value]
# 从个数最多的类别中随机选取一个
x_pre = random.choice(max_keys)
# 返回前 K 个点中出现频率最高的类别作为测试数据的预测分类
return x_pre
调用示例
for x in x_test:
print(knn_pre(3, x, y_train, x_train))
代码解释
- 在
knn_pre函数中,首先创建一个空列表dis_list
来存储距离和对应的类别。然后遍历训练数据,计算待预测数据与每个训练数据的欧式距离,并将距离和类别添加到列表中。 - 使用
sorted函数对距离列表按距离递增排序。 - 通过切片获取前
K个点的信息,并创建一个字典fre_dict来统计每个类别出现的频率。 - 找到频率最高的类别值,通过
random.choice函数从这些频率最高的类别中随机选择一个作为预测结果。 - 最后返回预测分类。
注意事项
- 确保输入的数据格式正确,特别是样本集和预测数据的维度和类型要符合要求。
- 选择合适的距离度量方式(这里使用了欧式距离),根据实际情况可以调整。
K的值需要根据具体问题和数据特点进行合理选择。- 随机选择频率最高的类别时,可能存在一定的不确定性,在某些情况下可能需要进一步处理或分析。
![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]练习-<span style='color:red;'>KNN</span><span style='color:red;'>算法</span>](https://img-blog.csdnimg.cn/direct/b376f7358092469a83ff03caae3d8bb4.png)
![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]<span style='color:red;'>KNN</span>——K邻近<span style='color:red;'>算法</span>实现](https://img-blog.csdnimg.cn/direct/8054effd5f304dc99ac5db8e954295f0.png)





















![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-25 多点电容触摸屏实验](https://img-blog.csdnimg.cn/direct/e3a3464b76dd42ebac99a8c5f5347434.png)





![[QT] MAC使用Qt Creator运行程序如何仅运行一个进程?](https://img-blog.csdnimg.cn/direct/5d389c39775c49ae8680af8e5c52338f.png)