1.RocketMQ的架构是怎么样的?
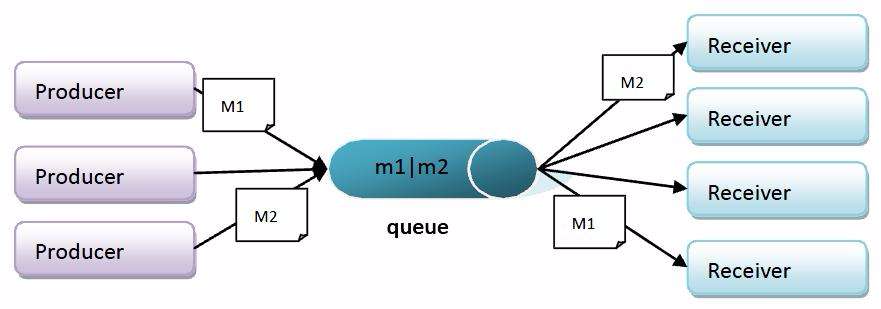
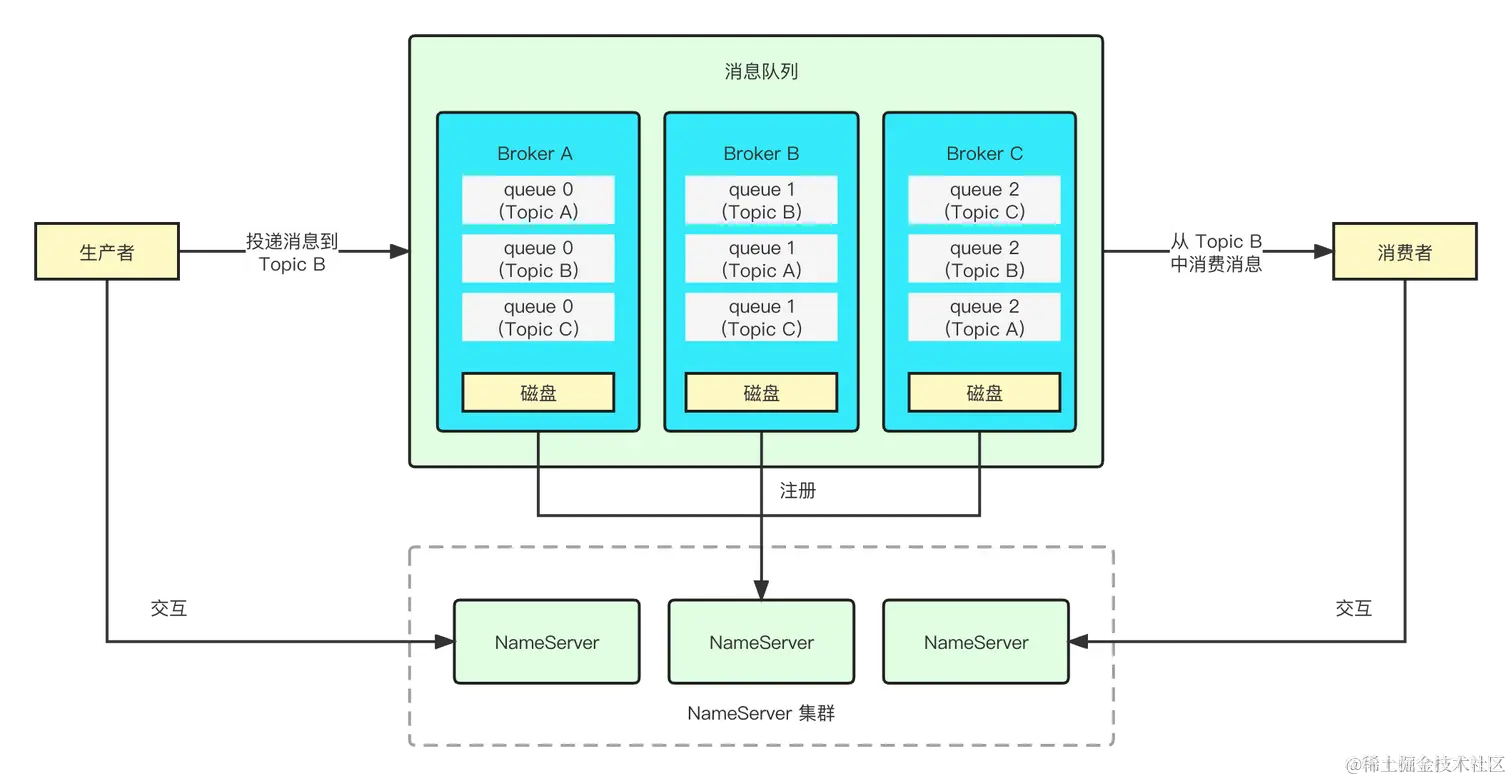
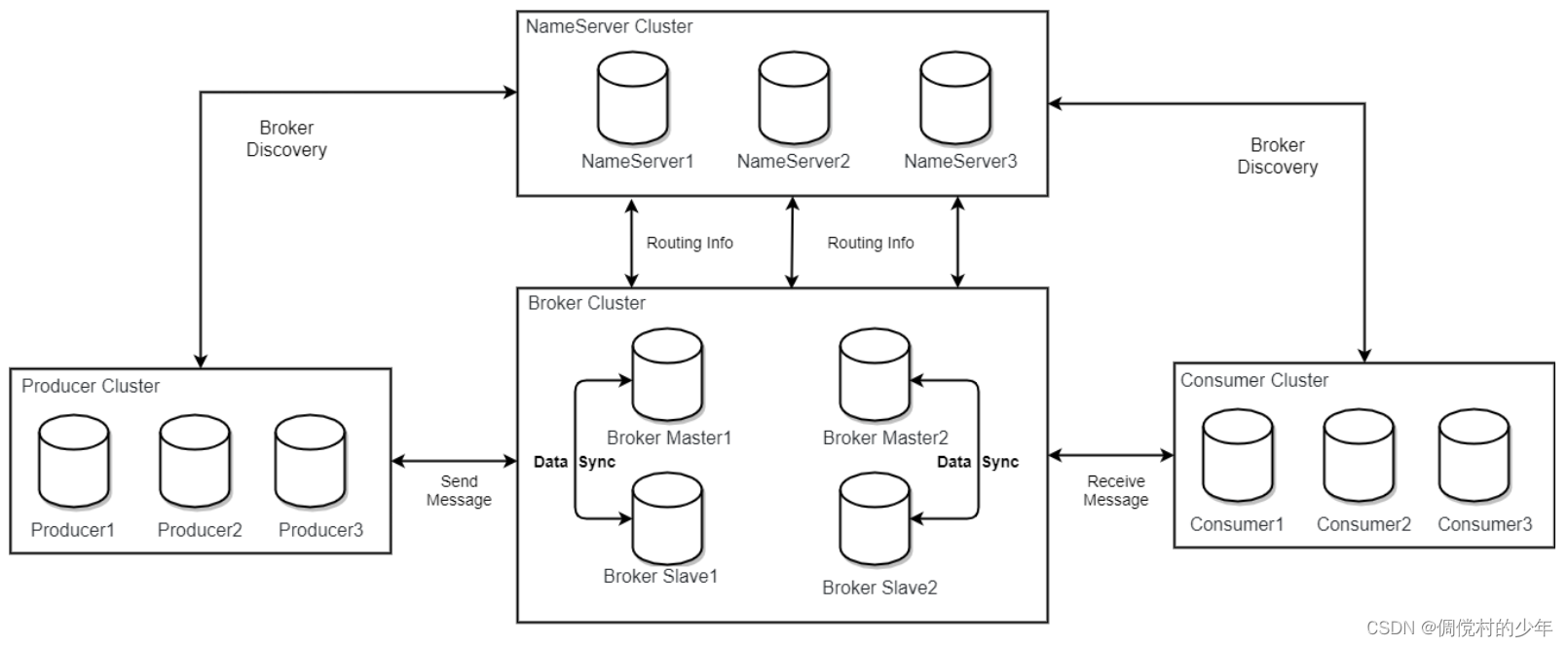
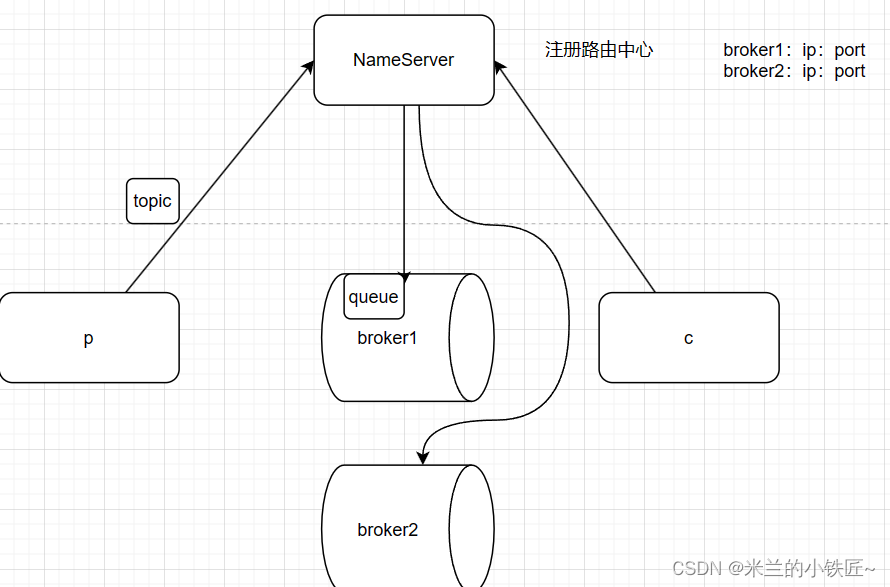
RocketMQ主要由Producer、Broker和Consumer三部分组成,如下图所示:
