文章目录
理论课: C2W1.Auto-correct
0. Overview
我们每天都会在手机和电脑上使用自动更正功能。本次作业将使你了解自动更正任务。当然,这里要实现的模式与手机中使用的模式并不完全相同。
主要任务:
- 获取语料库中的单词数
- 获取语料中的单词概率
- 操作字符串
- 过滤字符串
- 实施最小编辑距离来比较字符串,并帮助找到最佳编辑路径。
- 了解动态编程的工作原理
自动更正随处可见。 例如,如果您键入**“I am lerningg ”,很有可能您想写的是“learning ”**,如下图所示。

拼音输入法也有:

0.1 Edit Distance
这里要实现的模型能修改1-2个编辑距离的单词
这里的n个编辑距离是指需要n次修改将一个单词改成另外一个单词
常见的编辑/修改操作有:
- 删除(去掉一个字母): ‘hat’ => ‘at, ha, ht’
- 调换(调换 2 个相邻字母): ‘eta’ => 'eat, tea,…‘
- 替换(将一个字母换成另一个字母): ‘jat’ => ‘hat, rat, cat, mat, …’
- 插入(添加一个字母): ‘te’ => ‘the, ten, ate, …’
使用以上四种修改操作完成Autocorrect,必须要计算在给定输入的条件下,单词正确率。
拼写检查模型的目标是计算以下概率:
P ( c ∣ w ) = P ( w ∣ c ) × P ( c ) P ( w ) (Eqn-1) P(c|w) = \frac{P(w|c)\times P(c)}{P(w)} \tag{Eqn-1} P(c∣w)=P(w)P(w∣c)×P(c)(Eqn-1)
上面也是贝叶斯公式的形式Bayes Rule
- 等式 1 表示,单词正确的概率 P ( c ∣ w ) P(c|w) P(c∣w)等于某个单词 w w w 正确的概率 P ( w ∣ c ) P(w|c) P(w∣c),乘以一般情况下正确的概率 P ( C ) P(C) P(C),再除以一般情况下该单词 w w w 出现的概率 P ( w ) P(w) P(w)。
- 要计算等式 1,首先要导入一个数据集,然后使用该数据集创建所需的所有概率。
1. Data Preprocessing
import re
from collections import Counter
import numpy as np
import pandas as pd
import w1_unittest
这里我们将使用莎翁的作品作为语料,由于涉及版权文件可行搜索下载,包含了莎士比亚的几部著名剧作的文本,包括《亨利五世》、《哈姆雷特》、《安东尼与克莉奥佩特拉》以及《终成眷属》。

1.1 Exercise 1
实现 process_data 函数,包括
- 读取语料(文本文件)
- 将所有内容改为小写
- 返回单词列表。
这里补充一部分正则表达式的知识点:
\s:这匹配任何空白字符(空格、制表符、换行符等)。它在字符类中相当于 [ \t\n\r\f\v]。
\w:这匹配任何单词字符,包括字母、数字和下划线。
\s+:这匹配一个或多个空白字符。+ 量词的意思是“一个或多个”前面的元素。
\w+:这匹配一个或多个单词字符。像 \s+ 一样,+ 量词的意思是“一个或多个”。
# UNQ_C1 GRADED FUNCTION: process_data
def process_data(file_name):
"""
Input:
A file_name which is found in your current directory. You just have to read it in.
Output:
words: a list containing all the words in the corpus (text file you read) in lower case.
"""
words = [] # return this variable correctly
### START CODE HERE ###
#Open the file, read its contents into a string variable
data = open(file_name, 'r').read()
data=str.lower(data)
# convert all letters to lower case
words= re.findall(r'\w+', data)
#Convert every word to lower case and return them in a list.
### END CODE HERE ###
return words
接下来借助集合去掉重复条目:
word_l = process_data('./data/shakespeare.txt')
vocab = set(word_l) # this will be your new vocabulary
print(f"The first ten words in the text are: \n{word_l[0:10]}")
print(f"There are {len(vocab)} unique words in the vocabulary.")
