💠神经网络(neural network)
神经网络是由具有适应性的简单单元组成的广泛并行互联的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络中最基本的成分是 神经元(neuron / unit),即上述定义的 “简单单元”。
💠神经元
在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个 “阈值”(threshold / bias), 那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
💠M-P 神经元模型
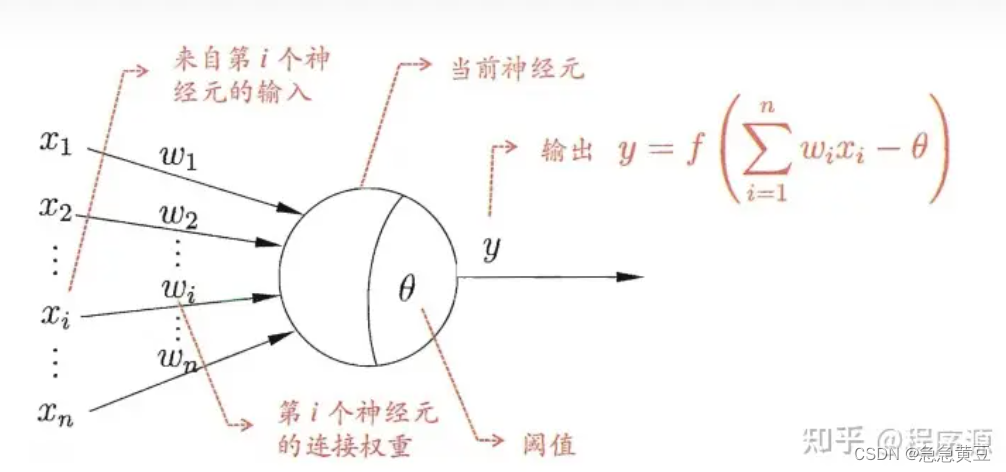
[McCulloch and Pitts, 1943] 将上述情形抽象为 “M-P 神经元模型” :

在这个模型中, 神经元接收到来自 n 个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接(connection)进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过 “激活函数” (activation function) 处理以产生神经元的输出。
💠激活函数:阶跃函数

💠激活函数:Sigmoid函数(S形函数)
由于阶跃函数具有 不连续、不光滑 等不太好的性质。因此实际常用Sigmoid函数作为激活函数:

