文章目录
大语言模型系列 - Transformer:从基础原理到应用
随着人工智能和自然语言处理(NLP)技术的不断发展,Transformer模型已成为现代深度学习中最为重要的模型之一。自从Vaswani等人在2017年提出Transformer以来,它已成为解决各种NLP任务的基础。本篇博客将详细介绍Transformer的基础原理、架构、应用场景以及如何进行模型的测试和优化。
一、Transformer简介
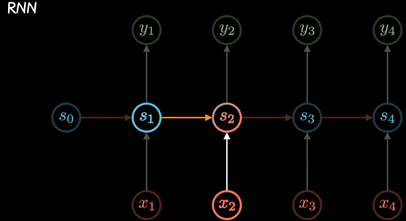
Transformer是由Google Brain团队在2017年提出的一种全新的神经网络架构,用于处理序列数据。不同于传统的循环神经网络(RNN)和长短期记忆网络(LSTM),Transformer完全基于注意力机制,不依赖于序列的顺序处理,使其能够更好地并行化训练。
Transformer模型在多个NLP任务中表现出了卓越的性能,如机器翻译、文本生成和问答系统等。其核心思想是通过自注意力机制来捕捉序列中各个位置之间的关系,从而实现高效的特征表示。
二、Transformer的基础原理
Transformer模型的核心组件包括自注意力机制、多头注意力机制、位置编码、残差连接和层归一化等。
自注意力机制
自注意力机制(Self-Attention)是Transformer的核心,它能够计算序列中任意两个位置之间的相似度。自注意力机制的输入是一个序列的特征表示,输出是相同维度的序列特征,但每个位置的特征是通过加权平均其他所有位置的特征得到的。
自注意力的计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q Q Q、 K K K和 V V V分别是查询、键和值矩阵, d k d_k dk是键的维度。
多头注意力机制
多头注意力机制(Multi-Head Attention)是对自注意力机制的扩展。通过引入多个独立的注意力头,模型能够从不同的子空间中学习到更加丰富的特征表示。
多头注意力机制的计算公式如下:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中, head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV), W i Q W_i^Q WiQ、 W i K W_i^K WiK、 W i V W_i^V WiV和 W O W^O WO是可学习的参数矩阵。
位置编码
由于Transformer不依赖于序列的顺序处理,需要引入位置编码(Positional Encoding)来保留序列的位置信息。位置编码是一种固定的向量,加到输入的特征表示上,使模型能够区分不同位置的元素。
位置编码的计算公式如下:
PE ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) \text{PE}(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
PE ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) \text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中, p o s pos pos是位置, i i i是维度索引, d m o d e l d_{model} dmodel是模型的维度。
残差连接和层归一化
残差连接(Residual Connection)和层归一化(Layer Normalization)是Transformer中的两个重要机制,能够缓解梯度消失和梯度爆炸问题,稳定模型训练。
残差连接的计算公式如下:
Output = LayerNorm ( x + SubLayer ( x ) ) \text{Output} = \text{LayerNorm}(x + \text{SubLayer}(x)) Output=LayerNorm(x+SubLayer(x))
其中, SubLayer ( x ) \text{SubLayer}(x) SubLayer(x)可以是多头注意力机制或前馈神经网络。
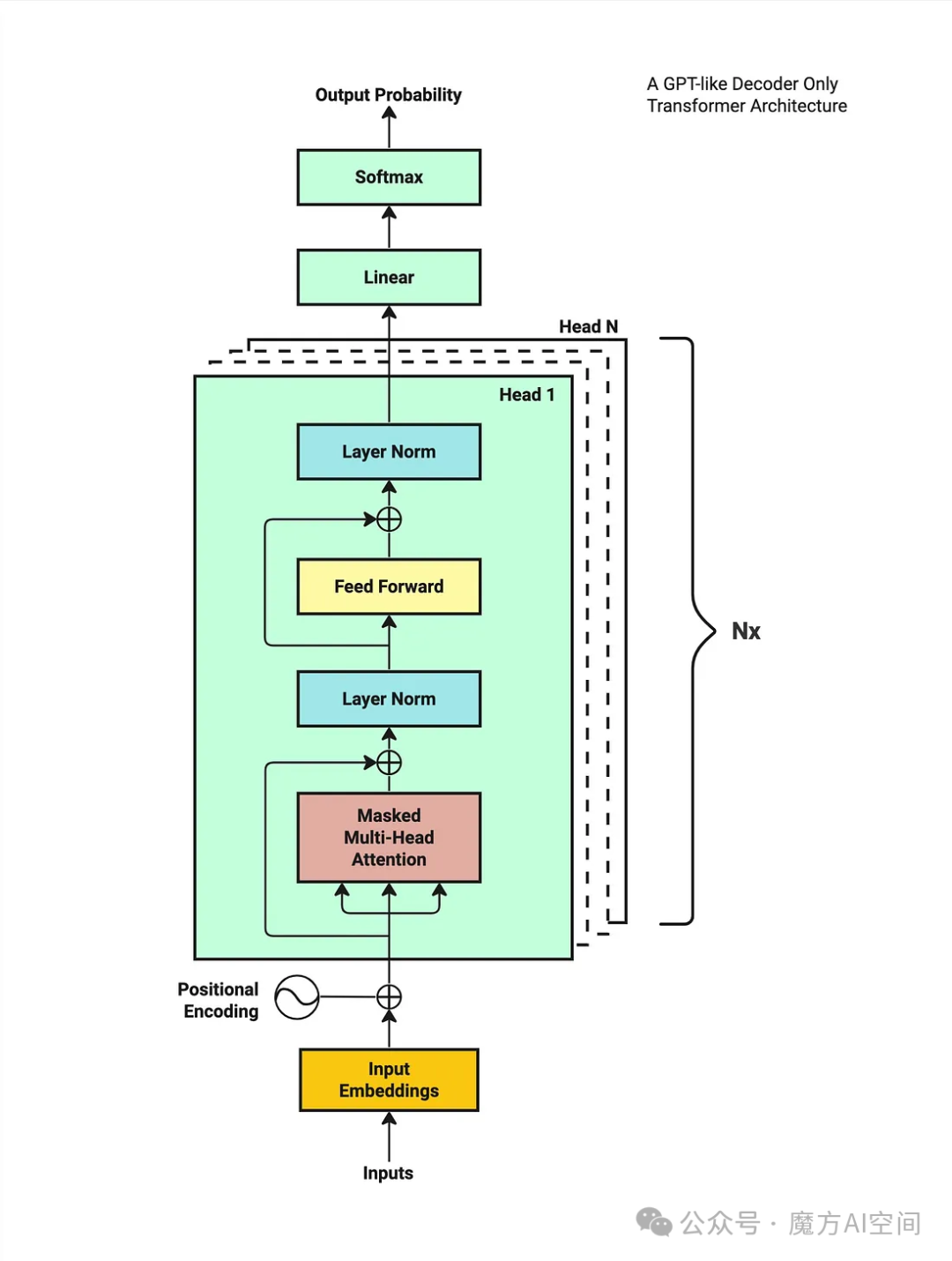
三、Transformer的架构
Transformer模型由编码器(Encoder)和解码器(Decoder)组成。
编码器
编码器由多个相同的编码器层(Encoder Layer)堆叠而成。每个编码器层包含一个多头自注意力机制和一个前馈神经网络(Feed-Forward Network)。
编码器的计算过程如下:
- 输入序列通过嵌入层(Embedding Layer)映射到高维空间。
- 加入位置编码,保留位置信息。
- 经过多个编码器层的处理,得到编码后的特征表示。
解码器
解码器与编码器类似,也由多个相同的解码器层(Decoder Layer)堆叠而成。每个解码器层包含一个多头自注意力机制、一个编码器-解码器注意力机制和一个前馈神经网络。
解码器的计算过程如下:
- 输入序列通过嵌入层映射到高维空间。
- 加入位置编码,保留位置信息。
- 经过多个解码器层的处理,结合编码器的输出,得到解码后的特征表示。
- 通过线性变换和softmax层,生成最终的预测结果。
四、Transformer的应用场景
机器翻译
Transformer在机器翻译任务中表现出了卓越的性能。通过将源语言序列编码成高维特征表示,再由解码器将其转换为目标语言序列,Transformer能够实现高质量的翻译。
文本生成
Transformer模型可以用于生成连贯的文本,如新闻报道、小说段落等。通过训练模型预测序列中的下一个单词,Transformer能够生成符合上下文的自然语言文本。
文本分类
Transformer可以应用于文本分类任务,如情感分析、新闻分类等。通过对输入文本进行编码并将其映射到类别标签,Transformer能够实现高效的文本分类。
问答系统
Transformer在问答系统中也有广泛应用。通过将问题和上下文编码成高维特征表示,模型能够从中提取答案,实现自动问答。
五、Transformer的训练和优化
数据准备
训练Transformer模型需要大量的高质量数据。以机器翻译任务为例,我们需要准备成对的源语言和目标语言句子。
import torch
from torchtext.data import Field, BucketIterator
from torchtext.datasets import Multi30k
# 定义字段
SRC = Field(tokenize="spacy", tokenizer_language="de", init_token="<sos>", eos_token="<eos>", lower=True)
TRG = Field(tokenize="spacy", tokenizer_language="en", init_token="<sos>", eos_token="<eos>", lower=True)
# 加载数据集
train_data, valid_data, test_data = Multi30k.splits(exts=(".de", ".en"), fields=(SRC, TRG))
# 构建词汇表
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
# 创建迭代器
BATCH_SIZE = 128
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
模型训练
模型训练包括前向传播、计算损失和反向传播更新参数。
import torch.nn as nn
import torch.optim as optim
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, trg_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout):
super(TransformerModel, self).__init__()
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.trg_embedding = nn.Embedding(trg_vocab_size, d_model)
self.position_encoding = nn.Parameter(torch.zeros(1, 5000, d_model))
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
self.fc_out = nn.Linear(d_model, trg_vocab_size)
def forward(self, src, trg):
src_seq_len, trg_seq_len = src.shape[0], trg.shape[0]
src = self.src_embedding(src) + self.position_encoding[:, :src_seq_len, :]
trg = self.trg_embedding(trg) + self.position_encoding[:, :trg_seq_len, :]
output = self.transformer(src, trg)
output = self.fc_out(output)
return output
# 初始化模型
src_vocab_size = len(SRC.vocab)
trg_vocab_size = len(TRG.vocab)
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
dropout = 0.1
model = TransformerModel(src_vocab_size, trg_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=TRG.vocab.stoi[TRG.pad_token])
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# 训练模型
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg[:-1, :])
output_dim = output.shape[-1]
output = output.view(-1, output_dim)
trg = trg[1:].view(-1)
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# 模型训练循环
N_EPOCHS = 10
CLIP = 1
for epoch in range(N_EPOCHS):
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
print(f'Epoch: {epoch+1}, Train Loss: {train_loss:.3f}')
模型优化
模型优化包括超参数调整、使用预训练模型和模型集成等。可以通过调整学习率、增加正则化等方法提升模型性能。
六、测试接口与详细解释
单元测试
以下示例展示了如何使用unittest进行Transformer模型的单元测试。
import unittest
import torch
from torchtext.data import Field
from torchtext.datasets import Multi30k
from model import TransformerModel
class TestTransformerModel(unittest.TestCase):
def setUp(self):
self.src_vocab_size = 10000
self.trg_vocab_size = 10000
self.d_model = 512
self.nhead = 8
self.num_encoder_layers = 6
self.num_decoder_layers = 6
self.dim_feedforward = 2048
self.dropout = 0.1
self.model = TransformerModel(self.src_vocab_size, self.trg_vocab_size, self.d_model, self.nhead, self.num_encoder_layers, self.num_decoder_layers, self.dim_feedforward, self.dropout)
def test_model_structure(self):
self.assertEqual(len(list(self.model.parameters())), 370, "Model parameters count mismatch")
def test_forward_pass(self):
src = torch.randint(0, self.src_vocab_size, (32, 128))
trg = torch.randint(0, self.trg_vocab_size, (32, 128))
output = self.model(src, trg)
self.assertEqual(output.shape, (32, 128, self.trg_vocab_size), "Output shape mismatch")
if __name__ == '__main__':
unittest.main()
接口测试
以下示例展示了如何使用unittest进行Transformer模型接口的测试。
import unittest
import requests
class TestTransformerAPI(unittest.TestCase):
def test_translate(self):
url = "http://localhost:8000/translate"
data = {"src": "Hallo Welt", "trg": ""}
response = requests.post(url, json=data)
self.assertEqual(response.status_code, 200, "API response status code mismatch")
self.assertIn("Hello World", response.json()["translation"], "Translation result mismatch")
if __name__ == '__main__':
unittest.main()
七、总结
本文详细介绍了Transformer模型的基础原理、架构、应用场景以及如何进行模型的训练、优化和测试。Transformer以其高效的并行计算和卓越的性能,成为NLP领域的重要模型。通过深入理解Transformer的工作机制,开发者可以更好地应用这一强大的工具,解决实际中的各种问题。
👉 最后,愿大家都可以解决工作中和生活中遇到的难题,剑锋所指,所向披靡~