结果:
The first ten words in the text are:
[‘o’, ‘for’, ‘a’, ‘muse’, ‘of’, ‘fire’, ‘that’, ‘would’, ‘ascend’, ‘the’]
There are 6116 unique words in the vocabulary.
1.2 Exercise 2
实现返回单词词频字典的 get_count 函数
- 字典的键是单词
- 每个词的值是该词在语料库中出现的次数。
例如,给定以下句子 “I am happy because I am learning”, get_count 函数应该返回以下内容:
| Key | Value |
|---|---|
| I | 2 |
| am | 2 |
| happy | 1 |
| because | 1 |
| learning | 1 |
# UNIT TEST COMMENT: Candidate for Table Driven Tests
# UNQ_C2 GRADED FUNCTION: get_count
def get_count(word_l):
'''
Input:
word_l: a set of words representing the corpus.
Output:
word_count_dict: The wordcount dictionary where key is the word and value is its frequency.
'''
word_count_dict = {} # fill this with word counts
### START CODE HERE
for word in word_l:
if word in word_count_dict:
word_count_dict[word] += 1
else:
word_count_dict[word] = 1
### END CODE HERE ###
return word_count_dict
测试:
word_count_dict = get_count(word_l)
print(f"There are {len(word_count_dict)} key values pairs")
print(f"The count for the word 'thee' is {word_count_dict.get('thee',0)}")
结果:
There are 6116 key values pairs
The count for the word ‘thee’ is 240
1.3 Exercise 3
给定词数词典,计算从词库中随机抽取每个词出现的概率。
P ( w i ) = C ( w i ) M (Eqn-2) P(w_i) = \frac{C(w_i)}{M} \tag{Eqn-2} P(wi)=MC(wi)(Eqn-2)
其中
C ( w i ) C(w_i) C(wi) 是 w i w_i wi 在语料库中出现的总次数。
M M M 是语料库中单词的总数。
例如,在句子**‘I am happy because I am learning’**中,'am’一词的概率是:
P ( a m ) = C ( w i ) M = 2 7 . (Eqn-3) P(am) = \frac{C(w_i)}{M} = \frac {2}{7} \tag{Eqn-3}. P(am)=MC(wi)=72.(Eqn-3)
# UNQ_C3 GRADED FUNCTION: get_probs
def get_probs(word_count_dict):
'''
Input:
word_count_dict: The wordcount dictionary where key is the word and value is its frequency.
Output:
probs: A dictionary where keys are the words and the values are the probability that a word will occur.
'''
probs = {} # return this variable correctly
### START CODE HERE ###
# get the total count of words for all words in the dictionary
total=sum(word_count_dict.values())
for key, value in word_count_dict.items():
probs[key]=word_count_dict[key]/total
### END CODE HERE ###
return probs
测试:
#DO NOT MODIFY THIS CELL
probs = get_probs(word_count_dict)
print(f"Length of probs is {len(probs)}")
print(f"P('thee') is {probs['thee']:.4f}")
结果:
Length of probs is 6116
P(‘thee’) is 0.0045
2. String Manipulation
上面已经计算出了语料库中所有单词的 P ( w i ) P(w_i) P(wi),下面需要将编写四个函数来处理字符串,以便编辑错误的字符串并返回正确的单词拼写。
