分布式计算框架MapReduce和Spark:使用MapReduce和Spark进行大数据处理
目录
引言
随着大数据时代的到来,如何高效地处理海量数据成为一个重要课题。分布式计算框架MapReduce和Spark为大数据处理提供了强大的工具。本文将详细介绍MapReduce和Spark的工作原理、优缺点及其在大数据处理中的应用。
MapReduce简介
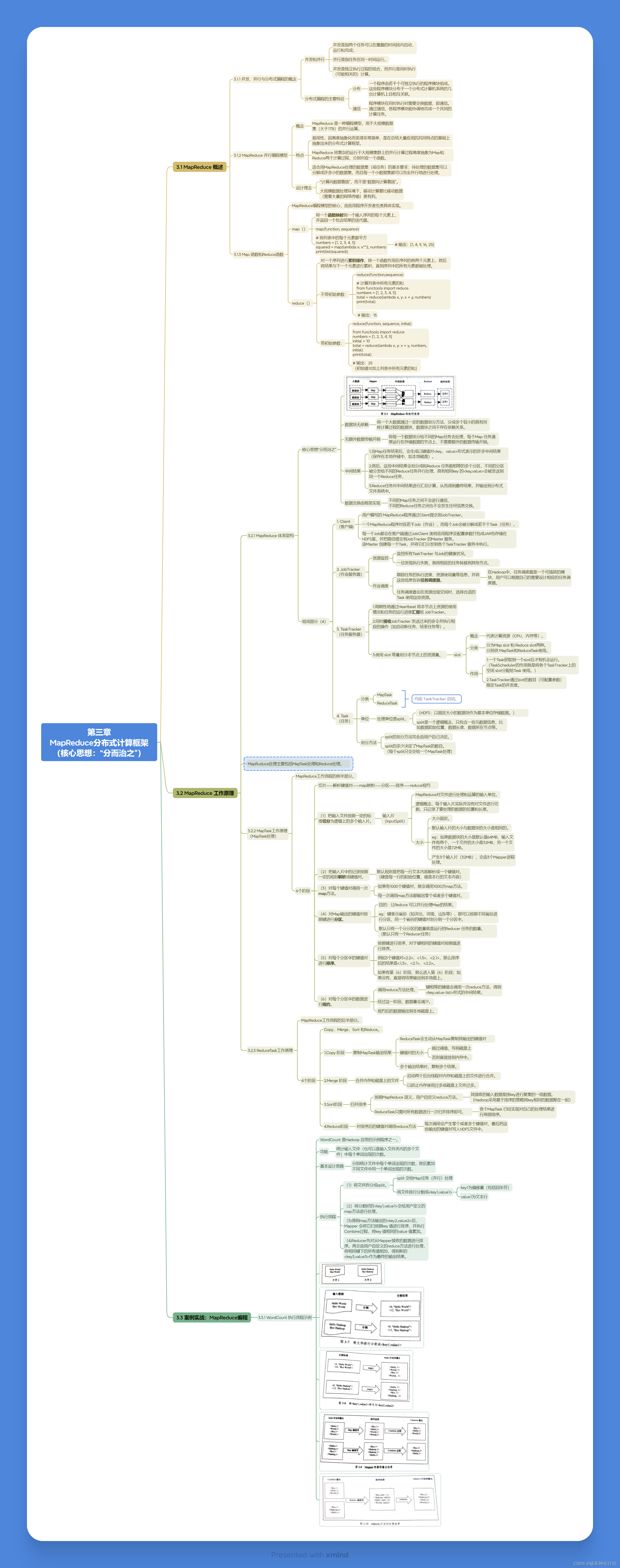
MapReduce是由Google提出的一个分布式计算模型,用于处理大规模数据集。其核心思想是将复杂的计算任务分解为简单的Map和Reduce两个阶段,通过分布式计算提高处理效率。
MapReduce的工作原理
- Map阶段:将输入数据分成多个片段,并由多个Map任务并行处理。每个Map任务将输入数据转化为键值对形式。
- Shuffle阶段:对Map输出的键值对进行分组和排序,以确保相同键的值被送到同一个Reduce任务中。
- Reduce阶段:由多个Reduce任务并行处理分组后的键值对,生成最终结果。
MapReduce的优缺点
优点:
- 可扩展性强:能够处理PB级别的数据。
- 容错性好:通过数据冗余机制确保任务在节点故障时仍能完成。
- 简单易用:编程模型简单,只需编写Map和Reduce函数。
缺点:
- 延迟较高:由于需要多次读写磁盘,处理速度相对较慢。
- 编程灵活性差:对于复杂的数据处理任务,编程较为繁琐。
MapReduce编程模型
MapReduce编程模型主要包括两个函数:Map函数和Reduce函数。
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
Spark简介
Spark是一个快速、通用的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发,现由Apache基金会维护。Spark基于内存计算,具有比MapReduce更高的处理速度和更丰富的API。
Spark的工作原理
Spark通过RDD(Resilient Distributed Datasets)实现数据的弹性分布式计算。RDD是一个不可变的分布式数据集,支持两种操作:转换操作和行动操作。转换操作生成新的RDD,而行动操作返回结果或写入外部存储。
Spark的优缺点
优点:
- 高性能:基于内存计算,比MapReduce快10倍到100倍。
- 易用性强:支持丰富的API,包括Java、Scala、Python和R。
- 编程灵活:支持批处理、流处理和图计算。
缺点:
- 内存需求高:由于基于内存计算,对内存资源要求较高。
- 复杂度较高:对于初学者,理解和调优Spark程序可能需要一定的学习成本。
Spark核心组件
- Spark Core:提供基本的分布式任务调度和内存管理。
- Spark SQL:支持使用SQL查询数据,并与Hive集成。
- Spark Streaming:用于实时数据流处理。
- MLlib:机器学习库,提供常用的机器学习算法。
- GraphX:图计算框架,适用于图数据的处理和分析。
MapReduce与Spark的比较
| 特性 | MapReduce | Spark |
|---|---|---|
| 数据处理模式 | 批处理 | 批处理、实时处理 |
| 性能 | 受限于磁盘IO | 基于内存计算,性能更高 |
| 易用性 | 相对复杂 | API丰富,使用更简单 |
| 编程语言 | Java | Scala、Java、Python、R |
| 容错机制 | 数据冗余和任务重试 | 数据冗余和任务重试 |
| 适用场景 | 海量数据的批处理 | 批处理、实时数据流处理、机器学习等 |
使用MapReduce进行大数据处理
安装和配置Hadoop
- 下载Hadoop:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- 解压Hadoop:
tar -zxvf hadoop-3.3.1.tar.gz
- 配置环境变量:
export HADOOP_HOME=/path/to/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
编写MapReduce程序
以下是一个简单的单词计数MapReduce程序:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行MapReduce任务
- 编译程序:
javac -classpath `hadoop classpath` -d wordcount_classes WordCount.java
jar -cvf wordcount.jar -C wordcount_classes/ .
