目录
1.概述
1.1.前言
本文是作者大数据系列专栏的其中一篇,专栏地址:
https://blog.csdn.net/joker_zjn/category_12631789.html?spm=1001.2014.3001.5482
本文将会聊一下计算引擎MapRedduce,深入浅出快速过一遍MapReduce的核心概念和原理,不涉及具体操作,具体操作将会在下文聊。
1.2.大数据要怎么计算?
大数据集的数据是海量的,动辄几十上百TB,为了能将其存下来都是采用的分布式存储,将整个数据集分散到多个节点上去。要对其做统计之类的计算时,肯定不能数据向计算靠拢,将数据全部读到一个跑计算任务的节点上来进行计算,只能计算向数据靠拢,将计算任务放到存储数据的各个节点上去。并行的对整个大数据集进行计算,最后汇总成一个结果。
1.3.什么是MapReduce?
上面描述的过程要做的工作还是很多的,管理并行的计算任务,将任务分发到各个节点上去,最后还要汇总结果,手动编码实现整个管理过程的话还是很复杂的。mapreduce作为一个并行编程框架,帮我们屏蔽掉了这一系列实现细节,让开发人员可以借助API专注的进行计算逻辑的编写。
mapreduce分为两阶段:map、reduce。
map阶段会将计算任务分发到各个数据存储节点上去跑任务,实现对大数据集的并发处理。
reduce阶段会汇总map阶段各节点上计算任务算出来的结果,聚合成最终的结果。
上述过程不难发现,mapreduce就是个主从架构的:
master节点负责总的调度、slave节点负责具体跑任务。
master:集群内有一个master服务器、也是作业追踪器JobTracker、负责整个作业的调度和处理。
slave:集群内有多个slave服务器,也是执行具体任务的TaskTracker、负责完成具体的任务。
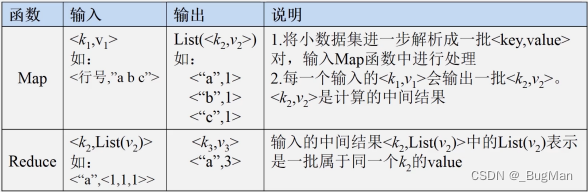
以一个分词统计的mapreduce为例:
2.架构
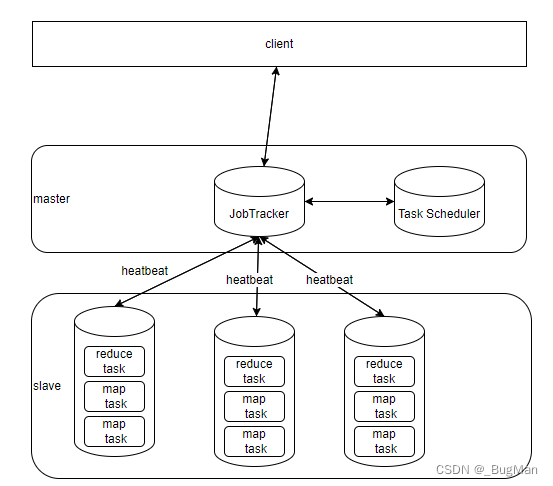
Client端将任务发给JobTracker,JobTracker负责监控Job的健康状况,控制TaskTracker。JobTracker通过心跳的方式和各个TaskTracker保持联络,TaskTracker将自身的资源使用情况、任务执行进度等信息告知JobTracker。Task Scheduler负责任务的分发规则,决定最终将任务分发给谁。
TaskTracker如何衡量自身的资源使用情况?
tasktracker会将自身所在的机器的内存、CPU等资源视为一个整体,然后将其划分为一份份的slot,根据执行job需要的资源的不同,分为两种slot,map的slot和reduce的slot。taskTracker上报的资源使用情况就是自身两类slot的使用情况。
task分为两种:map task、reduce task,对应着各自执行的是map函数、reduce函数。
3.工作流程
以下是大致过程:
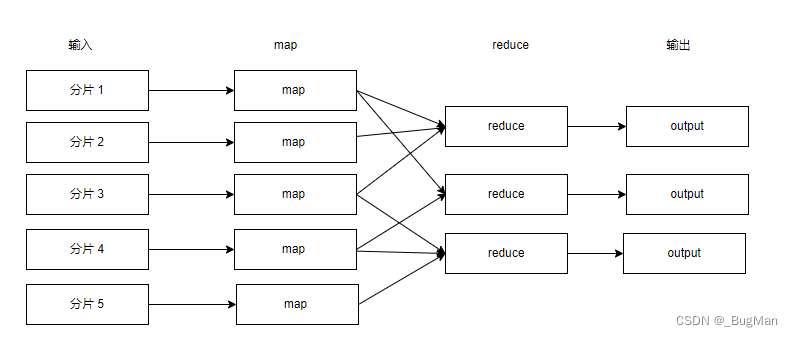
由于大数据集在存储的时候是分片开来,分布式存储的,所以对于map而言,输入就是数据分片。
注意1:
mapreduce处理的并不一定是单个数据,很可能处理的是整个大数据集,所以mapreduce面对的文件的分片数是不固定的,毕竟每一份文件的大小都不一样,分片数肯定不一样。所以map和分片之间不是一一对应的关系,不是说当前处理的文件有多少个分片就有多少个map,上面只是一个逻辑过程,后面会说map和分片的关系。
注意2:
map和reduce不一定是在一台机器上完成的。如果数据分片所在的服务器是台tasktracker并且有map solt可用,那么map肯定是在那台机器上完成的。如果那台机器不是台tasktracker或者没有map solt可用,那么会选择离那台机器最近的满足可做map任务的机器来处理map任务。也就是说一般map是和数据集呆在一起的(隔得近我们也可理解为趋近于本地),但是reduce可能是被分配到其它机器上完成的,因为reduce阶段需要传输的数据量已经不大了,输入只是个中间结果而已,这时候距离不是问题,效率是核心,谁算的快(reduce slot多)谁来。
以下是详细过程:

将文件读出来
将文件切割一下(split)
map运算(该有几个map任务?)