💠感知机(perceptron)
感知机由两层神经元组成:
- 输入层:接收外界输入信号后传递给输出层。
- 输出层:一个 M-P神经元。

感知机表示 “与”、“或”、“非” 运算:
感知机可以容易地实现 与、或、非运算:
对于 y = f ( ∑ i ω i x i − θ ) y=f(\sum_i\omega_ix_i-\theta) y=f(∑iωixi−θ) 且假定其中的 f f f 是阶跃函数:
| 要表示的逻辑运算 | 数学表示 | 所用的权重与阈值 | 备注 |
|---|---|---|---|
与 |
x 1 ∧ x 2 x_1\land x_2 x1∧x2 | ω 1 = ω 2 = 1 , θ = 2 \omega_1=\omega_2=1,\theta=2 ω1=ω2=1,θ=2 | 仅在 x 1 = x 2 = 1 x_1=x_2=1 x1=x2=1 时 y = 1 y=1 y=1 |
或 |
x 1 ∨ x 2 x_1\lor x_2 x1∨x2 | ω 1 = ω 2 = 1 , θ = 0.5 \omega_1=\omega_2=1,\theta=0.5 ω1=ω2=1,θ=0.5 | x 1 = 1 x_1=1 x1=1 或 $ x_2=1$ 时 y = 1 y=1 y=1 |
非 |
¬ x 1 \lnot x_1 ¬x1 | ω 1 = − 0.6 , ω 2 = 0 , θ = − 0.5 \omega_1=-0.6, \omega_2=0,\theta=-0.5 ω1=−0.6,ω2=0,θ=−0.5 | x 1 = 1 x_1=1 x1=1 时 y = 0 y=0 y=0, x 1 = 0 x_1=0 x1=0 时 y = 1 y=1 y=1 |
感知机的学习
权重 ω i ( i = 1 , 2 , . . . , n ) \omega_i(i=1,2,...,n) ωi(i=1,2,...,n) 以及阈值 θ \theta θ 可通过学习得到。
阈值 θ \theta θ 可以看作是一个固定输入值为 -1.0 的 “哑结点(dummy node)”所对应的连接权重 ω n + 1 \omega_{n+1} ωn+1。
即:
ω 1 ⋅ x 1 + ω 2 ⋅ x 2 + . . . + ω n ⋅ x n − θ = ω 1 ⋅ x 1 + ω 2 ⋅ x 2 + . . . + ω n ⋅ x n + ω n + 1 ⋅ ( − 1.0 ) \begin{alignedat}{3} & \omega_1 \cdot x_1+\omega_2\cdot x_2 +...+\omega_n\cdot x_n-\theta \\ =& \omega_1 \cdot x_1+\omega_2\cdot x_2 +...+\omega_n\cdot x_n+\omega_{n+1}\cdot(-1.0) \\ \end{alignedat} =ω1⋅x1+ω2⋅x2+...+ωn⋅xn−θω1⋅x1+ω2⋅x2+...+ωn⋅xn+ωn+1⋅(−1.0)
所以,“权重和阈值的学习” 可以统一为 “权重的学习”。
感知机的学习规则非常简单,对于训练样本 ( x , y ) (\bold{x},y) (x,y) ,若当前感知机的输出为 y ^ \hat{y} y^ 则感知机这样调整:
ω i ← ω i + Δ ω i 其中 Δ ω i = η ( y − y ^ ) x i \omega_i \leftarrow \omega_i+\Delta\omega_i \\ 其中\Delta\omega_i=\eta(y-\hat{y})x_i ωi←ωi+Δωi其中Δωi=η(y−y^)xi
其中 η ∈ ( 0 , 1 ) \eta \in(0,1) η∈(0,1) 称为 学习率(learning rate)。通常设置为一个小的正数比如 0.1 。
💠线性可分问题(linearly separable)
线性可分:存在一个线性超平面能分开。
比如刚才提到的 与、或、非运算:

异或运算是非线性可分问题:

💠多层神经网络
感知机只拥有一层有激活函数的神经元(另一层是输入层)。其学习能力十分有限。实际上,对于 “线性可分” 问题,感知机的学习过程一定会 收敛(converge),最终求得稳定的权重值。但对于 “非线性可分” 问题,感知机的学习过程不能收敛,会发生 振荡(fluctuation),难以求得稳定的权重值。
要解决非线性可分问题,需要考虑多层神经网络。
💠隐含层(hidden layer)
输出层和输入层之间的层被称为 隐含层(hidden layer)。
隐含层和输出层神经元都是拥有激活函数的神经元。
表示“异或”运算的网络

💠多层前馈神经网络(multi-layer feedforward neural network)
更一般的,常见的神经网络如图所示:

每层神经元与下层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。这样的神经网络结构通常称为 “多层前馈神经网络”。
(其中的 “前馈” 并不意味着网络中的信号不能向后传,而是指网络拓扑结构上不存在 “环” 或 “回路”)
💠误差逆传播(error BackPropagation,简称BP)算法
多层网络学习能力比单层的感知机强得多,但需要更强大的学习算法。误差逆传播(error BackPropagation,简称BP)算法就是其中最杰出的代表,它是迄今最成功的神经网络学习算法。下面解释这个算法。
给定训练集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D=\{(\bold{x}_1,\bold{y}_1),(\bold{x}_2,\bold{y}_2),...,(\bold{x}_m,\bold{y}_m)\} D={(x1,y1),(x2,y2),...,(xm,ym)} 。
每个输入示例 x k \bold{x}_k xk 有 d d d 个属性描述,即 x k = { x 1 k , x 2 k , . . . , x d k } \bold{x}_k=\{x^k_1,x^k_2,...,x^k_d\} xk={x1k,x2k,...,xdk}
对应的每个输出示例 y k \bold{y}_k yk 是 l l l 维实值向量,即 k i = { y 1 k , y 2 k , . . . , y l k } \bold{k}_i=\{y^k_1,y^k_2,...,y^k_l\} ki={y1k,y2k,...,ylk}
下面给出一个拥有 d d d 个输入神经元, l l l 个输出神经元, q q q 个隐层神经元 的多层前馈神经网络:

