基础介绍
Copy-On-Write
Copy-On-Write:顾名思义,就是在写入的时候进行复制,最初是计算机领域用来解决读多写少场景下的并发访问控制问题的
如下,在Copy-On-Write模式下,用户写数据时,会先将原始数据Copy出一份副本,此时其他用户读数据时仍然读取的是原始的数据;之后进行写的用户对副本进行修改,修改完成以后,将访问指向的原始数据替换为修改后的数据;替换完成后,用户访问都会访问这个被修改过的数据
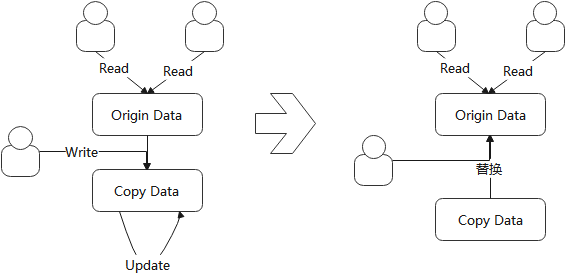
Copy-On-Write在读多写少的场景下可以提供有效的性能,因为读操作不受影响,可以一直正常访问资源数据。
Copy-On-Write主要有两个缺点:
- 内存占用。因为需要对数据Copy出一份副本进行修改,需要额外的内存资源
- 实时性。由于在修改完成前读到的都是修改前的原始数据,所以在修改期间的数据访问实际访问的都是旧数据
Java中的Copy-On-Write
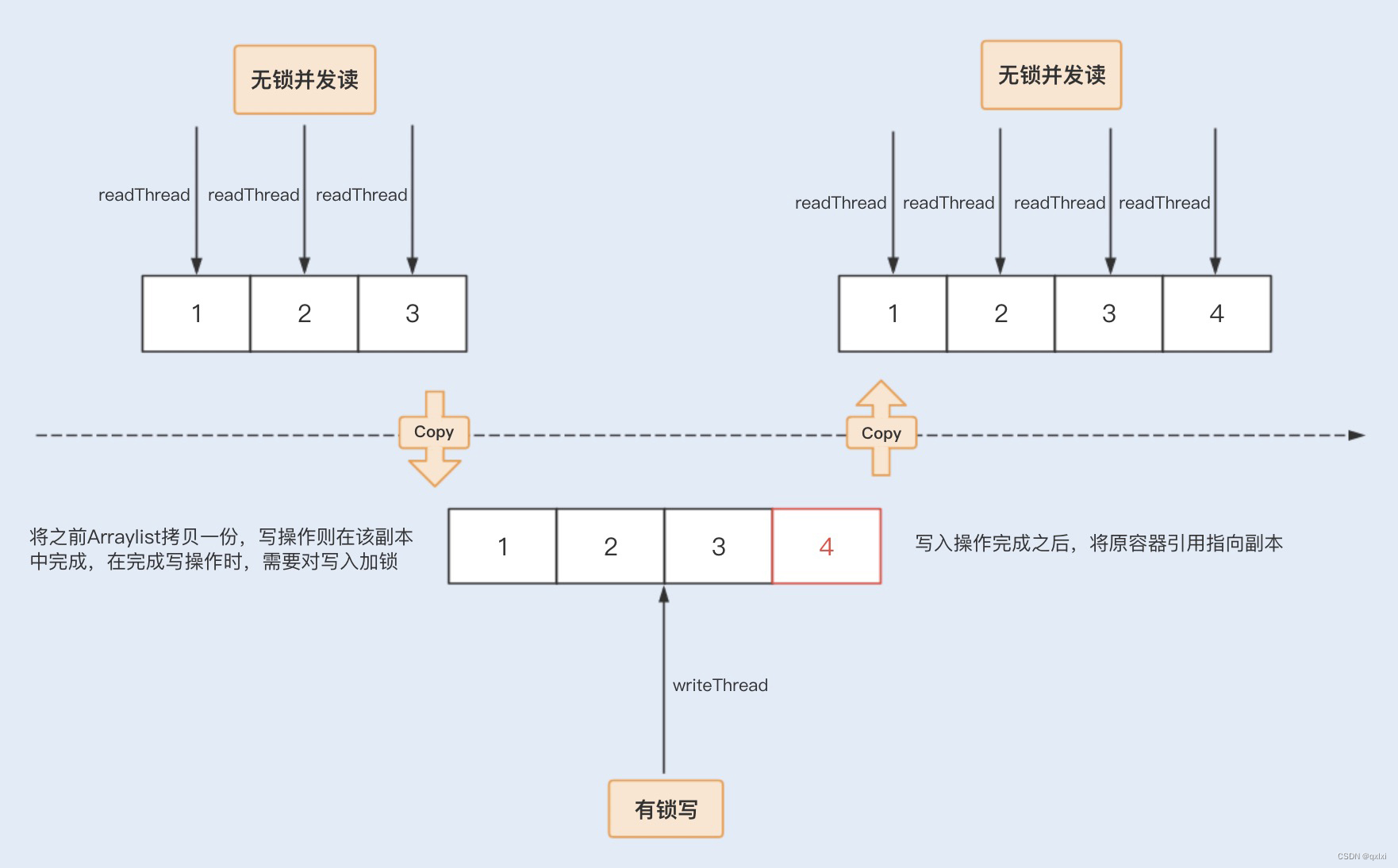
JDK中有很多高级特性的实现类,其中就有实现了copy-on-write的List:CopyOnWriteArrayList
在CopyOnWriteArrayList的add方法中,对整个数据操作过程进行了加锁操作,操作过程中copy了副本进行修改;而get方法没有任何限制,直接返回数据
add方法的实现大略如下,整体就是{加锁-copy副本-修改-回写}四个步骤
public boolean add(E e) {
final ReentrantLock lock = this.lock; lock.lock();
try {
Object[] elements = getArray(); int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}get方法就是直接返回数据,不受写的影响
private E get(Object[] a, int index) {
return (E) a[index];
}Iceberg的Copy-On-Write
在Iceberg中,Copy-On-Write是用来进行数据的行级更新的。由于Iceberg是以文件为粒度组织的,所以Iceberg的Copy-On-Write以文件为粒度进行副本的Copy,需要额外做的工作就是数据文件的发现
以Update语句来说,整体流程如下
- Update更新前会先根据SQL语句中的where条件去扫描符合的文件
- 将符合的文件中的数据全部读出,并基于SQL语句内容进行数据的修改
- 将修改后的数据写入新文件
- 最后进行元数据的生成。Iceberg自身对数据文件有管理,此处简单理解就是标记文件是Add(新增)、Existing(已经存在)、Delete(删除)等;Iceberg在此处会将原始读取的文件标记为Delete,新写的文件标记为Add,不曾变更的文件标记为Existing
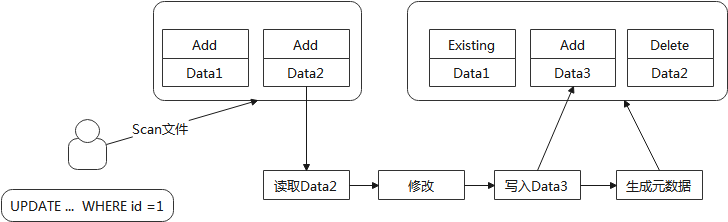 从流程上可以看出,Copy-On-Write会Copy并保存历史旧数据,所以存在写放大的问题
从流程上可以看出,Copy-On-Write会Copy并保存历史旧数据,所以存在写放大的问题
Iceberg Copy-On-Write用法
Iceberg支持Copy-On-Write和Merge-On-Read两种模式,Merge-On-Read只能在V2版本下使用。
Copy-On-Write是默认规则,存在相关配置,但目前配置项只有Spark使用了
相关的配置项有两个层面的:
- 是配置读写模式,即配置使用Copy-On-Write还是Merge-On-Read,相关配置项为:write.delete.mode、write.update.mode、write.merge.mode
- 是配置隔离级别,有serializable和snapshot。serializable是默认值,粒度更细,当存在更新操作冲突时必然失败;而snapshot相对粒度更大,冲突时可能会成功
示例进行如下操作,创建一张表,写入数据并更新指定行:
CREATE TABLE sampleSpark3 (
id bigint COMMENT 'unique id',
data string)
USING iceberg TBLPROPERTIES ('format-version'='2');
insert into sampleSpark3 values (1, 'name1'),(99, 'name99');
update sampleSpark3 SET data = 'update' WHERE id =1;Iceberg的snapshot、manifest list、manifest、datafile四层文件分别表现如下
- snapshot,最新的json元数据文件中会有两个snapshot,分别指向第一次的insert操作和第二次的update操作。需要关注的是operation字段,insert对应的是append,update对应的是overwrite
- manifest-list,最新的snapshot指向一个manifest-list,其中包含两个manifest,需要注意的是字段content都为0(0=data, 1=deletes)。added_*_count、deleted_*_count分别显示了对应的manifest增/删的数据量
- manifest,两次操作对应出来了两个manifest文件。需要注意的是status字段,分别为2和1(0=existing、1=added、2=deleted);此外还有data_file中的content字段为0(0=data, 1=position deletes, 2=equality deletes)
- datafile,datafile有两个,分别是insert产生的一个文件和update 产生的一个文件。其中在manifest里标记deleted的文件是insert时产生的,内容是(1, 'name1'),(99, 'name99');标记added的是update时产生的,内容为(1, 'update'),(99, 'name99')
Spark实现流程
使用Spark执行Update语句时,其流程核心与几个Iceberg的优化器关联较大,分别为:RewriteUpdateTable、RowLevelCommandScanRelationPushDown、ExtendedV2Write、ExtendedDataSourceV2Strategy
RewriteUpdateTable
这个规则中主要完成整个作业执行计划的框架构建
update语句经过SQL解析转换生成UpdateIcebergTable,进入RewriteUpdateTable规则后走的是buildReplaceDataPlan分支,构建replace的执行计划形式,结果如下
ReplaceIcebergData RelationV2[id#0L, data#1] spark_catalog.icedb.sampleSpark3 spark_catalog.icedb.sampleSpark3
+- Project [if ((id#0L = cast(1 as bigint))) id#0L else id#0L AS id#7L, if ((id#0L = cast(1 as bigint))) update2 else data#1 AS data#8, _file#4, _pos#5L]
+- RelationV2[id#0L, data#1, _file#4, _pos#5L] spark_catalog.icedb.sampleSpark3 spark_catalog.icedb.sampleSpark3RowLevelCommandScanRelationPushDown
前文介绍过,Iceberg的Copy-On-Write流程是一个先进行数据查询再进行数据写入的过程,此处就是完成Scan扫描类的具体化
主要做两件事:
- 扫描的过滤条件则设置,注意这里的过滤条件是直接来源于command,原因是执行计划中的过滤条件可能不适配
- 创建具体Scan实现类,这个就是调用Iceberg中的相应实现类接口
最终的执行计划如下
ReplaceIcebergData RelationV2[id#0L, data#1] spark_catalog.icedb.sampleSpark3 spark_catalog.icedb.sampleSpark3
+- Project [id#0L, if ((id#0L = 1)) update2 else data#1 AS data#8, _file#4, _pos#5L]
+- RelationV2[id#0L, data#1, _file#4, _pos#5L] spark_catalog.icedb.sampleSpark3ExtendedV2Writes
前面完成了Scan扫描类的具体化,此处完成Write写的具体化,最终将读写的实现类统一在了ReplaceIcebergData对象当中
