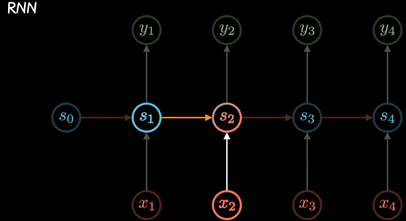
Transformer 是一种在自然语言处理(NLP)领域具有革命性影响的神经网络架构,由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中首次提出。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)的设计,完全依赖于自注意力机制(Self-Attention)来处理输入数据,这使得 Transformer 在处理长序列数据时更加高效,并且能够并行化训练,大大加速了训练过程。
Transformer 的一些关键特性:
自注意力机制:
自注意力机制允许模型中的每一个位置上的词都能够关注到序列中的所有其他位置,从而捕捉到全局上下文信息。
多头注意力(Multi-Head Attention)允许模型在不同的表示子空间中并行地关注不同的信息,增强了模型的表达能力。
位置编码:
由于自注意力机制本身无法感知词的位置信息,Transformer 引入了位置编码(Positional Encoding),以向模型提供序列中词的位置信息。
前馈神经网络层:
Transformer 中的每个编码器和解码器层都包含一个完全连接的前馈神经网络,用于进一步处理特征。
层归一化:
层归一化(Layer Normalization)用于加速训练和提高模型性能。
编码器-解码器结构:
Transformer 通常由多个相同的编码器层和解码器层组成,编码器负责理解输入序列,解码器负责生成输出序列。
并行计算:
由于自注意力机制的并行特性,Transformer 可以在GPU上进行高效的并行计算,从而大大减少训练时间。
Transformer的后续发展与应用
BERT (Bidirectional Encoder Representations from Transformers)
BERT 是 Google 在 2018 年发布的一种预训练模型,它利用 Transformer 的编码器部分,通过双向训练(同时考虑词的前后文)来学习语言的深度双向表示。BERT 的出现极大地提升了自然语言理解任务的性能,例如问答、情感分析和命名实体识别。
GPT (Generative Pre-trained Transformer) 系列
GPT 系列模型(包括 GPT-1, GPT-2, GPT-3 和 GPT-4)专注于文本生成任务,使用 Transformer 的解码器部分进行单向训练。GPT 模型在无监督预训练阶段学习语言模式,然后可以微调到特定的下游任务,如文本生成、对话系统和代码生成。
T5 (Text-to-Text Transfer Transformer)
T5 将所有 NLP 任务统一为文本到文本的形式,无论是分类还是生成任务,都视为从一段文本转换成另一段文本的问题。这种方法简化了模型设计,提高了模型的泛化能力。
RoBERTa (Robustly Optimized BERT Approach)
RoBERTa 对 BERT 进行了改进,通过更长的训练时间、更大的批量大小和动态掩码策略等优化,进一步提高了模型的性能。
DistilBERT
DistilBERT 是一种轻量级的 BERT 模型,通过知识蒸馏技术将大型预训练模型的知识压缩到较小的模型中,降低了计算成本,适用于资源受限的设备。
XLNet
XLNet 结合了 Transformer-XL 和双向训练的优势,通过预测序列中所有可能的下一个词来训练模型,从而避免了 BERT 中的一些限制,如遮蔽词预测的局限性。
ERNIE (Enhanced Representation through kNowledge Integration)
ERNIE 是百度开发的预训练模型,它结合了知识图谱的信息,使模型能够理解和利用外部知识,增强对语义的理解。
Transformer的最新进展与未来方向
多模态Transformer
最新的研究开始探索将Transformer应用于图像、视频和音频等非文本数据,实现跨模态的融合。例如,ViT (Vision Transformer) 将图像分割成一系列patch,并将其作为序列输入到Transformer中,展示了在计算机视觉任务上的强大性能。
超大规模预训练
随着计算资源的增加,研究人员开始训练拥有数十亿甚至万亿参数的超大规模模型,如GPT-3和Switch Transformer。这些模型在大量数据上进行预训练,展现出惊人的泛化能力和创造力,能够完成复杂的语言任务,甚至是一些未经过明确训练的任务。
低资源和零样本学习
Transformer模型正在被优化,以在数据稀缺的情况下也能表现良好,或者在没有额外训练数据的情况下适应新任务(零样本学习)。这通常涉及到模型的架构调整或训练策略的创新。
可解释性和透明度
随着Transformer模型变得越来越复杂,理解它们如何做出决策变得至关重要。研究者正在努力开发工具和技术,以提高模型的可解释性和透明度,帮助人们理解模型内部的工作原理。
持续学习和在线学习
Transformer模型正在被设计为能够在部署后继续学习和适应新数据,而无需重新训练整个模型。这种能力对于处理动态变化的数据集尤其重要。
环境友好型模型
训练超大规模模型需要巨大的计算资源,这带来了能源消耗和碳排放的问题。因此,研究者正在寻找方法来降低模型训练的环境影响,比如通过更有效的算法和硬件优化。
伦理和社会影响
随着AI模型在社会中的应用越来越广泛,其潜在的社会影响和伦理问题也引起了关注。研究者正在探索如何确保AI系统的公平性、隐私保护和责任。
多语言和跨语言学习
Transformer模型正在被训练成能够理解和生成多种语言的多语言模型,这有助于缩小全球语言障碍,促进不同文化之间的交流。
随着技术的不断发展,Transformer将继续在其核心领域取得突破,并扩展到更多新的应用领域,成为推动人工智能进步的关键力量。