数据仓库和Apache Hive:使用Hive进行数据仓库管理
目录
引言
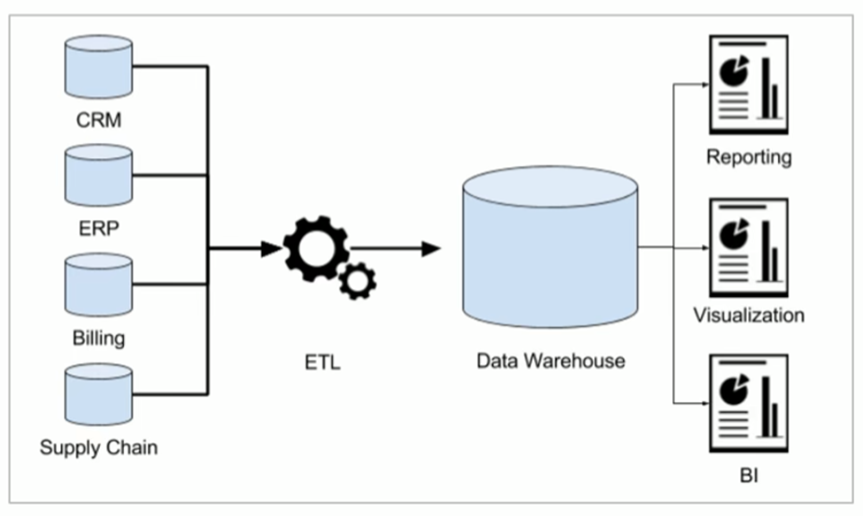
在大数据时代,数据仓库是企业进行数据存储、管理和分析的重要工具。Apache Hive作为一种基于Hadoop的高层次数据仓库解决方案,提供了方便的SQL查询接口,使用户能够在海量数据上执行复杂的分析和查询任务。本文将详细介绍数据仓库的基本概念,Apache Hive的特点和架构,以及如何使用Hive进行数据仓库管理。
数据仓库简介
数据仓库的定义
数据仓库是一种面向主题的、集成的、稳定的、随时间变化的数据集合,用于支持企业的决策分析过程。数据仓库通过从各种数据源中抽取、转换和加载数据,提供一个集中、统一的数据存储和管理平台。
数据仓库的特点
- 面向主题:数据仓库的数据是围绕特定主题组织的,如销售、客户等。
- 集成性:数据仓库整合了来自不同数据源的数据,确保数据的一致性和完整性。
- 非易失性:数据仓库中的数据是稳定的,不会因为事务操作而发生改变。
- 随时间变化:数据仓库中的数据是按时间变化组织的,能够反映历史数据的变化。
Apache Hive简介
Hive的特点
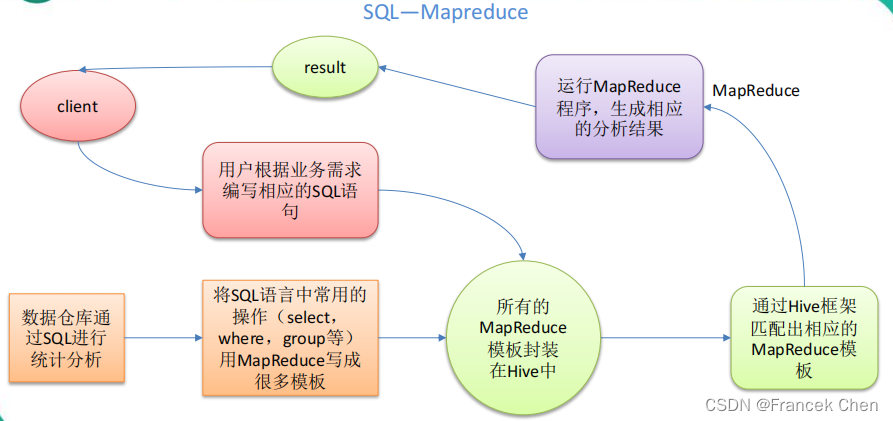
Apache Hive是一个数据仓库基础设施,基于Hadoop,用于大规模数据存储和分析。Hive提供了类似SQL的查询语言HiveQL,使用户能够轻松地在Hadoop上执行SQL查询。
- SQL接口:提供类似SQL的查询语言HiveQL,降低了大数据分析的学习成本。
- 与Hadoop集成:与Hadoop无缝集成,利用Hadoop的分布式存储和计算能力。
- 可扩展性:支持大规模数据的存储和处理,能够处理PB级别的数据。
- 可扩展的存储格式:支持多种存储格式,如文本文件、ORC、Parquet等。
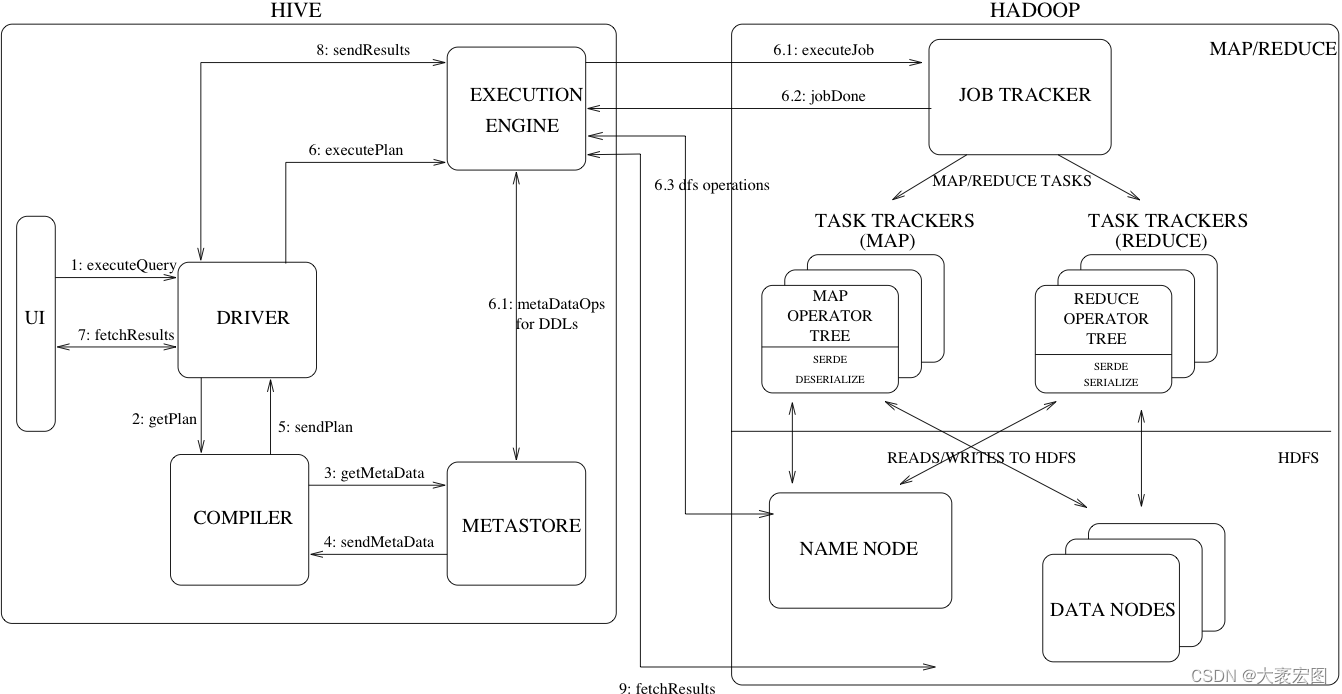
Hive的架构
Hive的架构主要包括以下组件:
- 元数据存储(Metastore):存储关于数据库、表、列、分区等的元数据。
- HiveQL处理器:解析、优化和执行HiveQL查询。
- 执行引擎:将HiveQL查询转换为MapReduce、Tez或Spark任务,并在Hadoop集群上执行。
- 客户端接口:提供CLI、JDBC、ODBC等多种访问接口。
安装和配置Apache Hive
安装Hive
在Ubuntu上安装Hive
- 安装Java和Hadoop:
sudo apt update
sudo apt install openjdk-8-jdk
sudo apt install hadoop
- 下载并解压Hive:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar -xzf apache-hive-3.1.2-bin.tar.gz
sudo mv apache-hive-3.1.2-bin /usr/local/hive
- 配置环境变量:
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$PATH
在CentOS上安装Hive
- 安装Java和Hadoop:
sudo yum install java-1.8.0-openjdk
sudo yum install hadoop
- 下载并解压Hive:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar -xzf apache-hive-3.1.2-bin.tar.gz
sudo mv apache-hive-3.1.2-bin /usr/local/hive
- 配置环境变量:
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$PATH
配置Hive
- 配置Metastore:
sudo vi $HIVE_HOME/conf/hive-site.xml
添加以下内容:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>username</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>Password to use against metastore database</description>
</property>
- 初始化Metastore:
schematool -initSchema -dbType mysql
Hive的数据仓库管理
创建数据库和表
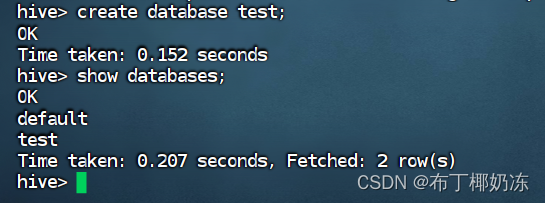
创建数据库
CREATE DATABASE mydatabase;
创建表
CREATE TABLE mytable (
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
数据导入和导出
导入数据
LOAD DATA LOCAL INPATH '/path/to/data.csv' INTO TABLE mytable;
导出数据
INSERT OVERWRITE DIRECTORY '/path/to/export'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT * FROM mytable;
查询和分析
基本查询
SELECT * FROM mytable WHERE age > 30;
聚合查询