算出中间结果(shuffle)
reduce运算
算出最终结果
该有几个map任务?map和分片的数量是一致的吗?map和分片之间是一一对应的吗?
答案是:不是。
开多少map是不固定的,取决于有多少资源(map solt),所以才有了split这一步,split这一步会将数据进行切分,切出来的再交给各个map。每个map只专注于处理自己的要负责的split,这也避免了并发带来的数据安全问题。
4.shuffle
有没有发现mapreduce,map其实很简单,reduce也很简单,但是这个算出中间结果(shuffle)这一步有点绕。接下来我们详细拆解map和reduce和过程看看它是如何完成shuffle的。
4.1.map过程
以下展示的仅仅是一个map过程:

HDFS中的数据集输入,为了加速,对输入数据split,分为多个map来并发处理,一个map一个split。处理结果存在缓存中,溢写到磁盘上。溢写的时候进行分区、排序、合并,其中合并很重要:
合并:
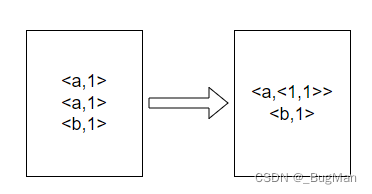
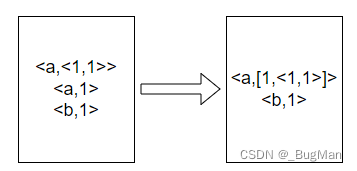
4.2.reduce过程
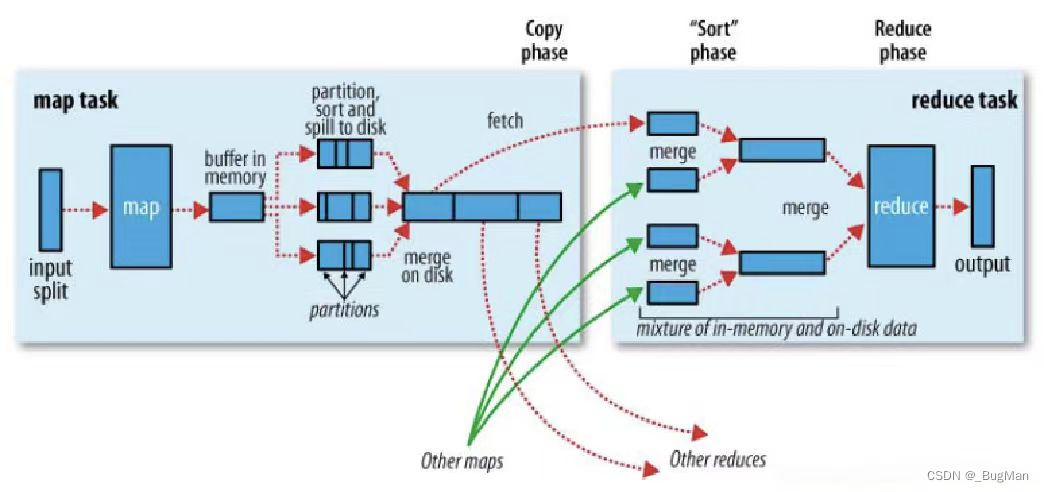
一个reduce接收的输入是来自多个map的,所以首先是将多个map传过来的结果归并起,再交给reduce来使用。下面是完整过程:
假设来自多个map的数据合起来的数据集是:
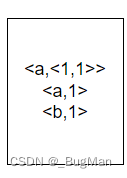
先进行排序:
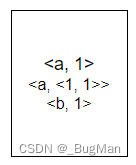
进行归并: