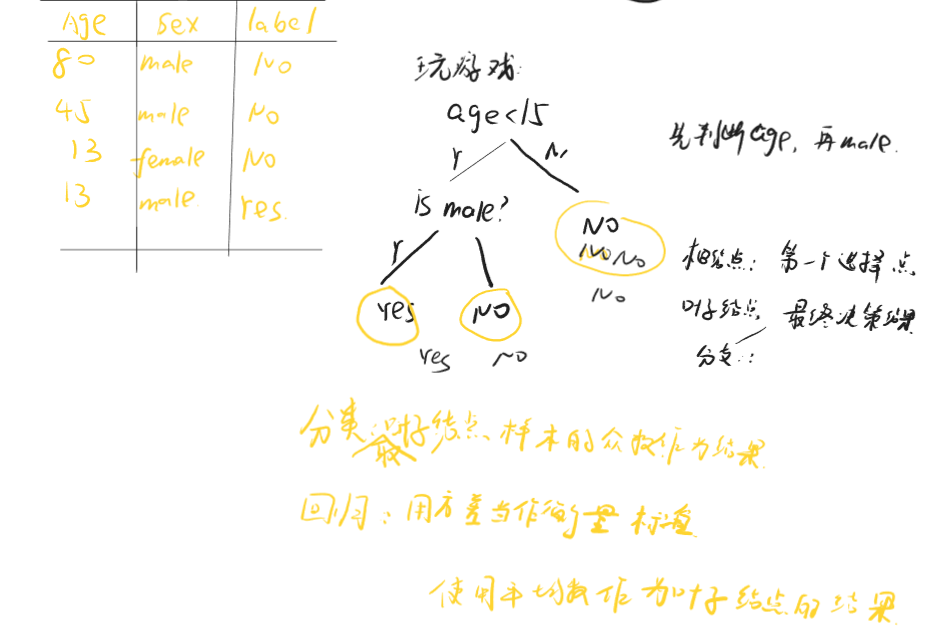
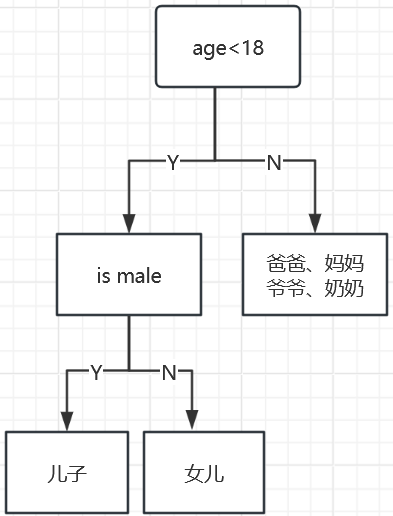
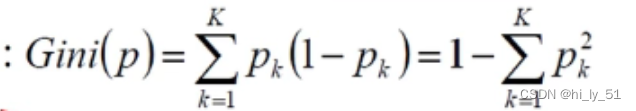💠决策树
基于树结构进行决策。
一棵决策树包括:
- 一个 根节点(起点)
- 若干 叶节点(没有下游节点的节点)
- 若干 内部节点(分支节点)
即:
💠决策树学习基本算法:分而治之(divide and conquer)
训练集: D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D=\{(\bold{x}_1,y_1),(\bold{x}_2,y_2),...,(\bold{x}_m,y_m)\} D={(x1,y1),(x2,y2),...,(xm,ym)}
其中的 y y y 是标记,即分类,其值可能是 C 1 C_1 C1、 C 2 C_2 C2、… C n C_n Cn。
其中 x \bold{x} x 的属性集 A = { a 1 , a 2 , . . . , a d } A=\{a_1,a_2,...,a_d\} A={a1,a2,...,ad}
这个算法是一个递归函数:
(笔者标记:这里的伪代码和原文不一样。一是我改变了一些表述与排版使我自己更容易理解;二是原文第12行的 “return” 我认为不对,又或者那里的 “return” 并非C++中的 “从函数返回”,而是 “从循环中返回”。不管怎样,我改成了符合C++语法习惯的伪代码)
TreeGenerate( D D D, A A A)
{
····创建一个节点 node
····if ( D D D中的样本全属于同一类别 C C C)
····{
········node = “输出是 C C C的叶节点”
········return node
····}
····if ( A A A 为空) or ( D D D在 A A A上取值相同)
····{
········令 C C C是 D D D中样本最多的分类
········node = “输出是 C C C的叶节点”
········return node
····}
····从 A A A中选择最优划分属性 a ∗ a_* a∗ (关键步骤)
····for ( a ∗ a_* a∗中的每一个值 a ∗ v a_*^v a∗v)
····{
········在 node 下创建一个分支节点 node_child,用于对应 D D D 的子集 D v D_v Dv
········其中 D v D_v Dv 表示 D D D 中在 a ∗ a_* a∗ 上取值为 a ∗ v a_*^v a∗v 的子集
········if ( D v D_v Dv 为空)
········{
············令 C C C是 D D D中样本最多的分类
