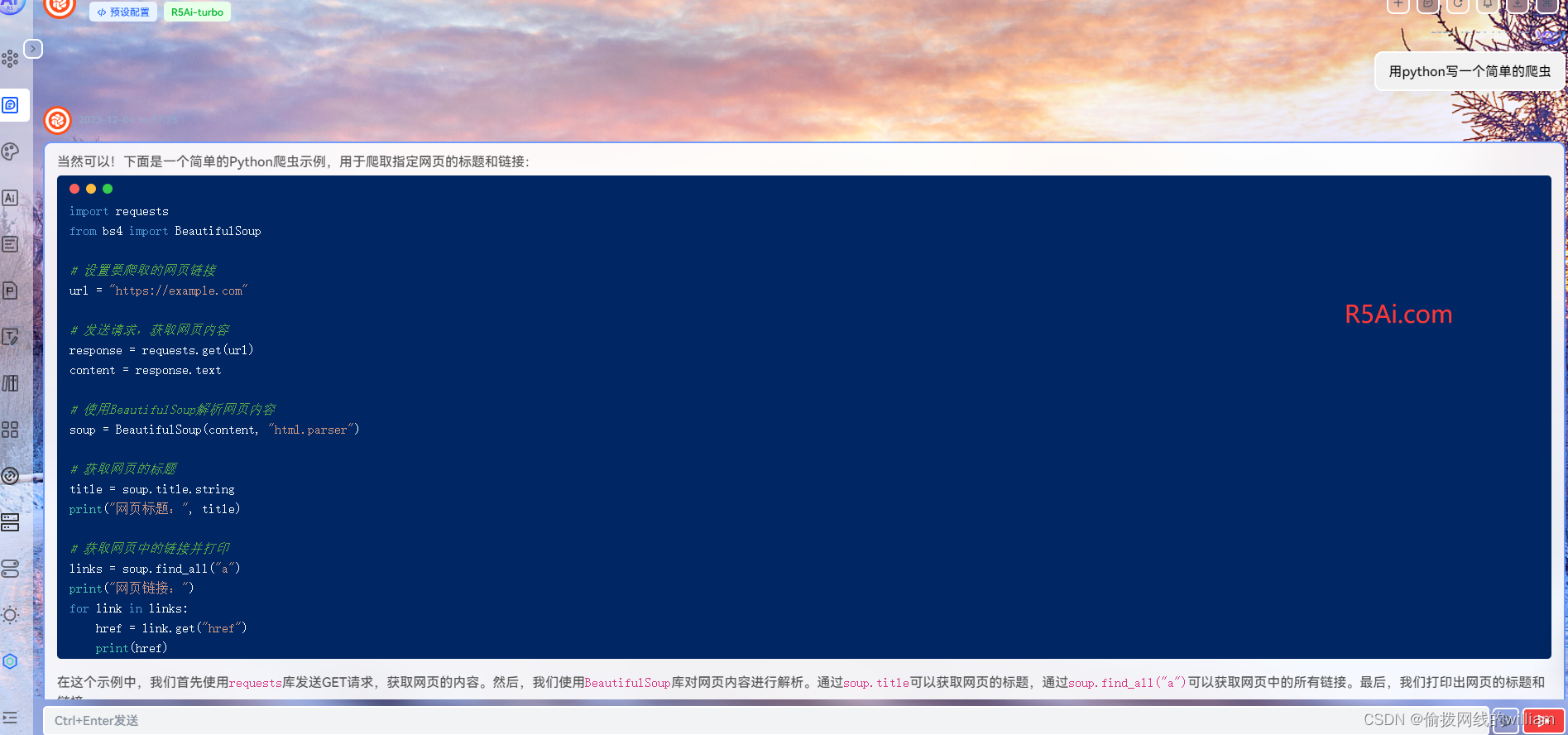
为了爬取Google中关于蛇的照片,我们可以利用Python中的第三方库进行网页解析和HTTP请求。请注意,这种爬取行为可能违反Google的使用条款,因此建议在合法和允许的情况下使用。以下是一个基本的Python爬虫示例,使用Requests库发送HTTP请求,并使用Beautiful Soup库解析HTML内容。
爬虫实现步骤
1.安装所需库:
使用 pip 安装 requests 和 beautifulsoup4 库。
pip install requests beautifulsoup4
2.编写爬虫代码:
下面是一个简单的Python脚本,用于从Google搜索中获取蛇的图片链接。请注意,由于Google的页面结构经常更改,所以此代码可能需要根据实际情况进行调整。
import requests
from bs4 import BeautifulSoup
import re
import os
def fetch_google_images(query, num_images):
# 替换空格为加号,构建搜索URL
query = query.replace(' ', '+')
url = f"https://www.google.com/search?q={query}&tbm=isch"
# 发送HTTP GET请求
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)
response.raise_for_status()
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所有图片链接
image_links = []
for img in soup.find_all('img'):
image_link = img.get('src')
if image_link:
# 过滤掉base64编码的图片和空链接
if not image_link.startswith('data:image'):
image_links.append(image_link)
# 下载图片
download_images(image_links[:num_images], query)
def download_images(image_links, query):
# 创建目录存储图片
if not os.path.exists(query):
os.makedirs(query)
# 下载图片并保存到本地
for i, link in enumerate(image_links):
try:
response = requests.get(link)
response.raise_for_status()
# 提取文件扩展名
_, ext = os.path.splitext(link)
ext = ext.split('?')[0] # 处理链接中的查询参数
# 保存图片
filename = os.path.join(query, f"{i+1}{ext}")
with open(filename, 'wb') as f:
f.write(response.content)
print(f"Downloaded {filename}")
except Exception as e:
print(f"Failed to download {link}. Error: {str(e)}")
if __name__ == "__main__":
query = "snake" # 搜索关键词
num_images = 10 # 要下载的图片数量
fetch_google_images(query, num_images)
3.爬虫说明
fetch_google_images 函数负责发送HTTP GET请求到Google图片搜索页面,并使用Beautiful Soup解析页面内容,提取图片链接。
download_images 函数负责下载图片并保存到本地目录。
User-Agent 头部是模拟浏览器的一部分,有助于避免被服务器拒绝访问(HTTP 403错误)。
注意事项
合法性和使用政策:请遵循Google的使用政策和法律法规,确保你的爬取行为合法。
页面结构变化:Google的页面结构可能会经常更改,导致爬虫代码需要调整或更新。
爬取速率:请注意爬取速率,避免对目标服务器造成过大的负载,也避免被封IP或屏蔽访问。
记得要遵守网络服务提供商的使用条款和法律法规,以免产生法律问题。