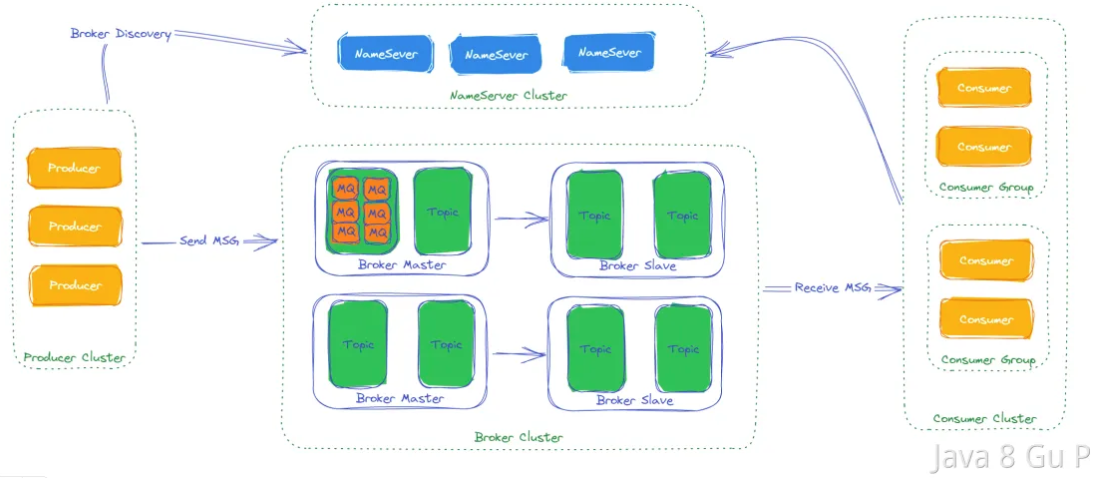
Producer:消息生产者,负责将消息发送到Broker。
Broker:消息中转服务器,负责存储和转发消息。RocketMQ支持多个Broker构成集群,每个Broker都拥有独立的存储空间和消息队列。
Topic:消息主题,是消息的逻辑分类单位。Producer将消息发送到特定的Topic中,Consumer从指定的Topic中消费消息。
Message Queue:消息队列,是Topic的物理实现。一个Topic可以有多个Queue,每个Queue都是独立的存储单元。Producer发送的消息会被存储到对应的Queue中,Consumer从指定的Queue中消费消息。
Consumer:消息消费者,负责从Broker消费消息。
NameServer:名称服务,维护了Broker地址、Topic和Queue等元数据信息及它们之间的映射关系。Producer和Consumer在启动时需要连接到NameServer获取Broker的地址信息。
2.RocketMQ的事务消息是如何实现的?
RocketMQ的事务消息是通过TransactionListener接口来实现的。
在发送事务消息时,首先向RocketMQ Broker发送一条“half消息”(即半消息),半消息将被存储在Broker端的事务消息日志中,但是这个消息还不能被消费者消费。
接下来,在半消息发送成功后,应用程序通过执行本地事务来确定是否要提交该事务消息。
如果本地事务执行成功,就会通知RocketMQ Broker提交该事务消息,使得该消息可以被消费者消费;否则,就会通知 RocketMQ Broker 回滚该事务消息,该消息将被删除,从而保证消息不会被消费者消费。
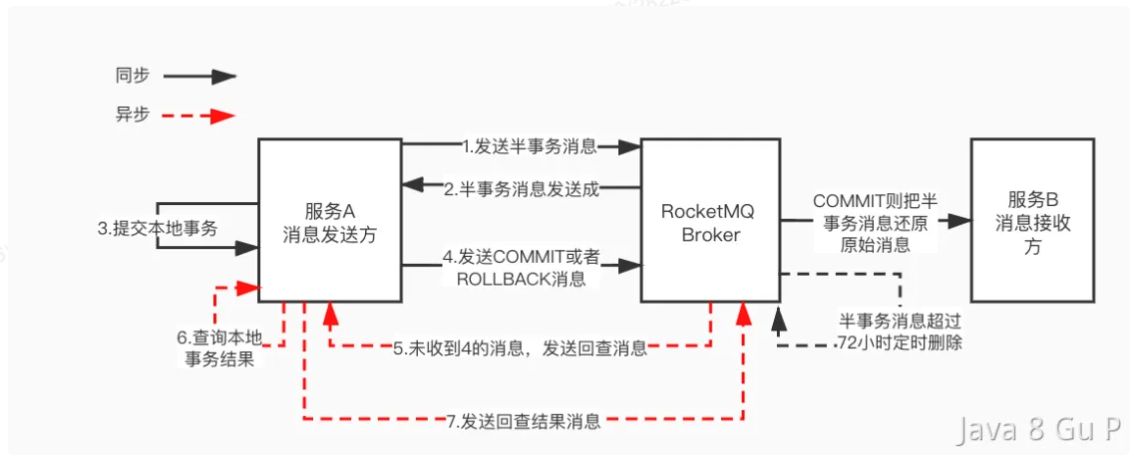
拆解下来的话,主要有以下4个步骤:
发送半消息:应用程序向RocketMQ Broker发送一条半消息,该消息在Broker端的事务消息日志中被标记为"prepared"状态。
执行本地事务:RocketMQ会通知应用程序执行本地事务。如果本地事务执行成功,应用程序通知RocketMQ Broker 提交该事务消息。
提交事务消息:RocketMQ Broker 收到提交消息以后,会在事务消息日志中将该消息的状态从"prepared"改为"committed",消息最终会进入消息队列,使得该消息可以被消费者消费。
回滚事务消息:如果本地事务执行失败,应用程序通知 RocketMQ Broker 回滚该事务消息,RocketMQ 将该消息的状态从"prepared"改为"rollback",并将该消息从事务消息日志中删除,从而保证该消息不会被消费者消费。
未知事务状态:如果Broker收到的消息不能确认本地事务执行成功还是失败,Broker每隔一段时间会对未提交的半事务消息进行回查,来获取事务状态。
3.RocketMQ如何保证消息的有序性?
RocketMQ中提供了基于队列的顺序消费。即同一个队列内的消息可以做到有序。需要发送顺序消息时,
在生产者一方,需要在send方法中,传入一个MessageQueueSelector,并且,MessageQueueSelector中需要实现一个select方法,这个方法就是用来定义要把消息发送到哪个MessageQueue的,通常可以使用取模法进行路由:
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
//mqs:该Topic下所有可选的MessageQueue
//msg:待发送的消息
//arg:发送消息时传递的参数
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
//根据参数,计算出一个要接收消息的MessageQueue的下标
int index = id % mqs.size();
//返回这个MessageQueue
return mqs.get(index);
}
}, orderId);在消费者一方,需要使用MessageListener回调函数的有序消费模式MessageListenerOrderly接收消息:
consumer.registerMessageListener(new MessageListenerOrderly() {
Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs ,ConsumeOrderlyContext context) {
System.out.printf("Receive order msg:" + new String(msgs.get(0).getBody()));
return ConsumeOrderlyStatus.SUCCESS;
}
});消费者还需要通过三次加锁来保证顺序消费,这个加锁过程是自动的:
1. 分布式锁申请:
- 消费者初始化时,ConsumeMessageOrderlyService 会尝试向 Broker 申请分布式锁。如果获取成功,后续该消费者组的消息将只分发给当前消费者。
2. MessageQueue加锁:
- 在开始实际处理消息之前,需要申请 MessageQueue 锁。申请成功后,可以确保在同一时间内,同一个队列中只有一个消费者线程可以处理消息。这样可以保证消息在同一个队列中被顺序处理。
3. ProcessQueue加锁:
- 在消息拉取的过程中,消费者会一次性拉取多条消息,并将其放入本地的 ProcessQueue 中。
- 在处理 ProcessQueue 中的消息时,为了确保在重平衡(例如消费者加入或退出)期间不会出现消息重复消费,需要对 ProcessQueue 进行加锁。
4.RocketMQ如何保证消息不丢失?
RocketMQ的消息想要确保不丢失,需要生产者、消费者以及Broker的共同努力,缺一不可。
在生产者端,消息的发送分为同步发送和异步发送。同步发送是丢失几率最小的一种发送方式,消息的发送会同步阻塞等待Broker返回结果,在Broker确认收到消息之后,生产者才会拿到SendResult。如果这个过程中发生异常,那么就说明消息发送可能失败了,就需要生产者进行重新发送消息。
在Broker端,Broker接收到消息后会把消息先存储到内存中,存储成功之后,就返回确认结果给生产者。Broker自己会通过异步刷盘的方式将内存中的数据刷新到磁盘上。但是这个过程中,如果机器挂了,那么就可能会导致数据丢失。如果想要保证消息不丢失,可以将消息保存机制修改为同步刷盘,这样,Broker会在同步请求中把数据保存在磁盘上,确保保存成功后再返回确认结果给生产者。
#默认情况为ASYNC_FLUSH
flushDiskType = SYNC_FLUSH为了进一步保证消息不丢失,Broker还可以通过集群的方式进行部署,通常采用一主多从的部署方式,并且采用主从同步的方式做数据复制。当主Broker宕机时,从Broker会接管主Broker的工作,保证消息不丢失。同时,RocketMQ的Broker还可以配置多个实例,消息会在多个Broker之间进行冗余备份,从而保证数据的可靠性。
默认方式下,Broker在接收消息后,写入 master 成功,就可以返回确认响应给生产者了,接着消息将会异步复制到 slave 节点。但是如果这个过程中,Master的磁盘损坏了。那就会导致数据丢失了。
如果想要解决这个问题,可以配置同步复制的方式,即Master在将数据同步到Slave节点后,再返回给生产者确认结果。
#默认为ASYNC_MASTER
brokerRole=SYNC_MASTER在消费者端,需要确保在消息拉取并消费成功之后再给Broker返回ACK,就可以保证消息不丢失了,如果这个过程中Broker一直没收到ACK,那么就可以重试。所以,在消费者的代码中,一定要在业务逻辑的最后一步return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; 当然,也可以先把数据保存在数据库中,就返回,然后自己再慢慢处理。
但是,需要注意的是RocketMQ只能最大限度的保证消息不丢失,没有办法做到100%保证不丢失。
5.RocketMQ有几种集群方式?
3种,分别是单Master模式、多Master模式以及多Master多Slave模式。
单Master集群:这是一种最简单的集群方式,只包含一个Master节点和若干个Slave节点。所有的写入操作都由Master节点负责处理,Slave节点主要用于提供读取服务。当Master节点宕机时,集群将无法继续工作。
多Master集群:这种集群方式包含多个Master节点,不部署Slave节点。这种方式的优点是配置简单,单个Master宕机或重启维护对应用无影响。在磁盘配置为RAID10时,即使机器宕机不可恢复的情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;缺点是单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave集群:这种集群方式包含多个Master节点和多个Slave节点。每个Master节点都可以处理写入操作,并且有自己的一组Slave节点。当其中一个Master节点宕机时,消费者仍然可以从Slave消费。优点是数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;缺点是性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
6.RocketMQ消息堆积了怎么解决?
RocketMQ的消息堆积,一般都是因为客户端本地消费过程中,由于消费耗时过长或消费并发度较小等原因,导致客户端消费能力不足,出现消息堆积的问题。
当线上出现消息堆积的问题时,一般有以下几种方式来解决:
增加消费者数量:消息堆积了,消费不过来了,那就把消费者的数量增加一下,让更多的实例来消费这些消息。
提升消费者消费速度:消费者消费的慢可能是消息堆积的主要原因,想办法提升消费速度,比如引入线程池、本地消息存储后即返回成功后续再慢慢消费等。
降低生产者的生产速度:如果生产者可控的话,可以让生产者生成消息的速度慢一点。
增加 Topic 队列数:如果一个 Topic 的队列数比较少,那么就容易出现消息堆积的情况。可以通过增加队列数来提高消息的处理并发度,从而减少消息堆积。
清理过期消息:有一些过期消息、或者一直无法成功的消息,在业务做评估之后,如果无影响或者影响不大,其实是可以清理的。
调整 RocketMQ 的配置参数:RocketMQ 提供了很多可配置的参数,例如消息消费模式、消息拉取间隔时间等,可以根据实际情况来调整这些参数,从而优化消息消费的效率。
7.介绍一下RocketMQ的工作流程?
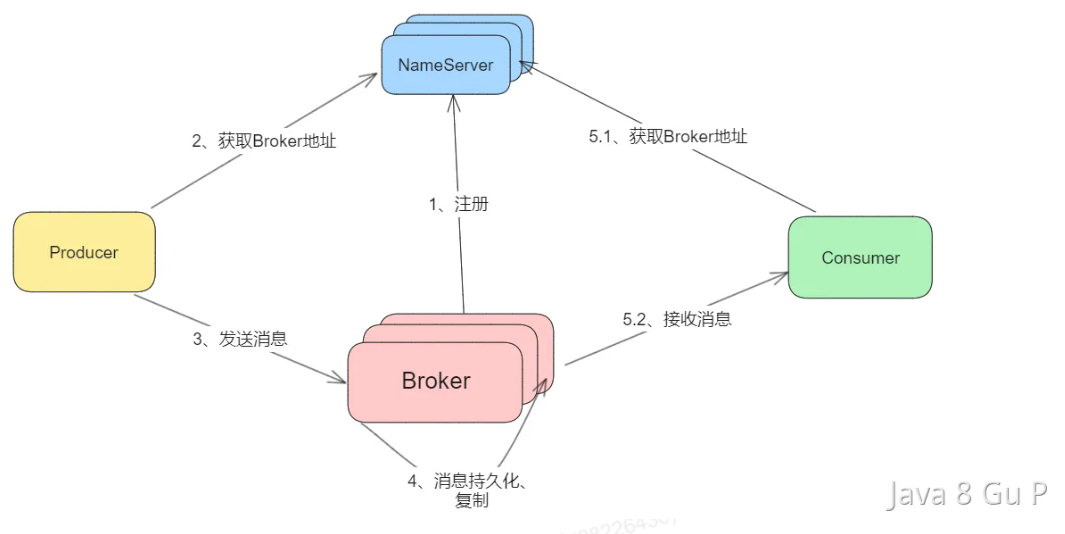
1、启动NameServer,他会等待Broker、Producer以及Consumer的链接。
2、启动Broker,会和NameServer建立连接,定时发送心跳包。心跳包中包含当前Broker信息(ip、port等)、Topic信息以及Borker与Topic的映射关系。
3、启动Producer,启动时先随机和NameServer集群中的一台建立长连接,并从NameServer中获取当前发送的Topic所在的所有Broker的地址;然后从队列列表中轮询选择一个队列,与队列所在的Broker建立长连接,进行消息的发送。
4、Broker接收Producer发送的消息,当配置为同步复制时,master需要先将消息复制到slave节点,然后再返回“写成功状态”响应给生产者;当配置为同步刷盘时,则还需要将消息写入磁盘中,再返回“写成功状态”;要是配置的是异步刷盘和异步复制,则消息只要发送到master节点,就直接返回“写成功”状态。
5、启动Consumer,过程和Producer类似,先随机和一台NameServer建立连接,获取订阅信息,然后在和需要订阅的Broker建立连接,获取消息。
8.RocketMQ怎么实现消息分发的?
RocketMQ 支持两种消息模式:广播消费( Broadcasting )和集群消费( Clustering )。
广播消费:当使用广播消费模式时,RocketMQ 会将每条消息推送给集群内所有的消费者,保证消息至少被每个消费者消费一次。

广播模式下,RocketMQ 保证消息至少被客户端消费一次,但是并不会重投消费失败的消息,因此业务方需要关注消费失败的情况。并且,客户端每一次重启都会从最新消息消费。客户端在被停止期间发送至服务端的消息将会被自动跳过。
集群消费:当使用集群消费模式时,RocketMQ 认为任意一条消息只需要被集群内的任意一个消费者处理即可。
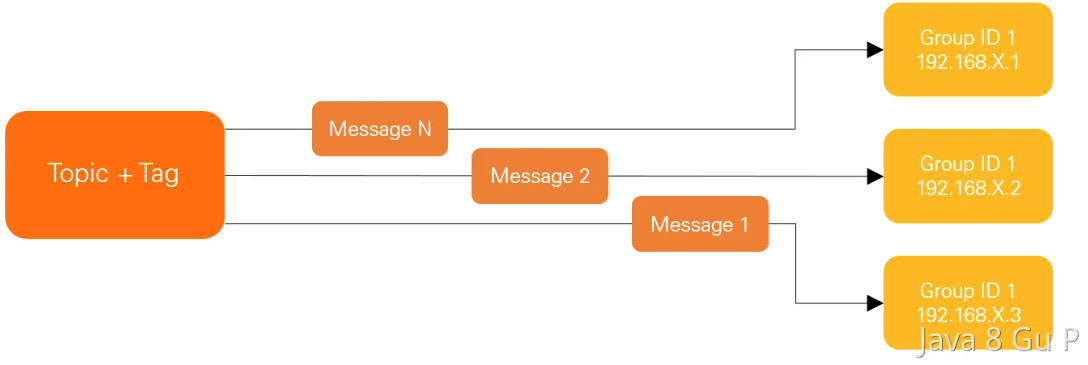
集群模式下,每一条消息都只会被分发到一台机器上处理。但是不保证每一次失败重投的消息路由到同一台机器上。一般来说,用集群消费的更多一些。
通过设置MessageModel可以调整消费方式:
// MessageModel设置为CLUSTERING(不设置的情况下,默认为集群订阅方式)。
properties.put(PropertyKeyConst.MessageModel, PropertyValueConst.CLUSTERING);
// MessageModel设置为BROADCASTING。
properties.put(PropertyKeyConst.MessageModel, PropertyValueConst.BROADCASTING);9.RocketMQ的消息是推还是拉?
RocketMQ的消费模式分为两种,一种是推(Push),一种是拉(Pull),开发者可以自行选择。
推是服务端主动推送消息给客户端,拉是客户端需要主动到服务端轮询获取数据。
推的优点是及时性较好,但如果客户端没有做好流控,一旦服务端推送大量消息到客户端时,就会导致客户端消息堆积甚至崩溃。
拉优点是客户端可以依据自己的消费能力进行消费,但是频繁拉取会给服务端造成压力,并且可能会导致消息消费不及时。
需要注意的是,RocketMQ的push模式其实底层的实现还是基于pull实现的,只不过他把pull给封装的比较好,让你以为是在push。
public class DefaultMQPullConsumer extends ClientConfig implements MQPullConsumer
public class DefaultMQPushConsumer extends ClientConfig implements MQPushConsumer10.用了RocketMQ一定能实现削峰的效果吗?
在高并发场景下,系统可能会面临短时间内大量请求涌入,导致系统负载急剧上升,甚至超过系统的处理能力,造成服务瘫痪。使用MQ来缓冲这些请求,可以将大量并发请求暂存到队列中,然后按照系统能够处理的速度逐渐消费这些请求。这样可以避免系统因为瞬间的高并发而崩溃,实现系统流量的平滑处理。这就是削峰填谷。
但是,并不是说用了MQ了就一定实现了削峰填谷了。这要看MQ的消费方式。
MQ的消息有推和拉两种模式,如果是那种推的模式,会在上游发送消息之后,就立即推给消费者,那这种情况对于接收消息的人来说,还是承担了很大的请求量。而如果消费者的消费能力不行,那么消息也会堆积到消费者端。
并且一旦消息量太大,也会导致消费失败,那么消息就会重投,这就会导致更多的请求量过来。
所以,如果想要起到很好地削峰填谷的作用,需要使用拉模式来消费消息,这样自己就可以控制速度了。消息就可以在MQ的队列中堆积,而不是在客户端堆积,通过队列的缓冲来起到削峰填谷的作用!