大家好,Jupyter notebook 是机器学习的便捷工具,但在应用部署方面存在局限。为了提升其可扩展性和稳定性,需结合DevOps和MLOps技术。通过自动化的持续集成和持续交付流程,可将AI应用高效部署至HuggingFace平台。
本文将介绍MLOps的全面实践,讲解如何将Jupyter Notebook中的机器学习模型通过自动化流程成功部署到生产环境。
1.代码迁移与自动化
在实现机器学习模型从 Jupyter Notebook 到生产环境的迁移过程中,关键在于如何将实验阶段的代码转换为可在集成开发环境(IDE)中运行的格式。
以下示例展示了一个用于图像识别的卷积神经网络(CNN)模型的迁移过程,该模型专门用于区分猫和狗的图片。
数据集地址,https://www.kaggle.com/datasets/tomasfern/oxford-iit-pets。
# src/train.py
from os.path import join
from fastai.vision.all import *
from utils import is_cat
import yaml
with open("params.yaml", "r") as stream:
params = yaml.safe_load(stream)
# 路径
data_path = join('data', 'images')
metrics_path = 'metrics'
models_path = 'models'
# 实例化数据加载器
dls = ImageDataLoaders.from_name_func(
os.getcwd(),
get_image_files(data_path),
valid_pct=params['train']['valid_pct'],
seed=params['train']['seed'],
label_func=is_cat,
item_tfms=Resize(params['train']['resize_img'])
)
print(f"Image count for dataset")
print(f"- Training: {len(dls.train_ds)}")
print(f"- Validation: {len(dls.valid_ds)}")
# 微调模型
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(0)
我们还需要一个 "准备数据" 脚本:
# src/prepare.py
import tarfile
import os
dataset = os.path.join('data','images.tar.gz')
destination = 'data'
print(f'Decompressing {dataset}...')
with tarfile.open(dataset, 'r:*') as tar:
tar.extractall(path=destination)
以及一个测试脚本:
# src/test.py
import numpy as np
from fastai.vision.all import *
from fastai.learner import load_learner
import urllib.request
import os
import sys
from utils import is_cat
import tempfile
def predict(model, url):
""" 预测 API:
(pred,pred_idx,probs) = model.predict(img)
"""
with tempfile.TemporaryDirectory() as temp_dir:
test_fn = os.path.join(temp_dir, 'test.jpg')
urllib.request.urlretrieve(url, test_fn)
f = open(test_fn, mode="rb")
data = f.read()
img = PILImage.create(data)
is_cat,_,probs = model.predict(img)
return is_cat, probs[1].item()
# 加载模型
learn = load_learner('models/model.pkl')
# 对狗的图片进行预测,期望输出为 False
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/c/c8/Black_Labrador_Retriever_-_Male_IMG_3323.jpg/2880px-Black_Labrador_Retriever_-_Male_IMG_3323.jpg"
is_cat, probs = predict(learn, url)
if is_cat is True or probs > 0.1:
print(f'Image "{url}" incorrectly labeled as cat')
sys.exit(1)
# 对猫的图片进行预测,期望输出为 True
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/1/15/Cat_August_2010-4.jpg/2880px-Cat_August_2010-4.jpg"
is_cat, probs = predict(learn, url)
if is_cat is False or probs < 0.9:
print(f'Image "{url}" incorrectly labeled as dog')
sys.exit(1)
2.数据版本控制(DVC)
在机器学习项目中,模型的构建既依赖于代码也依赖于训练数据。虽然代码可以通过Git进行有效跟踪,但数据的版本控制却不是Git的强项,尤其是面对大型数据集时。
为了解决这一问题,DVC(Data Version Control)工具应运而生。
DVC是针对AI和机器学习领域的工具,专门设计用来跟踪和管理大型文件,比如数据集和模型文件。它借鉴Git的工作方式,让我们能够通过简单的命令dvc add path/to/files来跟踪文件。执行这一命令后,文件会被哈希处理并存储到.dvc/cache目录下,而不会被提交到Git仓库中。同时,会在原文件旁边生成一个.dvc文件,记录了文件的哈希值、大小等信息,充当原始数据的指针。
执行dvc checkout命令时,DVC会根据项目中的.dvc文件,从缓存中恢复文件到它们原来的位置。由于.dvc文件会被Git跟踪,因此能够保留项目中文件变化的完整历史记录。
以一个具体的例子来说,如果我们需要下载并使用一个训练数据集,比如牛津宠物数据集的一个子集,可以通过以下命令下载:
$ wget https://huggingface.co/datasets/tomfern/oxford-pets-subset/resolve/main/images.tar.gz -O data/images.tar.gz
下载完成后,通过DVC添加到版本控制中的命令如下:
$ dvc add data/images.tar.gz
这样,数据集就被纳入了DVC的跟踪和管理之中,确保了数据的版本控制与代码的版本控制同样高效、一致。
3.ML 管道
ML 管道是 DVC 的核心特性,标志着 MLOps 实践的起点。DVC 通过定义输入输出,允许构建步骤清晰的机器学习流程,智能地识别变动并优化执行过程。
创建 ML 管道的语法简洁明了:
$ dvc stage add -n "stage name" \
-d "input file1" -d "input file2" \
-o "output file1" -o "output file2" \
command
在案例中定义了三个关键阶段:数据准备(prepare)、模型训练(train)和模型测试(test)。以下是各阶段的构建示例:
# 数据准备阶段
$ dvc stage add -n prepare \
-d src/prepare.py \
-o data/images \
python src/prepare.py
# 模型训练阶段
$ dvc stage add -n train \
-d src/train.py -d data/images \
-o models/model.pkl -o models/model.pth \
python src/train.py
# 模型测试阶段
$ dvc stage add -n test \
-d src/test.py -d models/model.pkl -d models/model.pth \
python src/test.py
执行 ML 管道时,DVC 会根据 .dvc 文件记录的依赖关系,确定哪些阶段需要更新:
$ dvc repro
这将依次执行数据准备、模型训练和测试阶段,确保每一步的输出与预期一致。例如,在训练阶段,DVC 会监控模型性能指标,并在测试阶段验证模型的准确性。
为确保 ML 管道的变更能够被版本控制系统跟踪,需要定期提交 dvc.lock 文件:
git add dvc.lock
dvc.lock 文件记录了管道的状态和输出文件的哈希值,是 ML 项目版本控制的关键。通过这种方式,DVC 使得机器学习项目的复现性和协作变得更加容易。
4.DVC 远程存储
虽然可以使用 git push 将代码保存在云端,但数据和模型文件往往需要远程存储解决方案。DVC 支持与多种云存储服务的集成,包括 AWS S3、Google Cloud Storage 和 Azure Storage。
首先,需要在云服务上配置存储桶,例如使用 AWS S3 时,可以通过以下命令列出现有存储桶:
$ aws s3 ls
配置好存储桶后,通过 DVC 添加远程存储并设置为默认:
$ dvc remote add myremote s3://mybucket
$ dvc remote default myremote
设置完成后,每次在执行 ML 管道 (dvc repro) 之前,应该先拉取远程数据 (dvc pull),执行完毕后提交更改,然后推送更新到远程存储 (dvc push)。
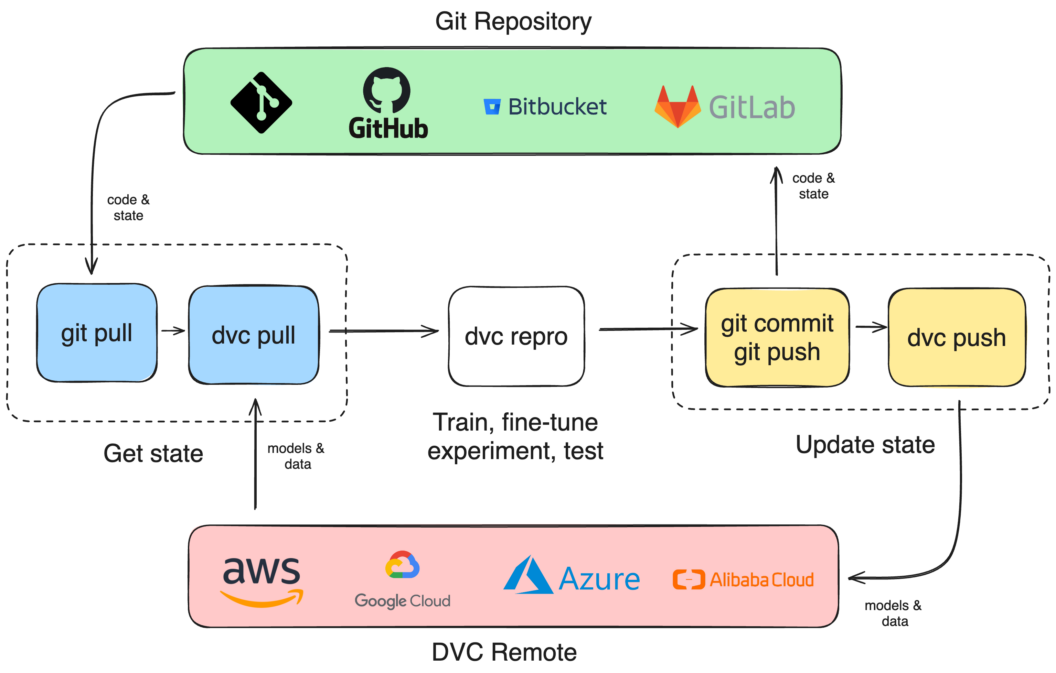
5.持续集成和部署
使用远程存储数据简化了持续集成(CI)过程中自动化训练和部署 ML/AI 模型的复杂性。以下是 CI 训练的简化工作流程:
a. 在 CI 服务器上安装 DVC。
b. 克隆代码仓库。
c. 从远程存储拉取 DVC 管理的数据。
d. 执行训练和测试脚本。
e. 将更新推送回远程仓库。
6.总结
从 Jupyter 笔记本到生产环境,运用持续集成和数据版本控制等 DevOps 工具,自动化了 AI 模型的训练与测试等常规手动流程。
掌握自动化 AI 训练的技能对于迎接即将到来的机器学习时代不可或缺。希望本文能够成为实用的指导和帮助。