其中:
θ j \theta_j θj 表示输出层第 j j j 个神经元的阈值。
γ h \gamma_h γh 表示隐层第 h h h 个神经元的阈值。
ω h j \omega_{hj} ωhj 表示隐层第 h h h 个神经元与输出层第 j j j 个神经元的连接权重。
v i h v_{ih} vih 表示输入层第 i i i 个神经元与隐层第 h h h 个神经元的连接权重。
然后:
用 β j \beta_j βj 表示输出层第 j j j 个神经元接收到的输入,即 β j = ∑ h = 1 q ω h j b h \beta_j=\sum_{h=1}^q \omega_{hj}b_h βj=∑h=1qωhjbh
用 α h \alpha_h αh 表示隐层第 h h h 个神经元接收到的输入,即 α h = ∑ i = 1 d v i h x i \alpha_h=\sum_{i=1}^dv_{ih}x_i αh=∑i=1dvihxi
也就是说,在计算上面的神经元时:
y j = f ( β j − θ j ) y_j=f(\beta_j-\theta_j) yj=f(βj−θj)
b h = f ( α h − γ h ) b_h=f(\alpha_h-\gamma_h) bh=f(αh−γh)
上述神经网络里一共要学习的参数有:
- l l l 个输出层神经元的阈值。即 θ j \theta_j θj
- q q q 个隐层神经元的阈值。即 γ h \gamma_h γh
- 隐层到输出层的 q × l q\times l q×l 个权重值。即 ω h j \omega_{hj} ωhj
- 输入层到隐层的 d × q d\times q d×q 个权重值。即 v i h v_{ih} vih
BP是一个迭代学习算法,在迭代的每一轮中采用广义的感知机学习规则对参数进行更新估计。与感知机类似,任意参数 v v v 的更新估计式为:
v ← v + Δ v v \leftarrow v+\Delta v v←v+Δv
BP算法基于 梯度下降(gradient descent) 策略,以目标的负梯度方向对参数进行调整。即对于误差 E k E_k Ek 和学习率 η \eta η ,有:
Δ v = − η ∂ E k ∂ v \Delta v=-\eta\frac{\partial E_k}{\partial v} Δv=−η∂v∂Ek
假设隐层和输出层的神经元都使用了 s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1 作为激活函数 f f f。
对于训练集 ( x k , y k ) (\bold{x}_k,\bold{y}_k) (xk,yk),假设神经网络的输出为 y ^ k = ( y ^ 1 k , y ^ 2 k , . . . , y ^ l k ) \hat{\bold{y}}_k=(\hat{y}_1^k,\hat{y}_2^k,...,\hat{y}_l^k) y^k=(y^1k,y^2k,...,y^lk),即
y ^ j k = f ( β j − θ j ) \hat{y}^k_j=f(\beta_j-\theta_j) y^jk=f(βj−θj)
而网络在 ( x k , y k ) (\bold{x}_k,\bold{y}_k) (xk,yk) 上的均方误差为:(下面式子的 1 2 \frac{1}{2} 21 没有特别的意义,可加可不加,加了后只是让求导的结果少了个系数,表示上更优雅而已)
E k = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 E_k=\frac{1}{2} \sum_{j=1}^l(\hat{y}^k_j-y^k_j)^2 Ek=21j=1∑l(y^jk−yjk)2
则可以求得,各个参数的更新公式为:
Δ ω h j = η g j b h Δ θ j = − η g j Δ v i h = η e h x i Δ γ h = − η e h 其中: g j = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) e h = b h ( 1 − b h ) ∑ j = 1 l ω h j g j \Delta\omega_{hj}=\eta g_jb_h \\ \Delta\theta_j=-\eta g_j \\ \Delta v_{ih}=\eta e_hx_i \\ \Delta\gamma_h=-\eta e_h \\ 其中:\\ g_j=\hat{y}^k_j(1-\hat{y}^k_j)(y^k_j-\hat{y}^k_j)\\ e_h=b_h(1-b_h)\sum^l_{j=1}\omega_{hj}g_j Δωhj=ηgjbhΔθj=−ηgjΔvih=ηehxiΔγh=−ηeh其中:gj=y^jk(1−y^jk)(yjk−y^jk)eh=bh(1−bh)j=1∑lωhjgj
算法:
在(0,1)范围内随机初始化网络中的所有权重和阈值
repeat
····for all ( x k , y k ) ∈ D (\bold{x}_k,\bold{y}_k) \in D (xk,yk)∈D do
········计算出当前样本的输出 y ^ k \hat{\bold{y}}_k y^k
········计算出 l l l 个 g j g_j gj
········计算出 q q q 个 e h e_h eh
········更新 θ j \theta_j θj、 γ h \gamma_h γh、 ω h j \omega_{hj} ωhj、 v i h v_{ih} vih
····end for
until 达到停止条件(比如训练误差已经达到一个很小的值)
上面介绍的是“标准BP算法”,每次针对一个样例更新参数。
“累计BP算法”:针对累计误差进行更新,即读取整个训练集一遍后才进行一轮更新。
如何设置隐层神经元的个数仍是未决的问题,实际中通常靠 “试错法”(trail-by-error) 调整。
💠缓解过拟合的策略:早停(early stopping)
将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差。若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
💠缓解过拟合的策略:正则化(regularization)
在误差目标函数中增加一个 “用于描述网络复杂度的部分”,比如“连接权与阈值的平方和”。令 ω i \omega_i ωi 表示连接权和阈值。则误差目标函数变为:
E = λ 1 m ∑ k = 1 m E k + ( 1 − λ ) ∑ i ω i 2 E=\lambda\frac{1}{m}\sum^m_{k=1}E_k+(1-\lambda)\sum_i\omega_i^2 E=λm1k=1∑mEk+(1−λ)i∑ωi2
其中 λ ∈ ( 0 , 1 ) \lambda\in(0,1) λ∈(0,1) 用于对“经验误差”与“网络复杂度”这两项折中,常通过交叉验证法来估计。
💠“全局最小” 与 “局部极小”
若用 E E E 表示神经网络在训练集上的误差,则它显然是关于 “连接权 w \boldsymbol{w} w” 和 “阈值 θ \theta θ” 的函数。那么神经网络的训练过程可以看作是一个参数寻优的过程,即在参数空间中,寻找一组最优参数使得 E E E 最小。
两种“最优”:“全局最小(global minimum)” 和 “局部极小(local minimum)”:

可能存在多个“局部极小”,但只会有一个“全局最小”。显然,我们希望找到“全局最小”。
基于梯度的搜索是使用最为广泛的参数寻优方法。负梯度就是函数下降最快的方向,因此梯度下降法就是沿着负梯度寻找最优解,最终抵达梯度为零的局部极小,更新量为零,即停止。显然,如果误差函数仅有一个局部极小,则此时找到的局部极小就是全局最小。然而,如果误差函数有多个局部极小,则不能保证我们找到了全局最小,此时我们称“陷入”了局部极小,这显然不是我们希望的。
人们常采用以下策略来试图“跳出”局部极小,从而接近全局最小:
- 以多组参数初始化多个网路。最后选择最小的。
- “模拟退火”(simulated annealing):每一步都以一定概率接收比当前解更差的结果(但是概率应该逐渐降低,从而让算法稳定)
- 使用随机梯度下降:在计算梯度时加入随机因素。
- 遗传算法
需要注意,上述用于跳出局部极小的技术大多是启发式,理论上尚缺乏保障。
其他常见神经网络
(笔者注:原文此处介绍的比较简略,有很多名词我无法理解,所以这里仅保留名字,不做更多记录)
- RBF(Radial Basis Function,径向基函数)网络
- ART(Adaptive Resonance Theory,自适应谐振理论)网络。一种竞争学习型无监督神经网络。
- SOM(Self-Organizing Map,自组织映射)网络。一种竞争学习型无监督神经网络。
- 级联相关(Cascade-Correlation)网络。是结构自适应网络的重要代表。
- Elman网络是最常用的 “递归神经网络”(允许网络中出现环形结构)
- Boltzmann机,是一种“基于能量的模型”,现实中常采用 “受限Boltzmann机”(Restricted Boltzmann Machine,简称RBM)
💠深度学习
典型的深度学习模型就是很深层的神经网络。
虽然模型复杂度可以通过单纯增加隐层神经元数目来实现,但是从增加模型复杂度的角度来看,“增加隐层数目” 显然比 “增加隐层神经元数目” 更有效,因为这还增加了激活函数嵌套的层数。
然而,多隐层神经网络难以直接用经典算法(例如标准BP算法)进行训练,因为误差在多隐层内逆传播时,往往会 “发散(diverge)” 而不能收敛到稳定状态。
多隐层神经网络的训练策略:
- 无监督逐层学习(unsupervised layer-wise training):每次训练一层隐结点,训练时将上一层隐结点的输出作为输入,而本层隐结点的输出作为下一层隐结点的输入,这称为"预训练" (pre-training);在顶训练全部完成后,再对整个网络进行"微调" (fine-tuning)训练。
- 例如在深度信念网络(deep belief network,简称DBN),每层都是一个 “受限Boltzmann机”(Restricted Boltzmann Machine)。
- 权共享(weight sharing):让一组神经元使用相同的连接权。
- 这个策略在 “卷积神经网络”(Convolutional Neural Network,简称CNN)中发挥了重要作用。
💠卷积神经网络(Convolutional Neural Network,简称CNN)
以 [LeCun et al., 1998] 《Gradient-based learning applied to document recognition》 中用CNN进行手写文字识别任务为例。


这里结合原论文的描述对每一层解释:
- 输入层: 32 × 32 32\times32 32×32 像素的图像。
- 卷积层C1:我们使用的卷积核的大小为 5×5。由于输入图片每行有32个像素,所以卷积后每行有32-5+1=28个值。即卷积后是有28×28个值的 特征映射(feature map,也成为特征图),这样特征图的每个值对应输入给一个神经元,所以共有28×28个神经元。需要注意,“权共享”意味着,这28×28个神经元将共享一个权重值。对于C1这一层,我们使用了6个特征图。所以在C1层总共需要训练的参数数量为:6个特征图×(卷积核中5×5个权重+1个阈值)=156。
- 采样层S2:采样层亦称为 “汇合” (pooling)层,其作用是基于局部相关性原理进行亚采样,从而在减少数据量的同时保留有用信息。对于S2这一层,它其中的每个神经元对应于输入的2×2邻域,所以长宽都是输入的一半,即14×14。同样,“权共享”意味着,这14×14个神经元将共享一个权重值和阈值。所以在S2层总共需要训练的参数数量为:6个特征图×(1个权重+1个阈值)=12。
- 卷积层C3。同样使用大小为5×5的卷积核。卷积后是10×10大小的特征映射。使用16个特征图。但是需要注意,并非输入的S2的6个特征图每个都与C3的16个特征图的每个相连。实际是这样:

即:前6个从S2中三个相邻的特征图获取输入。接下来的6个从S2中四个相邻的特征图获取输入。接下来的3个从四个特征图的不连续子集获取输入。最后1个从S2中所有特征图获取输入。数一数上图的X的个数,总共60个,即60个卷积核。所以在C3层总共需要训练的参数数量为:卷积核中5×5个权重×60个卷积核+16个阈值=1516。 - 采样层S4。类似S2,长宽都是输入的一半,即5×5。在S4层总共需要训练的参数数量为:16个特征图×(1个权重+1个阈值)=32。
- 卷积层C5。同样使用大小为5×5的卷积核,由于输入的S4的特征图的尺寸也是5×5,所以C5的特征图的尺寸变为了1×1。C5由120个特征图构成,与S4全连接。所以C5层总共需要训练的参数数量为:卷积核中5×5个权重×120×16+120个阈值=48120。
- 连接层F6。由84个神经元构成(为什么数目是84,原文有解释),与C5全连接。所以F6层总共需要训练的参数数量为:120×84个权重+84个阈值=10164。