············node_child = “输出是 C C C的叶节点”
········}
········else
········{
············node_child = TreeGenerate( D v D_v Dv, A ∖ { a x } A \setminus \{a_x\} A∖{ax}) (其中\意思是从集合中去掉)
········}
····}
····return node
}
从上面算法可以看出,最关键步骤是: 从 A A A中选择最优划分属性 a ∗ a_* a∗
💠纯度(purity)
我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。
💠信息熵(information entropy)
“信息熵” 是度量样本集合纯度最常用的一种指标。
在样本集合 D D D 中,用 p k ( k = 1 , 2 , . . . , ∣ Y ∣ ) p_k(k=1,2,...,|\mathcal{Y}|) pk(k=1,2,...,∣Y∣) 表第 k k k 类样本所占的比例。则 D D D 的信息熵定义为:
E n t ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k ( 约定当 p = 0 时, p log 2 p = 0 ) Ent(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_k\log_2p_k \\ (约定当 p=0 时,p\log_2p=0) Ent(D)=−k=1∑∣Y∣pklog2pk(约定当p=0时,plog2p=0)
E n t ( D ) Ent(D) Ent(D) 越小,则 D D D 的纯度越高
💠信息增益(information gain)
假定离散属性 a a a 有 V V V 个可能的取值 { a 1 , a 2 , . . . , a V } \{a^1,a^2,...,a^V\} {a1,a2,...,aV}。
若使用 a a a 对样本集 D D D 进行划分,则会产生 V V V 个分支节点,其中第 v v v 个分支节点包含了 D D D 里所有在 a a a 上取值为 a v a^v av 的样本,这个子集记为 D v D_v Dv。
可以算出它们各自的信息熵 E n t ( D v ) Ent(D_v) Ent(Dv)。又因为每个分支节点所包含的样本数目不同,所以再乘算上权重 ∣ D v ∣ ∣ D ∣ \frac{|D^v|}{|D|} ∣D∣∣Dv∣。
最终,就可以计算出当使用 a a a 对样本集 D D D 进行划分时,所获得的 “信息增益”:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^V\frac{|D^v|}{|D|}Ent(D_v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