delete_letter: 给定一个单词,它会返回所有可能的字符串,这些字符串都去掉了1个字符。switch_letter: 给定一个单词,它会返回所有可能的字符串,这些字符串有2个相邻的字母被调换。replace_letter: 给定一个单词,它会返回1个字符被另一个不同字母替换的所有可能字符串。insert_letter: 给定一个单词,它会返回所有插入了额外1个字符的可能字符串。
List comprehensions
下面讲解在 Python 中进行字符串和列表操作,当然可以参考list comprehensions列表推导式,Python list comprehensions将循环结构嵌入到列表声明中,从而将多行代码合并为一行。不熟悉的就老老实实分开写loop,也可以看下图加强理解:

列表推导式是一种简洁的构建列表的方法,它允许你通过一个表达式和一个循环来创建列表,有时还可以包含一个条件语句。
newlist = [expression for a in something if condition]
- expression:这里是 f(a),表示对每个元素 a 应用函数 f。
- for a in something:这里 something 是一个可迭代对象,a 是从 something 中取出的元素。
- if condition:这是一个条件语句,只有满足条件的元素才会被添加到新列表 newlist 中。
当然也可以写成for循环
newlist = []
for a in something:
if condition:
newlist.append(f(a))
2.1 Exercise 4.delete_letter()
实现delete_letter()函数,例如给定单词:nice,该函数会返回集合:{‘ice’, ‘nce’, ‘nic’, ‘nie’}.大概步骤如下:
步骤1:创建一个splits列表。这包含一个单词拆分为左和右的所有情况。 例如
nice拆分为:[('', 'nice'), ('n', 'ice'), ('ni', 'ce'), ('nic', 'e'), ('nice', '')]
这是所有四个函数(delete、replace、switch、insert)都要做的。
下图是创建splits列表的两种方法示意:

步骤2:生成所有删除一个字母的单词结果,可以参考以下表达:
[f(a,b) for a, b in splits if condition]
对于单词’nice’ 可得到:[‘ice’, ‘nce’, ‘nie’, ‘nic’]

# UNIT TEST COMMENT: Candidate for Table Driven Tests
# UNQ_C4 GRADED FUNCTION: deletes
def delete_letter(word, verbose=False):
'''
Input:
word: the string/word for which you will generate all possible words
in the vocabulary which have 1 missing character
Output:
delete_l: a list of all possible strings obtained by deleting 1 character from word
'''
delete_l = []
split_l = []
### START CODE HERE ###
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1) if word[i:]]
delete_l= [(word[:i]+word[i+1:]) for i in range (len (word))]
### END CODE HERE ###
if verbose: print(f"input word {word}, \nsplit_l = {split_l}, \ndelete_l = {delete_l}")
return delete_l
测试
delete_word_l = delete_letter(word="cans", verbose=True)
结果:
input word cans,
split_l = [(‘’, ‘cans’), (‘c’, ‘ans’), (‘ca’, ‘ns’), (‘can’, ‘s’)],
delete_l = [‘ans’, ‘cns’, ‘cas’, ‘can’]
问题1
如果你的结果是:
input word cans,
split_l = [(‘’, ‘cans’), (‘c’, ‘ans’), (‘ca’, ‘ns’), (‘can’, ‘s’), (‘cans’, ‘’)],
delete_l = [‘ans’, ‘cns’, ‘cas’, ‘can’]
在你的split_l 中多了元组('cans', ''),但是对于delete_l 是没有影响的,想想为什么?
要去掉多余的元组,可以将代码:
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1)]
改成
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1) if word[i:]]
问题2
如果你的结果是:
input word cans,
split_l = [(‘’, ‘cans’), (‘c’, ‘ans’), (‘ca’, ‘ns’), (‘can’, ‘s’), (‘cans’, ‘’)],
delete_l = [‘ans’, ‘cns’, ‘cas’, ‘can’, ‘cans’]
在delete_l 中包含了原单词,说明你的范围设置有误,需要检查右边的循环不是:
word[:i]+word[i:]
而是:
word[:i]+word[i+1:]
2.2 Exercise 5.switch_letter()
现在实现一个switch_letter(),用于交换单词中的两个相邻字母。它接收一个单词,并返回一个列表,其中列出了相邻两个字母的所有可能切换。
例如,给定单词 “eta”,它会返回 {‘eat’、‘tea’},但不会返回’ate’。
步骤1:与delete_letter()相同
步骤2:使用list comprehensions列表推导式循环交换相邻字母:
[f(L,R) for L, R in splits if condition]

有没有条件判断,只会影响最后一个元组,这里不赘述,不影响最后结果
# UNIT TEST COMMENT: Candidate for Table Driven Tests
# UNQ_C5 GRADED FUNCTION: switches
def switch_letter(word, verbose=False):
'''
Input:
word: input string
Output:
switches: a list of all possible strings with one adjacent charater switched
'''
switch_l = []
split_l = []
### START CODE HERE ###
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1)]
switch_l=[(word[:i]+word[i+1]+word[i]+word[i+2:]) for i in range (len (word)-1)]
#switch_l=list(set(switch_l))
### END CODE HERE ###
if verbose: print(f"Input word = {word} \nsplit_l = {split_l} \nswitch_l = {switch_l}")
return switch_l
测试:
switch_word_l = switch_letter(word="eta", verbose=True)
结果:
Input word = eta
split_l = [(‘’, ‘eta’), (‘e’, ‘ta’), (‘et’, ‘a’), (‘eta’, ‘’)]
switch_l = [‘tea’, ‘eat’]
如果代码执行报错:
IndexError: string index out of range
请检查switch_l列表推导式中交换单词的索引是否正确。
2.3 Exercise 6.replace_letter()
实现replace_letter()函数,输入一个单词并返回一个字符串列表,列表包含被替换的一个原始字母的单词。
步骤1:与delete_letter()相同
步骤2:使用list comprehensions列表推导式循环替换原始单词的字母:
[f(a,b,c) for a, b in splits if condition for c in string]
这样的列表推导式会将原单词带来包括进来,例如:‘ear’替换第一个字母’e’,会有’ear’出现。
步骤3:去掉与原单词相同的结果。
# UNIT TEST COMMENT: Candidate for Table Driven Tests
# UNQ_C6 GRADED FUNCTION: replaces
def replace_letter(word, verbose=False):
'''
Input:
word: the input string/word
Output:
replaces: a list of all possible strings where we replaced one letter from the original word.
'''
letters = 'abcdefghijklmnopqrstuvwxyz'
replace_l = []
split_l = []
### START CODE HERE ###
alphabet=list('abcdefghijklmnopqrstuvwxyz')
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1)]
replace_set = [[word.replace(word[i],j) for j in alphabet] for i in range (len (word))]
replace_set = [item for sublist in replace_set for item in sublist]
replace_set = [x for x in replace_set if x!=word]
### END CODE HERE ###
# turn the set back into a list and sort it, for easier viewing
replace_l = sorted(list(replace_set))
if verbose: print(f"Input word = {word} \nsplit_l = {split_l} \nreplace_l {replace_l}")
return replace_l
这里重点解释三行replace_set
1.这行代码使用嵌套的列表推导式生成一个列表的列表 replace_set。对于输入单词 word 的每个字母(索引从 0 到 len(word)-1),它将该字母替换为字母表 alphabet 中的每个字母,生成一个替换后的单词列表。这样,对于每个原始字母,都会有一个由替换后的单词组成的列表。如果 word 长度为 n,则这个列表将包含 n 个子列表,每个子列表包含 26 个替换后的单词。这里的结果是列表的列表(嵌套列表)
2.第一个 replace_set 中的嵌套列表展平成一个单一的列表。它首先遍历第一个 replace_set 中的每个子列表,然后遍历每个子列表中的每个元素,将它们添加到新的列表中。因此,如果第一个 replace_set 包含 n 个子列表,每个子列表有 26 个元素,那么第二个 replace_set 将是一个包含 n * 26 个元素的单一列表。
3.这行代码使用列表推导式从 replace_set 中移除与原始单词 word 相同的字符串。这样,最终的列表只包含替换了一个字母的单词。
测试:
replace_l = replace_letter(word='can', verbose=True)
结果:
Input word = can
split_l = [(‘’, ‘can’), (‘c’, ‘an’), (‘ca’, ‘n’), (‘can’, ‘’)]
replace_l [‘aan’, ‘ban’, ‘caa’, ‘cab’, ‘cac’, ‘cad’, ‘cae’, ‘caf’, ‘cag’, ‘cah’, ‘cai’, ‘caj’, ‘cak’, ‘cal’, ‘cam’, ‘cao’, ‘cap’, ‘caq’, ‘car’, ‘cas’, ‘cat’, ‘cau’, ‘cav’, ‘caw’, ‘cax’, ‘cay’, ‘caz’, ‘cbn’, ‘ccn’, ‘cdn’, ‘cen’, ‘cfn’, ‘cgn’, ‘chn’, ‘cin’, ‘cjn’, ‘ckn’, ‘cln’, ‘cmn’, ‘cnn’, ‘con’, ‘cpn’, ‘cqn’, ‘crn’, ‘csn’, ‘ctn’, ‘cun’, ‘cvn’, ‘cwn’, ‘cxn’, ‘cyn’, ‘czn’, ‘dan’, ‘ean’, ‘fan’, ‘gan’, ‘han’, ‘ian’, ‘jan’, ‘kan’, ‘lan’, ‘man’, ‘nan’, ‘oan’, ‘pan’, ‘qan’, ‘ran’, ‘san’, ‘tan’, ‘uan’, ‘van’, ‘wan’, ‘xan’, ‘yan’, ‘zan’]
注意:如果结果中的单词比原单词长度要+1,这要检查是否对空字符进行了替换。如:
Input word = can
split_l = [(‘’, ‘can’), (‘c’, ‘an’), (‘ca’, ‘n’), (‘can’, ‘’)]
replace_l [‘aan’, ‘ban’, ‘caa’, ‘cab’, ‘cac’, ‘cad’, ‘cae’, ‘caf’, ‘cag’, ‘cah’, ‘cai’, ‘caj’, ‘cak’, ‘cal’, ‘cam’, ‘cana’, ‘canb’, ‘canc’, ‘cand’, ‘cane’, ‘canf’, ‘cang’, ‘canh’, ‘cani’, ‘canj’, ‘cank’, ‘canl’, ‘canm’, ‘cann’, ‘cano’, ‘canp’, ‘canq’, ‘canr’, ‘cans’, ‘cant’, ‘canu’, ‘canv’, ‘canw’, ‘canx’, ‘cany’, ‘canz’, ‘cao’, ‘cap’, ‘caq’, ‘car’, ‘cas’, ‘cat’, ‘cau’, ‘cav’, ‘caw’, ‘cax’, ‘cay’, ‘caz’, ‘cbn’, ‘ccn’, ‘cdn’, ‘cen’, ‘cfn’, ‘cgn’, ‘chn’, ‘cin’, ‘cjn’, ‘ckn’, ‘cln’, ‘cmn’, ‘cnn’, ‘con’, ‘cpn’, ‘cqn’, ‘crn’, ‘csn’, ‘ctn’, ‘cun’, ‘cvn’, ‘cwn’, ‘cxn’, ‘cyn’, ‘czn’, ‘dan’, ‘ean’, ‘fan’, ‘gan’, ‘han’, ‘ian’, ‘jan’, ‘kan’, ‘lan’, ‘man’, ‘nan’, ‘oan’, ‘pan’, ‘qan’, ‘ran’, ‘san’, ‘tan’, ‘uan’, ‘van’, ‘wan’, ‘xan’, ‘yan’, ‘zan’]
2.4 Exercise 7.insert_letter()
实现insert_letter()函数,输入一个单词并返回一个列表,在每个偏移处插入一个字母。
步骤1:与delete_letter()相同
步骤2:使用下面形式的list comprehensions列表推导式循环
[f(a,b,c) for a, b in splits if condition for c in string]
# UNIT TEST COMMENT: Candidate for Table Driven Tests
# UNQ_C7 GRADED FUNCTION: inserts
def insert_letter(word, verbose=False):
'''
Input:
word: the input string/word
Output:
inserts: a set of all possible strings with one new letter inserted at every offset
'''
letters = 'abcdefghijklmnopqrstuvwxyz'
insert_l = []
split_l = []
### START CODE HERE ###
alphabet=list(letters)
split_l=[(word[:i], word[i:]) for i in range (len (word) + 1)]
insert_l = [[word[:i]+j+word[i:] for j in alphabet] for i in range (len (word)+1)]
insert_l = [item for sublist in insert_l for item in sublist]
### END CODE HERE ###
if verbose: print(f"Input word {word} \nsplit_l = {split_l} \ninsert_l = {insert_l}")
return insert_l
测试:
insert_l = insert_letter('at', True)
print(f"Number of strings output by insert_letter('at') is {len(insert_l)}")
结果:
Input word at
split_l = [(‘’, ‘at’), (‘a’, ‘t’), (‘at’, ‘’)]
insert_l = [‘aat’, ‘bat’, ‘cat’, ‘dat’, ‘eat’, ‘fat’, ‘gat’, ‘hat’, ‘iat’, ‘jat’, ‘kat’, ‘lat’, ‘mat’, ‘nat’, ‘oat’, ‘pat’, ‘qat’, ‘rat’, ‘sat’, ‘tat’, ‘uat’, ‘vat’, ‘wat’, ‘xat’, ‘yat’, ‘zat’, ‘aat’, ‘abt’, ‘act’, ‘adt’, ‘aet’, ‘aft’, ‘agt’, ‘aht’, ‘ait’, ‘ajt’, ‘akt’, ‘alt’, ‘amt’, ‘ant’, ‘aot’, ‘apt’, ‘aqt’, ‘art’, ‘ast’, ‘att’, ‘aut’, ‘avt’, ‘awt’, ‘axt’, ‘ayt’, ‘azt’, ‘ata’, ‘atb’, ‘atc’, ‘atd’, ‘ate’, ‘atf’, ‘atg’, ‘ath’, ‘ati’, ‘atj’, ‘atk’, ‘atl’, ‘atm’, ‘atn’, ‘ato’, ‘atp’, ‘atq’, ‘atr’, ‘ats’, ‘att’, ‘atu’, ‘atv’, ‘atw’, ‘atx’, ‘aty’, ‘atz’]
Number of strings output by insert_letter(‘at’) is 78
insert_l = [[word[:i]+j+word[i:] for j in alphabet] for i in range (len (word)+1)]
这行代码生成的是一个嵌套列表(列表的列表)。对于输入单词 word 的每个可能的插入点 i(从 0 到 len(word)),它都会生成一个列表,其中包含在该插入点插入字母表 alphabet 中每个字母后的结果。因此,对于每个插入点,都会有 26 个插入后的字符串(假设 alphabet 包含 26 个字母)。insert_l 的大小是每个插入点的插入结果数量乘以插入点的数量。具体来说,如果单词 word 的长度为 n,则第一个 insert_l 将包含 (n + 1) * 26 个子列表,每个子列表包含 26 个元素。因此,总大小是 26n + 26。
insert_l = [item for sublist in insert_l for item in sublist]
这行代码将第一个 insert_l 中的嵌套列表展平成一个单一的列表。它首先遍历第一个 insert_l 中的每个子列表,然后遍历每个子列表中的每个元素,将它们添加到新的列表中。 insert_l 的大小与第一个相同,但它是一个单一的列表,而不是嵌套的列表。展平后的列表包含了所有可能的插入字符串,总共有 26n + 26 个元素。
注意:如果你测试得到的最后结果长度较短,例如:
Input word at
split_l = [(‘’, ‘at’), (‘a’, ‘t’), (‘at’, ‘’)]
insert_l = [‘aat’, ‘bat’, ‘cat’, ‘dat’, ‘eat’, ‘fat’, ‘gat’, ‘hat’, ‘iat’, ‘jat’, ‘kat’, ‘lat’, ‘mat’, ‘nat’, ‘oat’, ‘pat’, ‘qat’, ‘rat’, ‘sat’, ‘tat’, ‘uat’, ‘vat’, ‘wat’, ‘xat’, ‘yat’, ‘zat’, ‘aat’, ‘abt’, ‘act’, ‘adt’, ‘aet’, ‘aft’, ‘agt’, ‘aht’, ‘ait’, ‘ajt’, ‘akt’, ‘alt’, ‘amt’, ‘ant’, ‘aot’, ‘apt’, ‘aqt’, ‘art’, ‘ast’, ‘att’, ‘aut’, ‘avt’, ‘awt’, ‘axt’, ‘ayt’, ‘azt’]
Number of strings output by insert_letter(‘at’) is 52
说明在split_l中过滤掉了带空字符的元组:('at', ''),这里带空字符的元组不能省略、




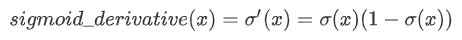































![[线上问题排查]JVM OOM问题如何排查和解决](https://i-blog.csdnimg.cn/direct/f216b5ddf528492fbe292e6855e3b327.gif)







