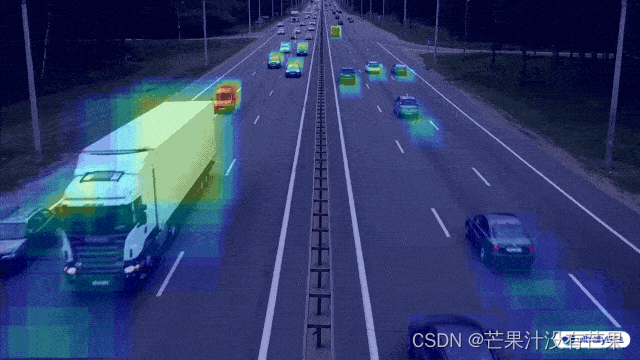
博主一直一来做的都是基于Transformer的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。
终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。
那么RT-DETR是如何做到的呢?
在研究RT-DETR的改进前,我们先来了解下DETR类目标检测方法的发展历程吧
- 首先是
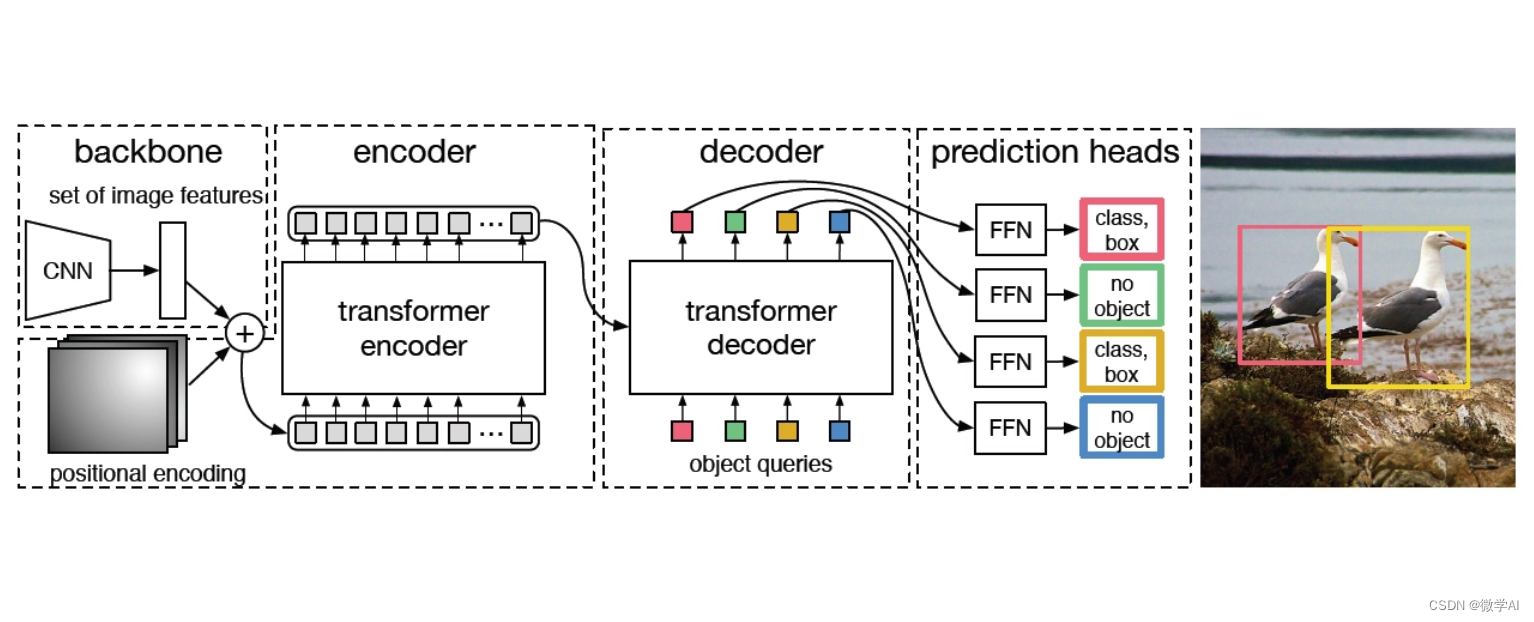
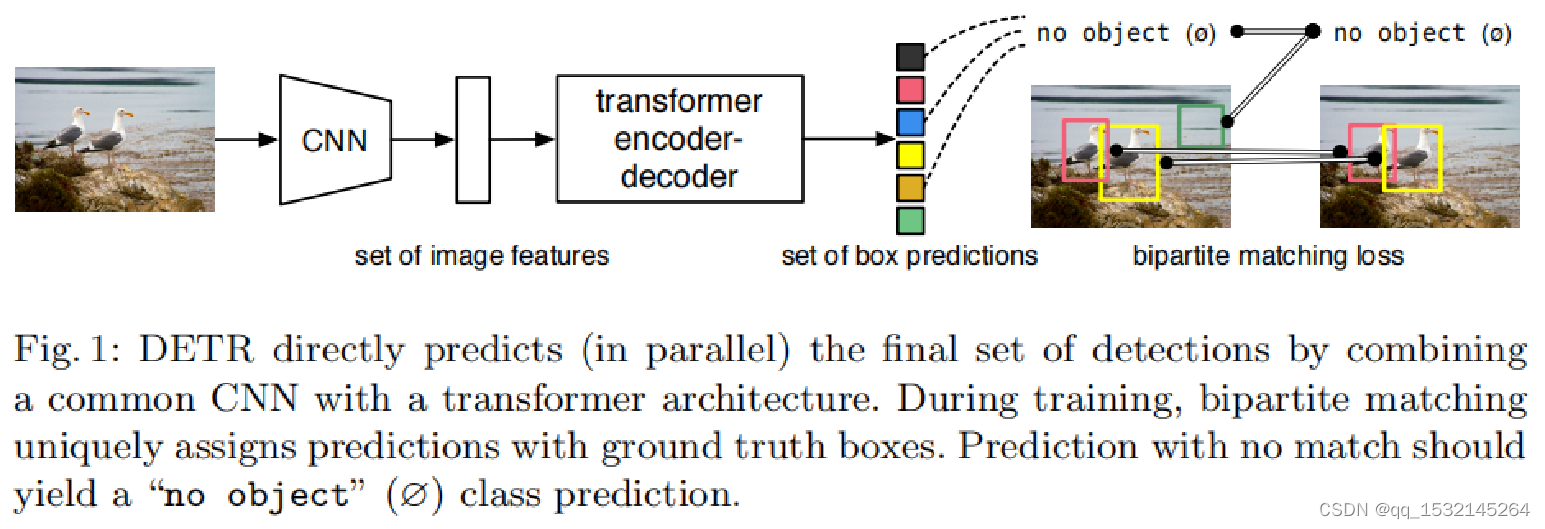
DETR,该方法作为Transformer在目标检测领域的开山之作,一经推出,便引发了极大的轰动,该方法巧妙的利用Transformer进行特征提取与解码,同时通过匈牙利匹配方法完成预测框与真实框的匹配,避免了NMS等后处理过程。 - 随后
DAB-DETR引入了动态锚框作为查询向量,从而对DETR中的100个查询向量进行了解释。 Deformable-DETR针对Transformer中自注意力计算复杂度高的问题,提出可变形注意力计算,即通过可学习的选取少量向量进行注意力计算,大幅的降低了计算量。- DN-DETR认为匈牙利匹配的二义性是导致
DETR训练收敛慢的原因,因此提出查询降噪机制,即利用先前DAB-DETR中将查询向量解释为锚框的原理,给查询向量添加一些噪声来辅助模型收敛,最终大幅提升了模型的训练速度。 - DINO则是在DAB-DETR与DN-DETR的基础上进行进一步的融合与改进。
H-DETR为使模型获取更多的正样本特征,从而提升检测精度,因此提出混合匹配方法,在训练阶段,包含原始的匈牙利匹配分支与一个一对多的辅助匹配分支,而在推理阶段,则只有一个匈牙利匹配分支。
然而,上述方法尽管已经大幅提升了检测精度,降低了计算复杂度,但其受Transformer本身高计算复杂度的制约,DETR类目标检测方法的实时性始终令人难以满意,尤其是相较于YOLO等单阶段目标检测方法,其检测速度的确差别巨大。
为了解决这个问题,百度提出了RT-DETR,该方法依旧是在DETR的基础上改进生成的,从论文中给出的实验结果来看,该方法无论在检测速度还是检测精度方法都已经超过了YOLOv8,实现了真正的实时性。

- 创新点1:高效混合编码器:RT-DETR使用了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来处理多尺度特征。这种独特的基于视觉Transformer的设计降低了计算成本,并允许实时物体检测。
- 创新点2:IoU感知查询选择:RT-DETR通过利用IoU感知的查询选择改进了目标查询初始化。这使得模型能够聚焦于场景中最相关的目标,从而提高了检测精度。
- 创新点3:自适应推理速度:RT-DETR支持通过使用不同的解码器层来灵活调整推理速度,而无需重新训练。这种适应性便于在各种实时目标检测场景中的实际应用。
RT-DETR的代码有两个,一个是官方提供的代码,但该代码功能比较单一,只有训练与验证,另一个则是集成在YOLOv8中,该代码的设计就比较全面了
环境部署
conda create -n rtdetr python=3.8
conda activate rtdetr
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
cd RT-DETR-main/rtdetr_pytorch //这个路径根据你自己的改
pip install -r requirement.txt
该算法的环境为pytorch=2.0.1,注意,尽量要用pytorch2以上的版本,否则可能会报错:
AttributeError: module 'torchvision' has no attribute 'disable_beta_transforms_warning'
官方模型训练
参数配置
该算法的配置封装较好,我们只需要修改配置即可:train.py,指定要使用的骨干网络。
parser.add_argument('--config', '-c', default="/rtdetr_pytorch\configs/rtdetr/rtdetr_r18vd_6x_coco.yml",type=str, )
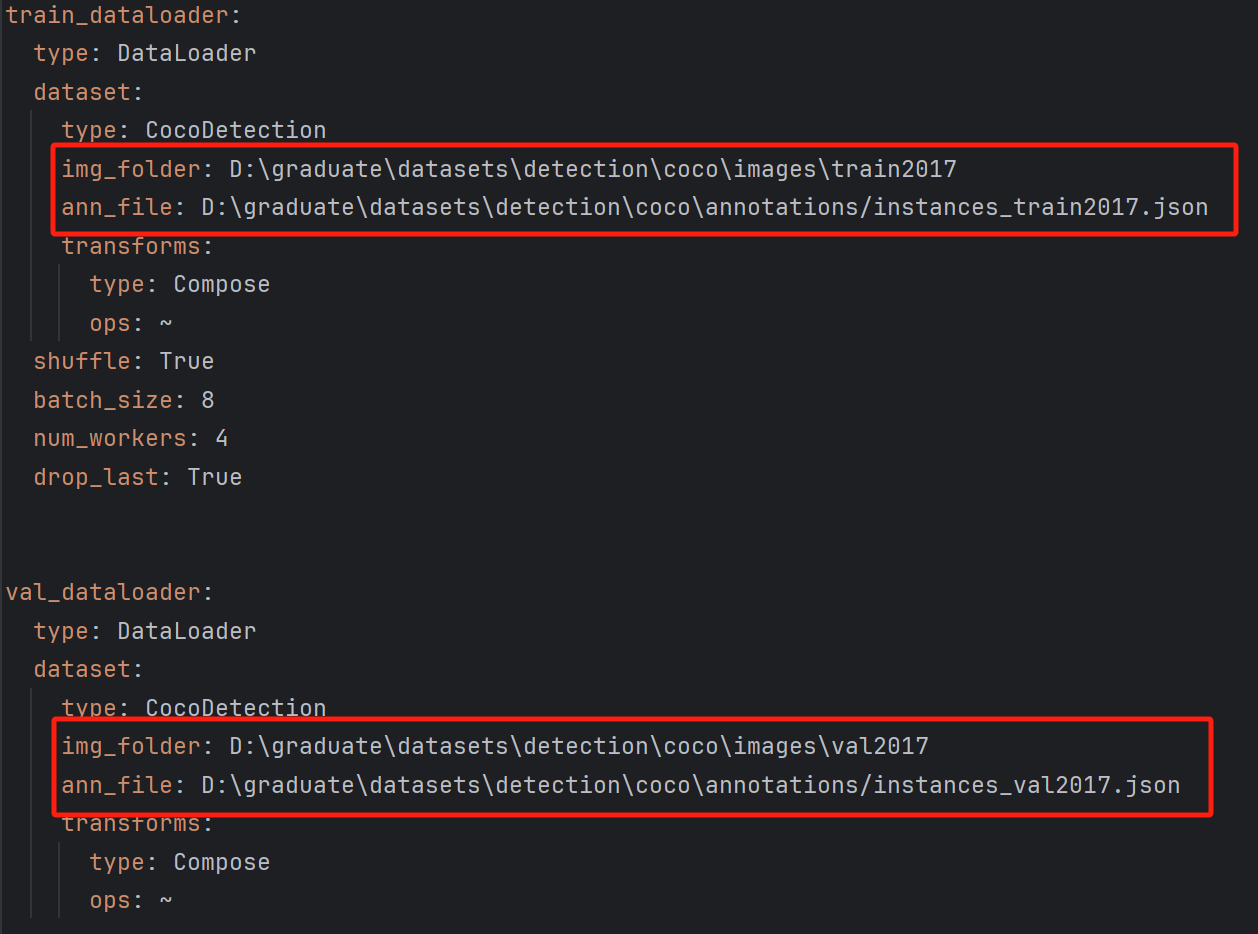
修改数据集配置文件:RT-DETR-main\rtdetr_pytorch\configs\dataset\coco_detection.yml
修改训练集与测试集路径,同时修改类别数。
随后便可以开启训练:该文件中指定 epochs
RT-DETR-main\rtdetr_pytorch\configs\rtdetr\include\optimizer.yml
首次训练,需要下载骨干网络的预训练模型

在这里,博主使用ResNet18作为骨干特征提取网络
训练结果
开始运行,查看GPU使用情况,此时的batch-size=8,可以看到显存占用4.5G左右,相较于博主先前提出的方法或者DINO,其显存占用少了许多,DINO的batch-size=2时的显存占用将近16G.
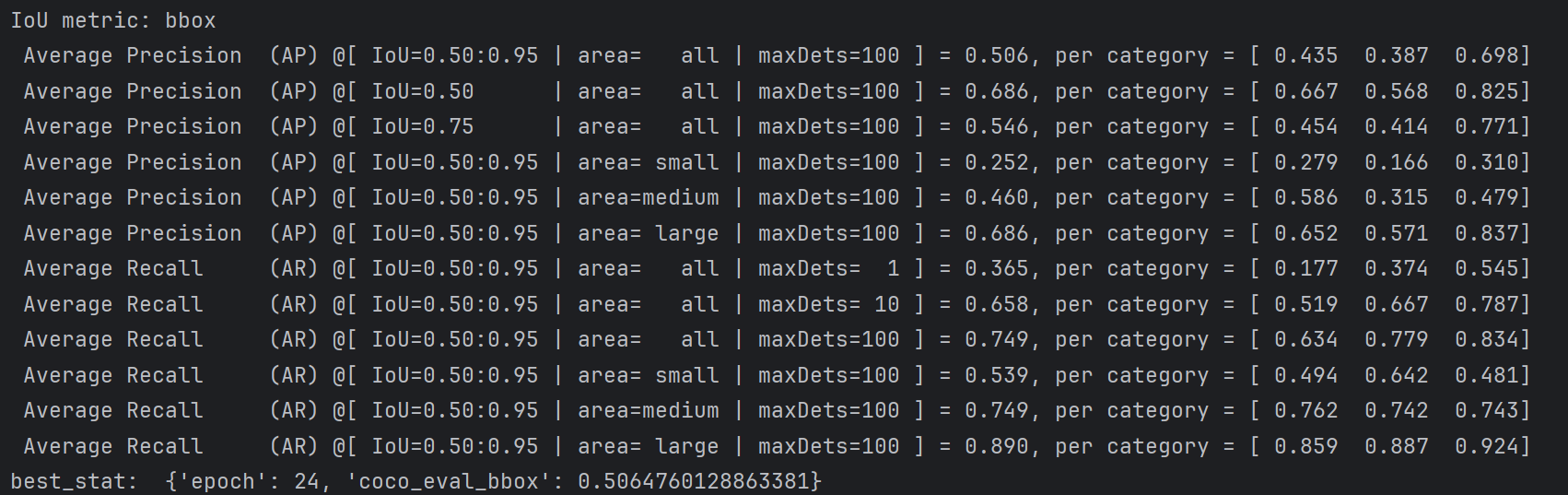
训练了24轮的结果。
训练的结果会保存在output文件夹内:
官方模型推理
在进行模型推理前,需要先导出模型,在官方代码的tools文件夹下有个export_onnx.py文件,只需要指定配置文件与训练好的模型文件:
parser.add_argument('--config', '-c', default="/rtdetr_pytorch\configs/rtdetr/rtdetr_r18vd_6x_coco.yml",type=str, )
parser.add_argument('--resume', '-r', default="rtdetr_pytorch/tools\output/rtdetr_r18vd_6x_coco\checkpoint0024.pth",type=str, )
导出的文件是onnx格式
ONNX(Open Neural Network Exchange)是一种开放式的文件格式,用于存储和交换训练好的机器学习模型。它使得不同的人工智能框架(如PyTorch、TensorFlow)可以共享模型,促进了模型在不同平台之间的迁移和复用。ONNX文件采用Protobuf序列化技术进行存储,具有高效、紧凑的特点。
随后开始推理,代码如下:
import torch
import onnxruntime as ort
from PIL import Image, ImageDraw
from torchvision.transforms import ToTensor
if __name__ == "__main__":
##################
classes = ['car','truck',"bus"]
##################
# print(onnx.helper.printable_graph(mm.graph))
#############
img_path = "1.jpg"
#############
im = Image.open(img_path).convert('RGB')
im = im.resize((640, 640))
im_data = ToTensor()(im)[None]
print(im_data.shape)
size = torch.tensor([[640, 640]])
sess = ort.InferenceSession("model.onnx")
import time
start = time.time()
output = sess.run(
# output_names=['labels', 'boxes', 'scores'],
output_names=None,
input_feed={'images': im_data.data.numpy(), "orig_target_sizes": size.data.numpy()}
)
end = time.time()
fps = 1.0 / (end - start)
print(fps)
labels, boxes, scores = output
draw = ImageDraw.Draw(im)
thrh = 0.6
for i in range(im_data.shape[0]):
scr = scores[i]
lab = labels[i][scr > thrh]
box = boxes[i][scr > thrh]
print(i, sum(scr > thrh))
#print(lab)
print(f'box:{box}')
for l, b in zip(lab, box):
draw.rectangle(list(b), outline='red',)
print(l.item())
draw.text((b[0], b[1] - 10), text=str(classes[l.item()]), fill='blue', )
#############
im.save('2.jpg')
#############
YOLOv8集成RT-DETR训练
在YOLOv8中,给出了YOLO先前的诸多版本,此外还包含RT-DETR
其运行环境与官方的相同,这里就不再赘述了,另外,如果想要了解YOLO及其集成算法的更多功能,可以查看:
https://docs.ultralytics.com/
ultralytics集成了多种算法,已有将YOLO目标检测算法大一统的趋势,涵盖语义分割、目标检测、姿势估计、分类、跟踪等多个任务。
数据集配置
YOLO版本的RT-DETR的数据集支持的数据集格式有多种,这里博主选用的是YOLO格式的
coco
images
train2017
val2017
lables
train2017
val2017
开始训练
随后在根目录下新建一个run.py文件,文件中写入如下代码:
from ultralytics.models import RTDETR
if __name__ == '__main__':
model = RTDETR(model='ultralytics/cfg/models/rt-detr/rtdetr-l.yaml')
#model.load('rtdetr-l.pt') # 不使用预训练权重可注释掉此行
model.train(pretrained=True, data='ultralytics\cfg\datasets\cocomine.yaml', epochs=200, batch=16, device=0, imgsz=320, workers=2,cache=False,)
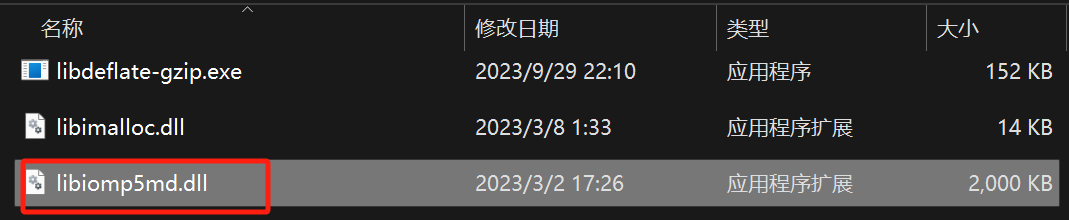
运行报错:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方法,这是由于Anconda的torch中的某个文件与环境中的某个文件冲突导致的,找到环境中的文件:
环境路径:
D:\softwares\Anconda\envs\detr\Library\bin
将下面的文件给重命名即可。
随后便开始训练了,如下:
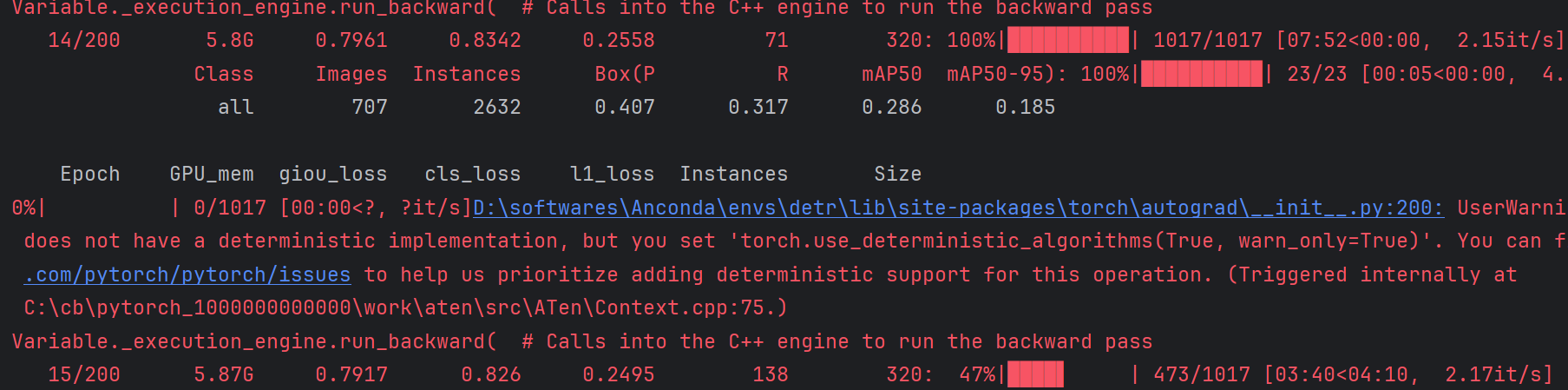
至此,RT-DETR的训练过程便完成了。博主设置训练200个epoch,但考虑到接下来的任务,因此训练到一半就停止了,生成的文件存放在run文件中,如下:
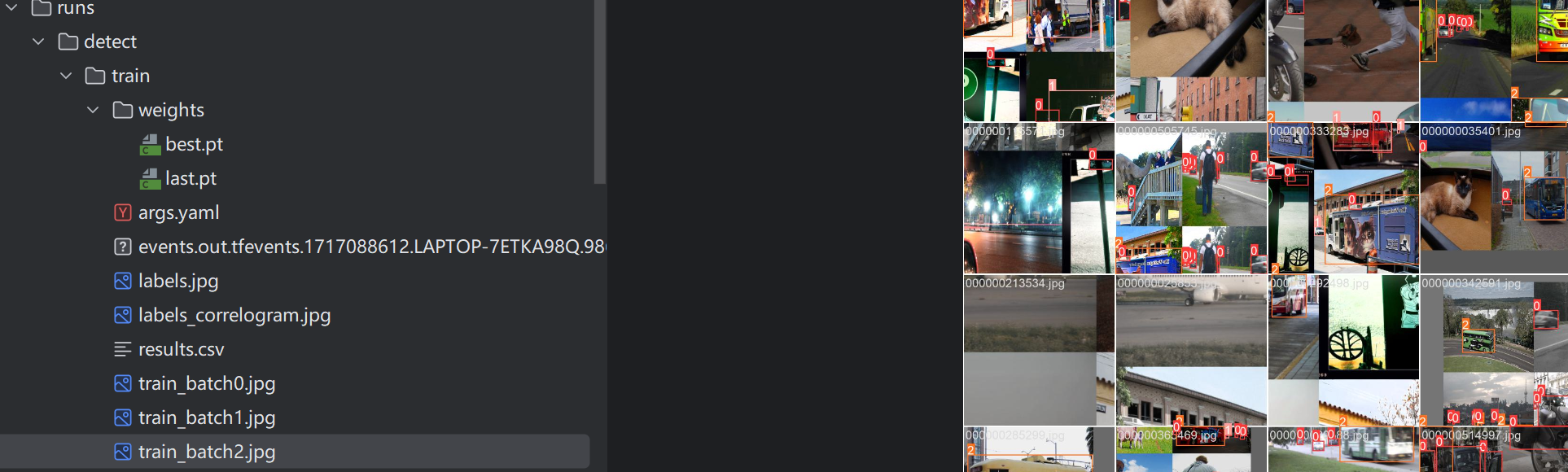
YOLOv8集成RT-DETR推理
在YOLOv8集成的RT-DETR中,其设计就非常完备了,我们只需要新建一个predict.py,里面的内容如下:
这里的images即为一个文件夹,里面可以放入多张图像,save代表保存
model=RTDETR("runs\detect/train\weights/best.pt")
model.predict(source="images",save=True)
推理结果、保存路径与推理速度都会显示在下面

当然我们还可以指定conf参数,即置信度,可以帮我们筛选一下结果:设置置信度为0.6,此时原本的汽车就不再框选了。


视频推理
视频推理也很简单,只需要将原来的图像换为视频即可
model=RTDETR("runs\detect/train\weights/best.pt")
model.predict(source="images/1.mp4",save=True,conf=0.6)

目标跟踪
在先前的目标跟踪中,都是通过先检测,后跟踪的方式,如采用YOLOv5+DeepSort的方式进行目标跟踪,而在YOLOv8中,他将该功能集成到里面,我们可以直接采用执行跟踪任务的方式完成目标跟踪。
from ultralytics.models import RTDETR
model=RTDETR("runs\detect/train\weights/best.pt")
results = model.track(source="images/1.mp4", conf=0.3, iou=0.5,save=True)
RT-DETR目标跟踪视频
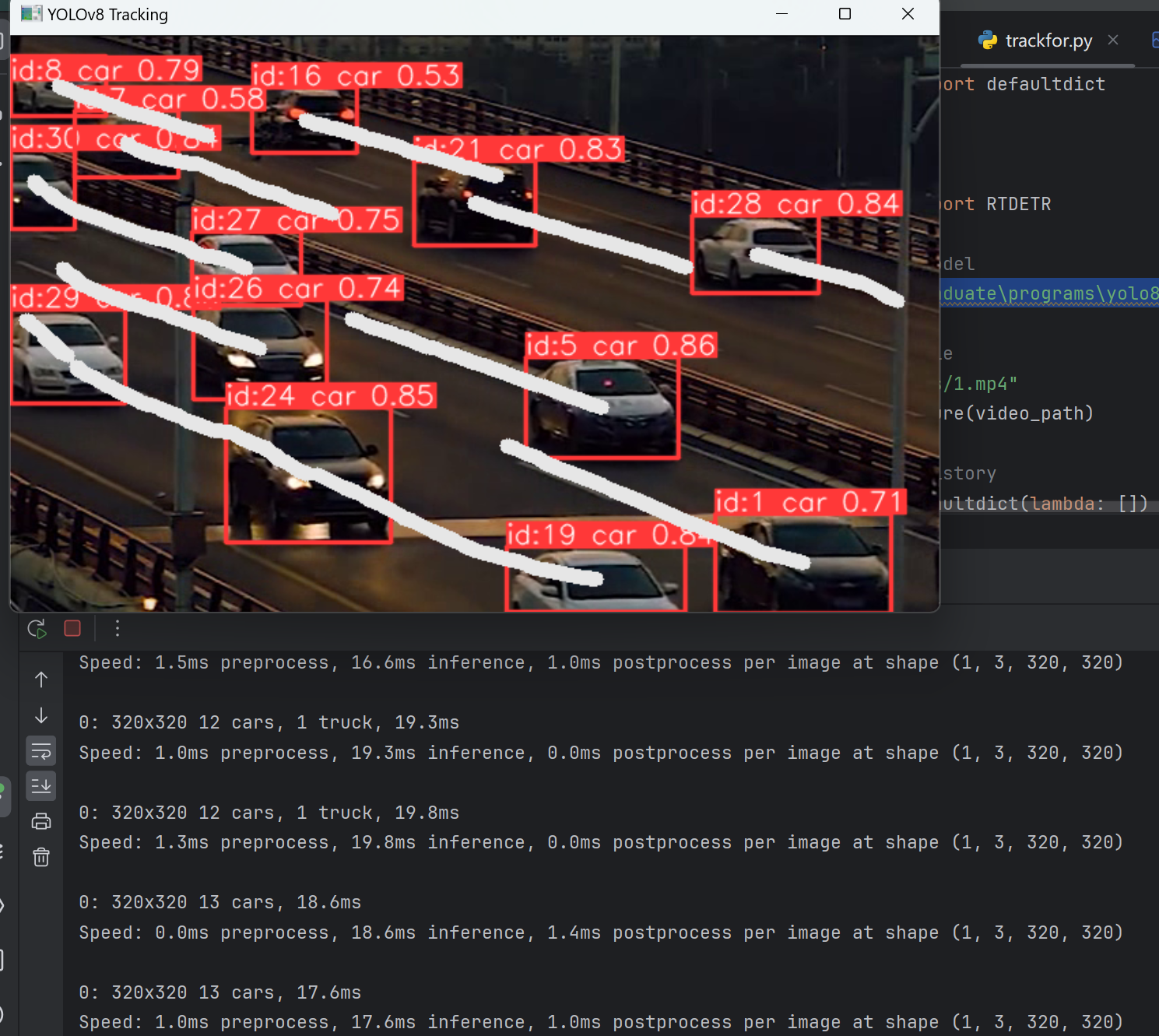
轨迹绘制
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import RTDETR
# Load the YOLOv8 model
model=RTDETR("D:\graduate\programs\yolo8/ultralytics-main/runs\detect/train\weights/best.pt")
# Open the video file
video_path = "images/1.mp4"
cap = cv2.VideoCapture(video_path)
# Store the track history
track_history = defaultdict(lambda: [])
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Get the boxes and track IDs
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Plot the tracks
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y center point
if len(track) > 30: # retain 90 tracks for 90 frames
track.pop(0)
# Draw the tracking lines
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# Display the annotated frame
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()


](https://img-blog.csdnimg.cn/direct/6eaeca18ab73405fb3be164bd6406030.png)