信息增益越大,则表示用 a a a 来进行划分所获得的纯度提升越大。所以在之前算法里 “从 A A A中选择最优划分属性 a ∗ a_* a∗” 的步骤中就可以选择纯度提升最大的 a a a。著名的 ID3 决策树学习算法[Quinlan,1986] 就是以此为准则来选择划分的属性。
💠增益率(gain ratio)
实际上,“信息增益” 的准则对可取值数目较多的属性有偏好。为减少此不利影响,可以使用“增益率”,定义为:
G a i n _ r a i o ( D , a ) = G a i n ( D , a ) I V ( a ) 其中: I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ Gain\_raio(D,a)=\frac{Gain(D,a)}{IV(a)} \\ 其中:IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}\log_2\frac{|D^v|}{|D|} Gain_raio(D,a)=IV(a)Gain(D,a)其中:IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
I V ( a ) IV(a) IV(a) 被称为属性 a a a 的“固有值(intrinsic value)”,通常属性取值数目越多( V V V越大)则 I V ( a ) IV(a) IV(a) 越大。
但需要注意,“增益率” 的准则对可能取值数目较少的属性有所偏好。C4.5 算法使用了一个启发式[Quinlan,1993]:先找出信息增益高于平均水平的属性,然后再从中选择增益率最高的。
💠基尼指数(Gini index)
数据集 D D D 的纯度可用“基尼值”来度量:
G i n i ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 \begin{aligned} Gini(D) & = \sum_{k=1}^{|\mathcal{Y}|}\sum_{k'\ne k}p_kp_{k'} \\ & = 1- \sum_{k=1}^{|\mathcal{Y}|}{p_k}^2\\ \end{aligned} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′=1−k=1∑∣Y∣pk2
直观来说 G i n i ( D ) Gini(D) Gini(D) 反映了从数据集 D D D 中随机抽取两个样本,其类别标记不一致的概率。因此 G i n i ( D ) Gini(D) Gini(D) 越小,数据集 D D D 纯度越高。
类似,属性 a a a 的 基尼指数(Gini index) 定义为:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini\_index(D,a)=\sum_{v=1}^V\frac{|D^v|}{|D|}Gini(D_v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
于是,在侯选属性集合 A A A 中,我们选择划分后基尼系数最小的属性。
💠剪枝(pruning)
决策树学习有时会出现决策树分支过多,也就是 “过拟合” 的情况。
剪枝(pruning)是决策树学习中对付 “过拟合” 的主要手段。
💠预剪枝(prepruning)
在决策树生成过程中,对每个节点在划分前先进行估计,如果不能带来泛化性提升,则停止划分并直接标记为叶节点。
优点:
- 减少训练开销。
缺点:
- 欠拟合风险。
💠后剪枝(post-pruning)
先生成一颗完整的决策树,然后自底向上地对非叶节点进行考察。若将该节点对应地子树替换为叶节点可以带来泛化性提升,则替换为叶节点。
优点:
- 欠拟合风险很小。泛化性能往往优于预剪枝。
缺点:
- 训练时间要大很多。
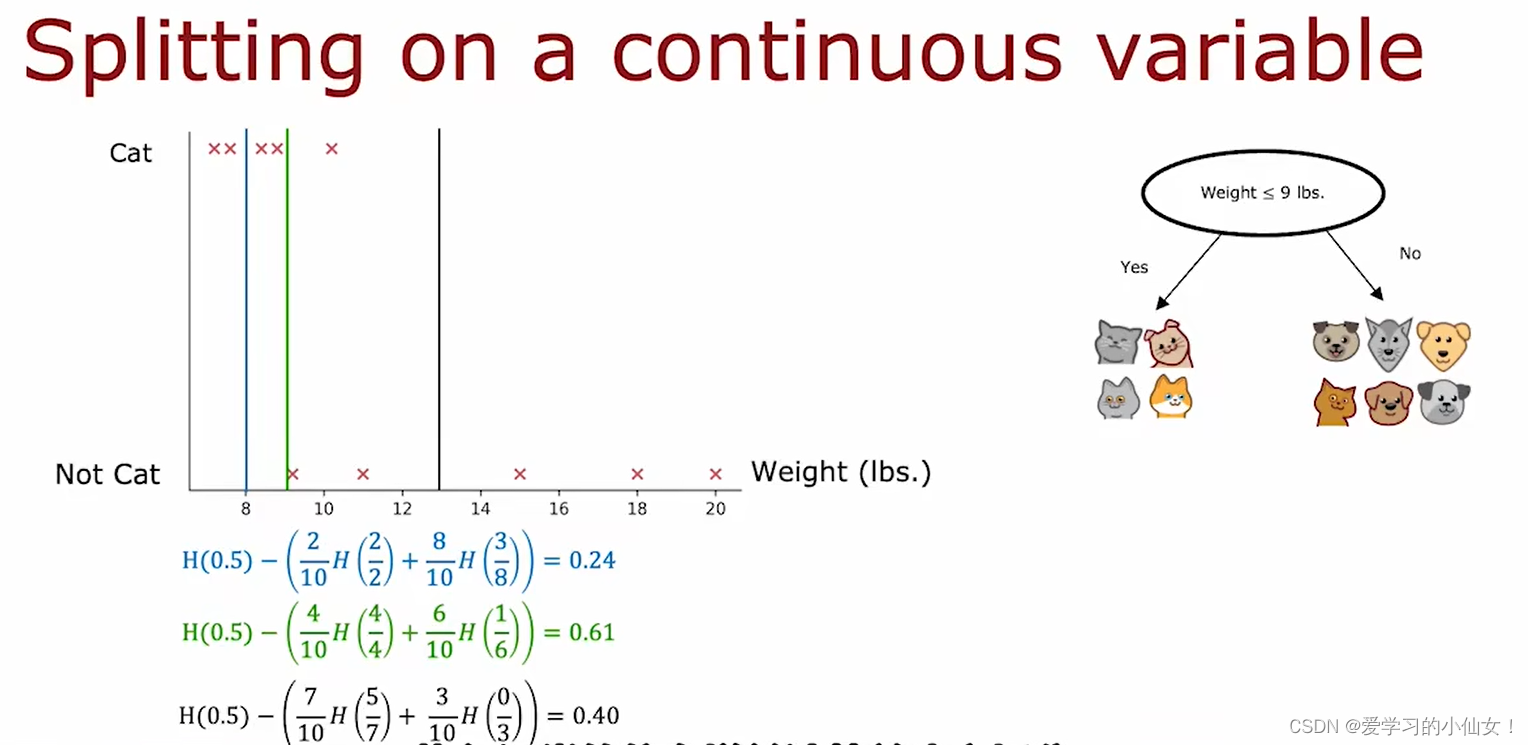
💠连续值处理:二分法(bi-partition)
当属性是连续值时,由于可取值的数目不再有限,因此无法再根据这个属性对节点进行划分。
此时可以用 “离散化技术”。最简单的策略是 二分法,C4.5决策树算法中采用了这个机制。
给定样本集 D D D 和连续属性 a a a 。假定 a a a 在 D D D 上出现了 n n n 个不同的取值,将这些值从小到大进行排序,记为 { a 1 , a 2 , . . . , a n } \{a^1,a^2,...,a^n\} {a1,a2,...,an}。基于划分点 t t t 可将 D D D 划分为子集 D t − D_t^- Dt− 和 D t + D_t^+ Dt+,分别表示哪些在属性 a a a 上 “不大于 t t t” 和 “大于 t t t”的样本。显然, t t t 在区间 [ a i , a i + 1 ) [a^i,a^{i+1}) [ai,ai+1) 中取任意值的划分结果相同。因此,我们考察的候选划分点集合:
T a = { a i + a i + 1 2 ∣ 1 ⩽ i ⩽ n − 1 } T_a=\{\frac{a^i+a^{i+1}}{2}|1\leqslant i\leqslant n-1\} Ta={2ai+ai+1∣1⩽i⩽n−1}
随后,就可以像离散属性值一样考察这些划分点,选出最优的划分点对样本集合进行划分了。
需要注意,不同于离散属性,若当前节点划分属性为连续属性,后续节点仍旧可以用这个属性进行划分。
💠缺失值处理
样本的某些属性可能出现缺失,如果简单放弃不完整的样本,显然是对数据信息极大的浪费。
考虑有缺失值的训练样本进行学习,需要解决两个问题:
(问题1)如何选择用于划分的属性?
给定训练集 D D D 和属性 a a a。 a a a 有 V V V 个可能的取值 { a 1 , a 2 , . . . , a V } \{a^1,a^2,...,a^V\} {a1,a2,...,aV}。分类取值为 ( k = 1 , 2 , . . . , ∣ Y ∣ ) (k=1,2,...,|\mathcal{Y}|) (k=1,2,...,∣Y∣)。令:
D ~ \tilde{D} D~ 表示 D D D 在 a a a 上没有缺失值的样本子集。
D ~ v \tilde{D}^v D~v 表示 D ~ \tilde{D} D~ 在 a a a 上取值为 a v a^v av 的子集。
D ~ k \tilde{D}_k D~k 表示 D ~ \tilde{D} D~ 属于 k k k 类的子集。
假定每个样本 x \bold{x} x都有一个权重 ω x \omega_{\bold{x}} ωx。然后定义:
ρ \rho ρ 表示无缺失值样本所占的比例,即: ρ = ∑ x ∈ D ~ ω x ∑ x ∈ D ω x \rho=\frac{\sum_{\bold{x}\in\tilde{D}}\omega_{\bold{x}}}{\sum_{\bold{x}\in D}\omega_{\bold{x}}} ρ=∑x∈Dωx∑x∈D~ωx
p ~ k \tilde{p}_k p~k表示无缺失值样本中第 k k k 类所占的比例,即 p ~ k = ∑ x ∈ D ~ k ω x ∑ x ∈ D ~ ω x \tilde{p}_k=\frac{\sum_{\bold{x}\in\tilde{D}_k}\omega_{\bold{x}}}{\sum_{\bold{x}\in \tilde{D}}\omega_{\bold{x}}} p~k=∑x∈D~ωx∑x∈D~kωx
r ~ v \tilde{r}_v r~v表示无缺失值样本中在属性 a a a 上取值为 a v a^v av 的样本所占的比例,即 r ~ v = ∑ x ∈ D ~ v ω x ∑ x ∈ D ~ ω x \tilde{r}_v=\frac{\sum_{\bold{x}\in\tilde{D}^v}\omega_{\bold{x}}}{\sum_{\bold{x}\in \tilde{D}}\omega_{\bold{x}}} r~v=∑x∈D~ωx∑x∈D~vωx
基于上述定义,用属性 a a a 进行划分的信息增益的计算公式推广为:
G a i n ( D , a ) = ρ × G a i n ( D ~ , a ) = ρ × ( E n t ( D ~ ) − ∑ v = 1 V r ~ v E n t ( D ~ v ) ) 其中: E n t ( D ~ v ) = − ∑ k = 1 ∣ Y ∣ p ~ k log 2 p ~ k \begin{aligned} Gain(D,a) & = \rho \times Gain(\tilde{D},a) \\ & = \rho \times (Ent(\tilde{D})-\sum_{v=1}^V \tilde{r}_vEnt(\tilde{D}^v))\\ \end{aligned}\\ 其中:Ent(\tilde{D}^v)=-\sum_{k=1}^{|\mathcal{Y}|} \tilde{p}_k\log_2\tilde{p}_k Gain(D,a)=ρ×Gain(D~,a)=ρ×(Ent(D~)−v=1∑Vr~vEnt(D~v))其中:Ent(D~v)=−k=1∑∣Y∣p~klog2p~k
接着就可以正常计算出用哪个属性进行划分最好了
(问题2)若样本在该属性上缺失,则应该划分到哪个分支节点?
采用以下逻辑:
- 假如样本 x \bold{x} x 在属性 a a a 上已知,则正常划分到对应分支节点,权重值保持为 ω x \omega_{\bold{x}} ωx。
- 假如样本 x \bold{x} x 在属性 a a a 上缺失,则将 x \bold{x} x 划分到所有的分支节点,并将 a v a^v av 对应的分支节点中的权重值调整为 r ~ v ⋅ ω x \tilde{r}_v \cdot \omega_{\bold{x}} r~v⋅ωx。
💠多变量决策树
上面所讨论的都是单变量的决策树,也就是每个分支节点都使用一个属性进行划分。
若我们把每个属性视为坐标空间中的一个坐标轴,则 d d d 个属性描述的样本就对应了 d d d 维空间中的一个点。对样本分类意味着在这个空间中寻找不同样本间的分类边界。单变量的决策树所形成的分类边界的特点是:分类边界是与坐标轴平行的(axis-parallel)。举例:
左图是决策树,右侧是其对应的分类边界:

但是,当学习任务的真实分类边界 比较复杂时,必须使用很多段划分才能获得较好的近似,如下图:

其中绿线是真实的分类边界。
此时如果还使用单变量的决策树,则会需要很多分段。可以看到黑线有9段。
但如果使用多变量的决策树,则只需要3段。红线代表使用多变量决策树的分类边界。
在多变量决策树中,每个分支节点不再是针对于一个属性,而是对属性的线性组合进行测试,即每个分支节点都是一个形如 ∑ i = 1 d ω i a i = t \sum_{i=1}^d\omega_ia_i=t ∑i=1dωiai=t 的线性分类器,其中 ω i \omega_i ωi 是 a i a_i ai 的权重, ω i \omega_i ωi 和 t t t 都是学习所得。
这样,对于之前的样本,学习成多变量决策树如左图,对应的分类边界如右图: