今天给一个python程序添加数据排名,需要使用pandas的rank()函数,使用时发现现排名输出跟自己预想的不太一样,随后在网上查了一下使用方法,发现很多网友介绍这个函数,有的写的异常详细,有的超级简略,最后又看了一下pandas上的说明文档,感觉学习函数最好的方法还是看官方说明文档。
下面代码中的参数,使用的都是默认参数,学习一个函数,不系统了解一下各种参数,上来直接用,就有可能出现意想不到的结果。
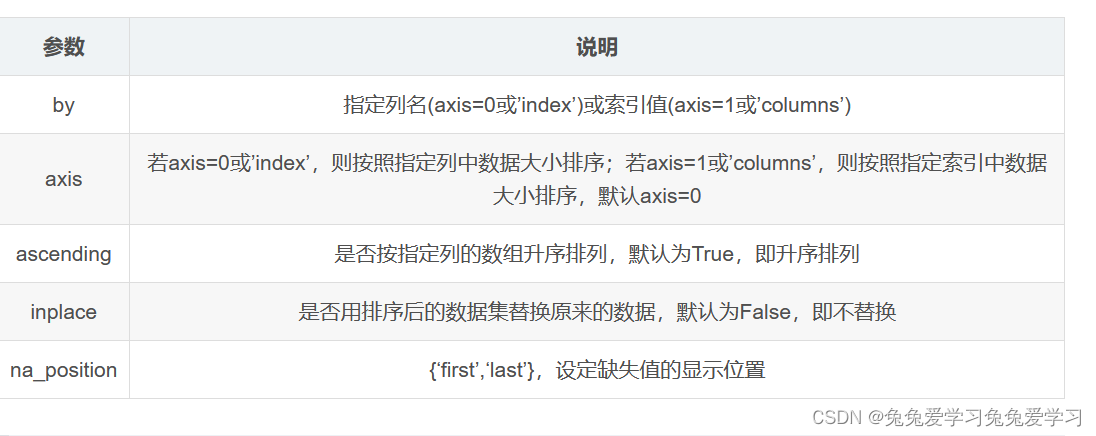
DataFrame.rank(axis=0, method='average', numeric_only=False, na_option='keep', ascending=True, pct=False)Compute numerical data ranks (1 through n) along axis.
By default, equal values are assigned a rank that is the average of the ranks of those values.
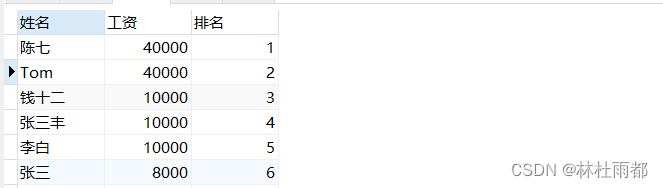
老外的排名习惯好象跟中国真不太一样。遇到相同的成绩,我们一般都是作为并列第几名,老外默认是把所有相同成绩占据的位次取平均数,真是挺有意思的。
Parameters:
axis:{0 or ‘index’, 1 or ‘columns’}, default 0
Index to direct ranking. For Series this parameter is unused and defaults to 0.
method:{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}, default ‘average’
How to rank the group of records that have the same value (i.e. ties):
average: average rank of the group
min: lowest rank in the group
max: highest rank in the group
first: ranks assigned in order they appear in the array
dense: like ‘min’, but rank always increases by 1 between groups.
numeric_only:bool, default False
For DataFrame objects, rank only numeric columns if set to True.
Changed in version 2.0.0: The default value of numeric_only is now False.
na_option:{‘keep’, ‘top’, ‘bottom’}, default ‘keep’
How to rank NaN values:
keep: assign NaN rank to NaN values
top: assign lowest rank to NaN values
bottom: assign highest rank to NaN values
ascending: bool, default True
Whether or not the elements should be ranked in ascending order.
pct: bool, default False
Whether or not to display the returned rankings in percentile form.
Returns:
same type as caller
Return a Series or DataFrame with data ranks as values.