- 运行MapReduce任务:
hadoop jar wordcount.jar WordCount input_dir output_dir
使用Spark进行大数据处理
安装和配置Spark
- 下载Spark:
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
- 解
压Spark:
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
- 配置环境变量:
export SPARK_HOME=/path/to/spark
export PATH=$PATH:$SPARK_HOME/bin
编写Spark程序
以下是一个简单的单词计数Spark程序:
from pyspark import SparkConf, SparkContext
# 初始化SparkContext
conf = SparkConf().setAppName("WordCount")
sc = SparkContext(conf=conf)
# 读取输入文件
input = sc.textFile("hdfs://localhost:9000/user/hadoop/input.txt")
# 进行单词计数
words = input.flatMap(lambda line: line.split(" "))
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 保存结果
wordCounts.saveAsTextFile("hdfs://localhost:9000/user/hadoop/output")
运行Spark任务
- 提交Spark任务:
spark-submit --master local[*] wordcount.py
应用案例
实时数据流处理
利用Spark Streaming,可以处理实时数据流,例如日志处理、实时数据分析等。以下是一个简单的实时单词计数示例:
from pyspark import SparkConf, SparkContext
from pyspark.streaming import StreamingContext
# 初始化SparkContext和StreamingContext
conf = SparkConf().setAppName("NetworkWordCount")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 1)
# 监听TCP端口
lines = ssc.socketTextStream("localhost", 9999)
# 进行单词计数
words = lines.flatMap(lambda line: line.split(" "))
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 打印结果
wordCounts.pprint()
# 启动流处理
ssc.start()
ssc.awaitTermination()
机器学习
利用Spark MLlib,可以实现各种机器学习算法,例如分类、回归、聚类等。以下是一个简单的线性回归示例:
from pyspark.ml.regression import LinearRegression
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder.appName("LinearRegressionExample").getOrCreate()
# 读取数据
data = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
# 分割数据集
trainData, testData = data.randomSplit([0.7, 0.3])
# 初始化线性回归模型
lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# 训练模型
lrModel = lr.fit(trainData)
# 进行预测
predictions = lrModel.transform(testData)
# 打印结果
predictions.select("label", "prediction").show()
结论
MapReduce和Spark作为两种主流的分布式计算框架,各有优劣。MapReduce适用于大规模批处理任务,具有良好的容错性和可扩展性;而Spark凭借其基于内存计算的高性能和丰富的API,适用于更广泛的数据处理场景,包括实时数据流处理和机器学习。