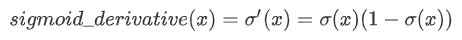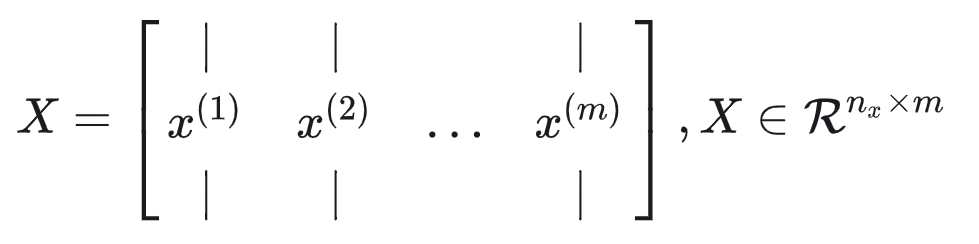作业1:吴恩达《深度学习》L1W2作业1 - Heywhale.com
作业2:吴恩达《深度学习》L1W2作业2 - Heywhale.com
作业1
你需要记住的内容:
-np.exp(x)适用于任何np.array x并将指数函数应用于每个坐标
-sigmoid函数及其梯度
sigmoid函数的梯度:
![]()
-image2vector通常用于深度学习
-np.reshape被广泛使用。 保持矩阵/向量尺寸不变有助于我们消除许多错误。
可以使用assert保证尺寸是我们想要的。
-numpy具有高效的内置功能
-broadcasting非常有用
你需要记住的内容:
-向量化在深度学习中非常重要, 它保证了计算的效率和清晰度。
-了解L1和L2损失函数。
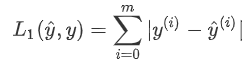
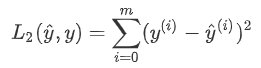
-掌握诸多numpy函数,例如np.sum,np.dot,np.multiply,np.maximum等。
np.dot表示矩阵乘法,直接使用*表示元素乘法,也就是说,它将两个数组中对应位置的元素相乘,得到一个新的具有相同形状的数组,*与np.multiply类似。
作业2
你需要记住的内容:
预处理数据集的常见步骤是:
- 找出数据的尺寸和维度(m_train,m_test,num_px等)
- 重塑数据集,以使每个示例都是大小为(num_px * num_px * 3,1)的向量
- “标准化”数据

我的理解是X.shape[0]表示多少行, -1表示剩余的所有维度数据合并成列,最后转置,所以最后行列互换,实验中train_set_x_orig的shape为(209,64,64,3),所以转置前表示209行,每一列都是其他维度数据的合并,最后转置,达成了209列,每一列表示每个特征。
你需要记住以下几点:
你已经实现了以下几个函数:
- 初始化(w,b)
- 迭代优化损失以学习参数(w,b):
- 计算损失及其梯度
- 使用梯度下降更新参数
- 使用学到的(w,b)来预测给定示例集的标签