论文:End-to-End Object Detection with Transformers
作者:Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
机构:Facebook AI
链接:https://arxiv.org/abs/2005.12872
代码:https://github.com/facebookresearch/detr
文章目录
1、算法概述
这篇论文中,作者将目标检测任务视为目标集(object set)预测问题。与之前的目标检测算法不同,它不需要NMS后处理及anchor生成这些集成了先验知识的操作。作者提出的检测框架主要由transformer结构组成(transformer论文超详细解读),作者为其命名DETR(DEtection TRansformer),它是一种基于集合的全局损失,通过双匹配策略(bipartite matching)强制进行唯一预测。给定一组固定的学习对象查询,DETR对对象和全局图像上下文的关系进行推理,从而直接并行输出最终的预测集。DETR在概念上很简单,且展示了优秀的准确性和运行时性能,在COCO目标检测数据集上表现与高度优化的Faster R-CNN相当;且DETR可以很容易地推广到全景分割任务。
2、动机
目标检测的目的是需要预测一个集合,集合中每个元素代表每个感兴趣目标的bounding box及类别标签。但是之前的目标检测算法是以一种间接的方式解决了这个集合预测任务,即通过在大量候选框、锚框设计或窗口中心上定义代理回归和分类问题。它们的性能受后期处理步骤、锚框集的设计以及将目标框分配给锚框的启发式算法的影响。
为了简化检测算法流程,作者提出了一种直接集预测方法来绕过代理任务。这种端到端思想已经在复杂的结构化预测任务(如机器翻译或语音识别)中取得了重大进展,但尚未在目标检测中取得进展,本文旨在弥补这一差距。
3、DETR细节
作者通过将目标检测视为直接集预测问题来简化训练流程。整个检测框架采用基于transformer的编码器-解码器架构,这是一种常用的序列预测结构。transformer的自注意力机制显式地对序列中元素之间的所有成对交互进行建模,使这些体系结构特别适合于集合预测的特定约束,例如删除重复的预测。
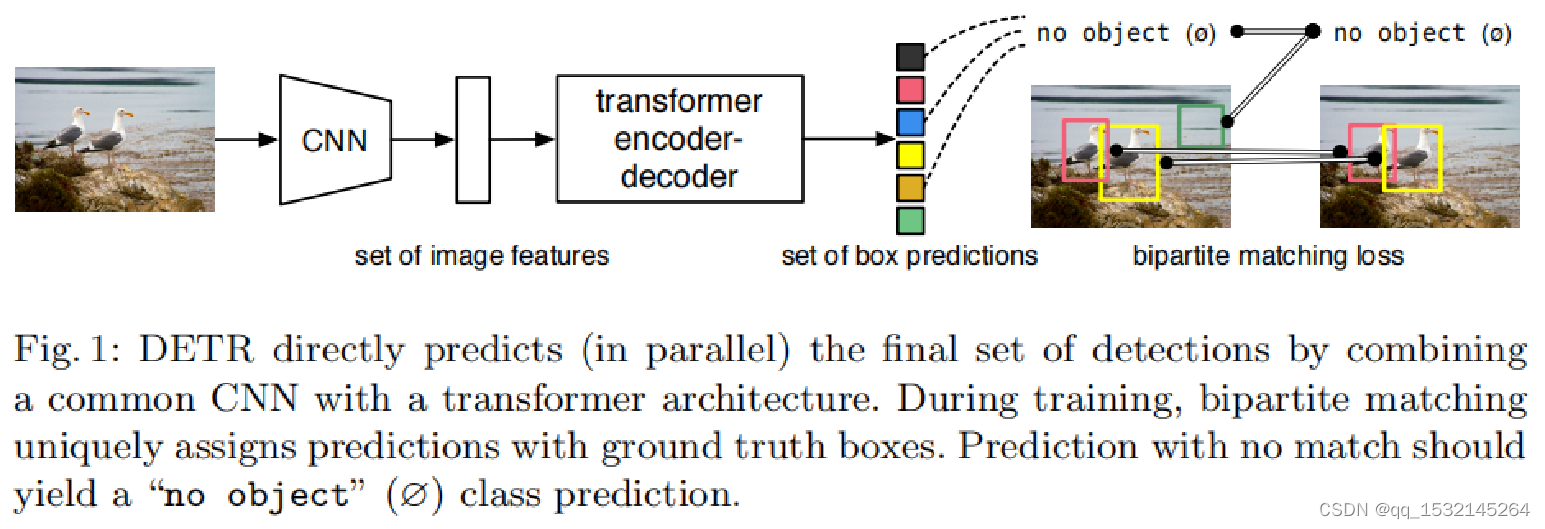
作者所提的DETR检测算法一次可以预测所有对象,并使用一组损失函数进行端到端训练,该函数在预测对象和真实对象之间执行双匹配。整体检测流程如下图所示:

可以看到,图像首先经过CNN网络提取到一系列特征图,特征图再经过transformer得到目标框预测集合,可见DETR是CNN与transformer的结合利用。
对于检测中的直接集预测,有两个要素是必不可少的:一是集合预测的损失问题,它强制在预测值和实际值之间进行唯一匹配,二是如何设计整个网络结构,这个结构需预测一组对象并对它们之间的关系进行建模。
3.1 Object detection set prediction loss
DETR首先会被设置固定数量为N的预测结果,这个N怎么确定呢?,它需要被设置为明显大于图像中典型对象的数量,假如对于COCO数据集中,图像标注了最多60个目标对象,N设置明显大于60即可。训练的主要困难之一是根据真实标注框对预测对象(类别、位置、大小)进行评分。我们的损失在预测对象和真实对象之间产生最优的双匹配,然后优化对象特定的bounding box损失。
把y看成是ground truth集合,大小为N,真实的ground truth标注框肯定小于N的,不足的用ø(代表no object)补齐;y ̂={y ̂i }ⅈ=1N代表N个预测结果,将两个大小为N集合进行一一对应匹配,即将预测结果集合y ̂与ground truth集合y进行匹配,寻找代价最小的N个元素σ∈бN的排列,公式可表示为:

两者的匹配算法采用匈牙利算法。匹配损失既考虑了类别预测与考虑了预测框与ground truth框的相似度。对于ground truth集合中的每个元素yi=(ci,bi),ci代表真实类别标签(有可能是ø),bi∈[0,1]4代表归一化后真实标注框向量(框中心点坐标,高宽)。
在第一步匈牙利匹配的基础上,第二步是计算损失函数。在前一步中匹配的所有对的匈牙利损失,作者对损失的定义类似于普通目标检测器的损失,即类预测的负对数似然和bounding box损失的线性组合:

因为大部分可能都是背景,那么背景类的权重就除以10。相当于前景(目标)和背景做一个data balance。
- Bounding box loss
上面公式中的后一部分Lbox(.)代表预测框的分数,不像之前大多数的检测算法,他们有一个预测基准(anchor),作者提的DETR是直接预测的。虽然这种方法简化了实现,但它带来了损失相对尺度的问题。即使相对误差相似,最常用的L1损失对于小尺度目标和大尺度目标也会有不同的尺度问题。为了缓解这个问题,作者使用L1损失和广义IoU损失的线性组合,因为Liou损失是尺度不变的。所以作者定义的Lbox(.)公式为:

3.2 DETR architecture
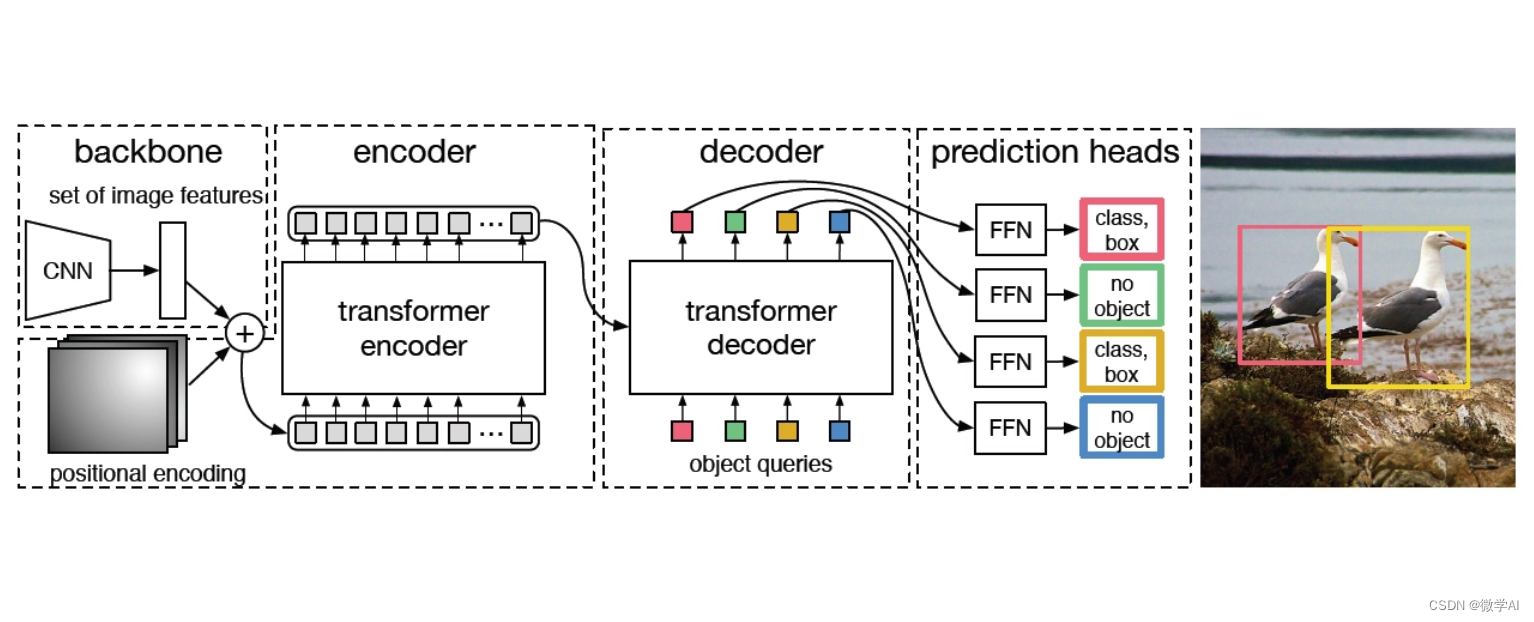
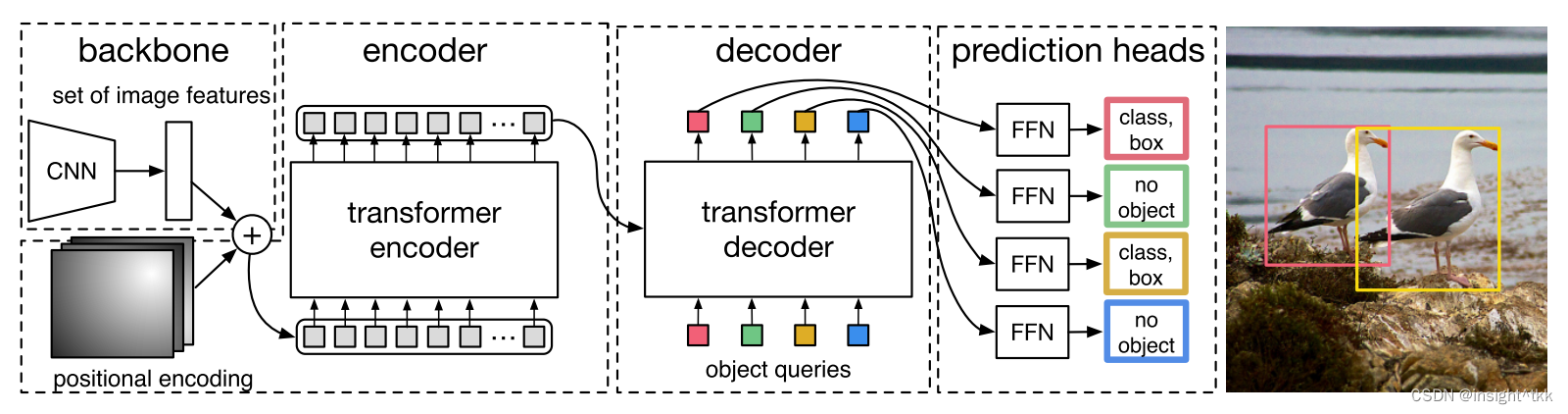
DETR检测算法的整体框架如下图所示:

它包含三个主要组件:一个CNN的backbone用于提取图像特征,一个encoder-decoder组成的transformer和一个前馈神经网络(FFN)用于做最后的预测。
3.2.1 Backbone
Backbone用于提取图像特征,对于输入图像ximg∈R3xH0xW0,经过CNN结构的backbone处理将得到分辨率较小的特征图f∈RCxHxW,通常情况下,C=2048,H,W=H0/32,W0/32。
3.2.2 Transformer
DETR中transformer的内部结构如下,与2017年提出的transformer一样,只是输入不同,这里进入transformer的是图像块拼接成的“序列”。

Transformer encoder
首先在进入transformer encoder之前,需将backbone提取到的特征图f由C通道用1x1卷积降维到d维HxW大小的特征图z0,由于transformer encoder是对序列做处理,所以需要对d维的HxW大小的特征图进行压缩,得到dxHW的二维特征图。每个encoder由多头自注意力模块(multi-head self-attention module)和前馈神经网络模块(FFN)组成。由于目标检测与位置信息紧密关联,作者也在encoder中加入了位置信息。Transformer decoder
解码器遵循原版transformer的标准架构,与原版transformer的不同之处在于,作者的模型在每个解码器层并行解码N个对象,而原版transformer使用自回归模型,每次预测一个元素的输出序列。由于解码器也是排列不变的,因此N个输入嵌入必须不同才能产生不同的结果。N个对象查询由解码器转换为输出嵌入。然后通过前馈网络(FFN)将它们独立解码为框坐标和类标签,从而产生N个最终预测。Prediction feed-forward networks (FFNs)
最后的预测由一个具有ReLU激活函数和隐藏维数为d的3层感知器和一个线性投影层来计算得到,FFN预测包括归一化后的box坐标(中心点坐标,高宽) 及通过softmax层映射后的类别概率。因为DETR预测一个固定大小的N个边界框集合,而且N通常比图像中感兴趣的对象的实际数量大得多,所以使用一个额外的特殊类label_∅来表示在一个框内没有检测到对象。该类的作用类似于“background”类。
4、实验
4.1 COCO2017
作者在VOC2007上与Faster R-CNN的测试结果如下:

可以看出,DETR在AP上达到了Faster R-CNN的性能,缺陷就是在小目标上还是不及Faster R-CNN,大目标上有巨大优势,这也印证了结合transformer结构的优势,transformer能关注到全局信息,对大目标检测有极大帮助。
4.2 消融实验
Number of encoder layers
作者通过改变编码器层数来评估全局图像级自注意力机制的重要性,若没有编码器层,整体AP下降3.9%,而大目标的APL下降幅度更大,有6.0%,如下表所示。

作者推测,通过使用全局场景推理,编码器对解纠缠目标很重要。在下图中,作者可视化了训练模型的最后一个编码器层的注意图,集中在图像中的几个点上。编码器似乎已经分离了实例,这可能简化了解码器的对象提取和定位。

Number of decoder layers
作者通过增加decoder layer的数量,得到AP的评估结果,并且还讨论了NMS是否对最终的AP有影响的实验,如下图所示:

最终结果表明,随着decoder layer的增加,AP值有显著的提升,而增加NMS只对只有一层decoder layer时有帮助,后面随着decoder layer的数量增加,对AP的提升帮助不大,所以DETR可以完全丢弃NMS后处理。
最后,作者还可视化了解码器的关注点,如下图所示,将每个预测对象的注意图涂成不同的颜色。作者观察到,解码器的注意力是相当局部的,这意味着解码器主要关注的是物体的四肢,比如头或腿。所以作者推测,在编码器通过全局关注分离实例之后,解码器只需要关注端点以提取类和对象的边界。

Importance of FFN
作者试图完全删除它,只把注意力放在transformer layer上。通过将网络参数数量从41.3M减少到28.7M,但是性能下降了2.3%AP,因此作者得出FFN对于取得良好效果很重要。Importance of positional encodings
在作者所提的模型中有两种位置编码:空间位置编码和输出位置编码(object queries)。作者实验了固定编码和学习编码的各种组合,得到下表的实验结果:

Loss ablations
作者实验了各种损失的组合,结果如下:

可以看出类别损失、L1损失和GIoU损失三个同时使用才能达到最佳。
5、创新点和不足
创新点:
1、首次在目标检测任务中引入transformer,以集合预测的思想做目标检测,并且提供了encoder和decoder的可视化和可解释性。
不足:
1、相比于Faster R-CNN,训练需要迭代次数非常多;
2、从和Faster R-CNN的比较结果来看,小目标检测能力还不行;