GPT-4o mini的成本比GPT-3.5 Turbo低了超过60%,其聊天表现优于Google的Gemini Flash和Anthropic的Claude Haiku。该模型从周四开始对ChatGPT的免费用户、ChatGPT Plus用户和团队订阅用户开放,并将在下周向企业用户开放。OpenAI计划未来将图像、视频和音频功能整合到该模型中。
OpenAI在美东时间周四推出了“GPT-4o mini”,加入了“小而精”AI模型的竞争,称其为“功能最强、成本较低的模型”,并计划未来整合图像、视频和音频。
比GPT-3.5 Turbo便宜超过60%,聊天表现优于竞品
公司表示,GPT-4o mini从周四起向ChatGPT的免费用户、ChatGPT Plus和团队订阅用户开放,并将在下周向企业用户开放。GPT-4o mini将替代ChatGPT中的旧模型GPT-3.5 Turbo。OpenAI表示,GPT-4o mini的成本为每百万输入标记(token)15美分和每百万输出标记60美分,比GPT-3.5 Turbo便宜超过60%。
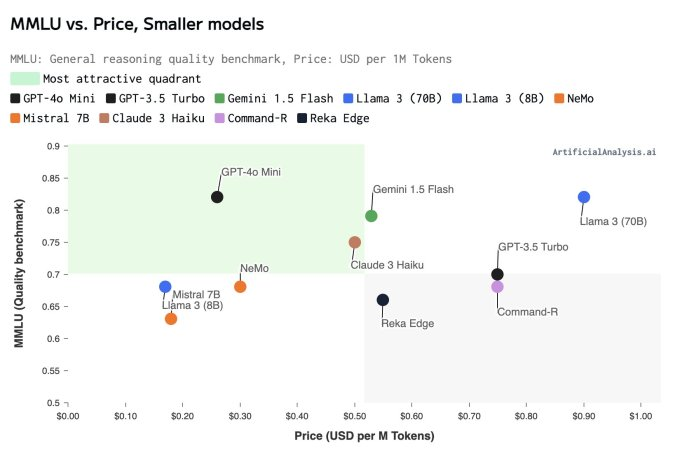
公司还指出,新模型在聊天偏好上表现优于GPT-4,并在大规模多任务语言理解(MMLU)测试中获得82%的得分。媒体报道,MMLU是一种用于评估语言模型能力的基准测试。更高的MMLU得分表明它在各种领域中的语言理解和使用能力更强,增强了其实际应用价值。
根据OpenAI的数据,GPT-4o mini模型的得分为82%,比Google的Gemini Flash(77.9%)和Anthropic的Claude Haiku(73.8%)得分更高。
在更大模型中,GPT-3.5在该测试中的得分为70%,GPT-4o得分为88.7%,而Google声称其Gemini Ultra取得了90%的最高得分。
分析认为,较小的语言模型需要较少的计算能力,使其成为资源有限的公司部署生成式AI的更实惠选择。
此外,这款新模型还将在API中支持文本和视觉功能,OpenAI表示,它将很快处理多模态输入和输出,如视频和音频。这些功能可能使其像更强大的虚拟助手,能够理解旅行行程并提出建议。目前,该模型主要用于简单任务。
“小而精”AI模型竞争激烈,OpenAI最后入局
媒体报道,OpenAI的估值已超过800亿美元,尽管在生成式AI市场占据领先地位,但面临越来越大的竞争压力。OpenAI需要找到盈利方式,因为在处理器和基础设施上花费了大量资金来构建和训练模型。
许多公司无法负担大型、昂贵的模型,因此轻量且廉价的模型可能更受欢迎。此前,许多开发人员会选择Claude 3 Haiku或Gemini 1.5 Flash,而不是支付运行最强大模型的高昂计算成本。例如,一个较小的模型可能最适合自动化处理大量基础任务,而较大的模型则处理更复杂的工作。一些开发人员可能希望在一个应用程序中同时使用这两种模型。
OpenAI的API产品负责人Olivier Godement在接受采访时解释了为何公司未能更早推出“小而精”的AI模型,他说,这纯粹是“优先级”的问题,因为公司专注于创建更大、更好的模型,如GPT-4,这需要大量人力和计算资源。随着时间推移,OpenAI注意到开发人员越来越渴望使用较小的模型,因此公司决定现在是开发GPT-4o Mini的时机。
“我们的使命是开发最前沿技术,构建最强大、最有用的应用程序,我们希望继续推动技术进步,”Olivier Godement在接受采访时说。“但我们也希望拥有最好的小模型,我认为它会非常受欢迎。”
“GPT-4o Mini真正体现了OpenAI让AI更加普及的使命。如果我们希望AI惠及世界的每一个角落、每一个行业、每一个应用,我们必须让AI更加实惠。”Olivier Godement对媒体表示。
GPT-4o mini能帮助员工专注
Godement表示,过去一周内,一些开发人员已经在试用该模型。
OpenAI让金融科技初创公司Ramp测试了该模型,使用GPT-4o Mini构建了一个提取收据上费用数据的工具。用户可以上传收据照片,模型会为他们整理数据。电子邮件客户端Superhuman也测试了GPT-4o Mini,并用它创建了一个自动建议邮件回复的功能。
最初,GPT-4o mini将能够处理和生成文本和图像。最终版本完成后,OpenAI表示它将能够处理其他类型的内容。
OpenAI还表示,GPT-4o mini是公司首个使用新安全策略“指令层级”的AI模型。这种方法旨在优先处理某些指令,如来自公司的指令,以防止工具被滥用。
分析认为,GPT-4o mini模型是OpenAI致力于“多模态性”的一部分,即提供广泛类型的AI生成媒体(如文本、图像、音频和视频)在一个工具中。
去年,OpenAI首席运营官Brad Lightcap告诉媒体:
“世界是多模态的。如果你考虑我们作为人类处理和参与世界的方式,我们看见东西,听到东西,说话——世界不仅仅是文本。因此,对我们来说,只有文本和代码作为单一模态、单一接口,感觉总是不完整的,因为这些模型的强大能力和它们能做的事情远远不止于此。”
























![[图解]《分析模式》漫谈16-“我用的”不能变成“我的”](https://i-blog.csdnimg.cn/direct/84127434e99b411abaf0fff28e38c22e.png)