SELECT age, COUNT(*) FROM mytable GROUP BY age;
Hive的高级功能
分区和分桶
创建分区表
CREATE TABLE mypartitionedtable (
id INT,
name STRING
)
PARTITIONED BY (age INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
加载分区数据
LOAD DATA LOCAL INPATH '/path/to/data.csv' INTO TABLE mypartitionedtable PARTITION (age=30);
用户定义函数(UDF)
Hive支持用户定义函数(UDF),用户可以创建自定义的函数来处理特定的业务逻辑。
创建UDF
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class MyUpper extends UDF {
public Text evaluate(Text input) {
if (input == null) return null;
return new Text(input.toString().toUpperCase());
}
}
注册UDF
CREATE FUNCTION myupper AS 'com.example.hive.udf.MyUpper' USING JAR 'hdfs:///path/to/udf.jar';
使用UDF
SELECT myupper(name) FROM mytable;
与Hadoop生态系统的集成
Hive可以与Hadoop生态系统中的其他组件(如HDFS、MapReduce、YARN、HBase等)无缝集成,提供强大的数据处理能力。
应用场景和最佳实践
Hive的应用场景
- 数据分析:适合进行大规模数据的批处理和分析,如数据仓库中的ETL过程。
- 报表生成:支持复杂的SQL查询,适合生成各种数据报表。
- 日志分析:能够高效处理和分析服务器日志数据,帮助企业进行运维监控和故障排查。
最佳实践
- 优化查询性能:通过使用分
区和分桶、优化查询语句、合理配置Hive参数等方式,提高查询性能。
2. 数据安全:通过配置权限管理和数据加密,确保数据的安全性和隐私性。
3. 监控和维护:定期监控Hive的运行状态,及时进行维护和优化,确保系统的稳定性和高效性。
结论
Apache Hive作为一个强大的数据仓库解决方案,能够帮助企业高效管理和分析大规模数据。通过详细介绍Hive的安装配置、基本使用和高级功能,本文旨在帮助读者全面了解和掌握Hive的使用方法,为企业的数据仓库管理提供有力支持。
通过对Hive的深入探讨,本文希望读者能够充分利用Hive的优势,实现大规模数据的高效管理和分析,提升企业的数据处理能力和决策水平。