val write = writeBuilder.build()
val newQuery = DistributionAndOrderingUtils.prepareQuery(write, query, r.funCatalog)
rd.copy(write = Some(write), query = Project(rd.dataInput, newQuery))ExtendedDataSourceV2Strategy
此步骤完成了向物理执行计划的转换,前文的一些列转换的结果是ReplaceIcebergData,对应转换为ReplaceDataExec
最终的执行逻辑在Spark的代码逻辑当中,ReplaceDataExec的父类V2ExistingTableWriteExec
首先生成一个查询的RDD
val rdd: RDD[InternalRow] = {
val tempRdd = query.execute()
if (tempRdd.partitions.length == 0) {
sparkContext.parallelize(Array.empty[InternalRow], 1)
} else {
tempRdd
}
}之后基于查询的RDD,进行写操作
sparkContext.runJob(
rdd,
(context: TaskContext, iter: Iterator[InternalRow]) =>
task.run(writerFactory, context, iter, useCommitCoordinator, writeMetrics),delete和add标志
前文介绍过,操作最终会产生两个Manifest文件,其中一个的状态位是delete一个是add,标志位的判断操作是在commit当中完成的,在CopyOnWriteOperation的commit当中
设置delete标记就是从前面的scan扫描任务当中获取文件列表生成manifest并标记delete
return scan.tasks().stream().map(FileScanTask::file).collect(Collectors.toList());设置add就是将此处新写的文件生成manifest并标记add。此处新增文件的获取就是二阶段提交中第一阶段的结果,也就是写完数据以后的数据文件信息
其他流程
serializable和snapshot的差别
前文介绍copy-on-write的粒度有两个,serializable和snapshot
两者的差别就是对标记为delete的数据文件的存在性的校验,serializable会进行校验,snapshot不会进行校验
如何优化扫描
Copy-On-Write相对来说是对读有优化,不需要在读的时候进行数据合并操作。按照前文的逻辑写完数据以后,实际可见有两份数据文件:一个add的最新数据,一个delete的旧数据
由于add的最新数据是全量的可用数据,所以Iceberg在读的时候就省略了delete文件的读取,具体在扫描的时候通过接口设置
DataTableScan.doPlanFiles是扫描获取文件列表的接口,其中有如下设置
ManifestGroup manifestGroup =
new ManifestGroup(io, dataManifests, deleteManifests)
.caseSensitive(isCaseSensitive())
.select(scanColumns())
.filterData(filter())
.specsById(table().specs())
.scanMetrics(scanMetrics())
.ignoreDeleted()
.pushDownIndex(useIndex && pushdownEnable);![<span style='color:red;'>writing</span> classes ... [xxx <span style='color:red;'>of</span> xxxx] 执行时间太长](https://img-blog.csdnimg.cn/c780ad8e2579461aac48270e619b9f94.png)






























![[python]gdal安装后测试代码](https://i-blog.csdnimg.cn/direct/66375076a5b94c54aa4df8204bbbae13.png)




