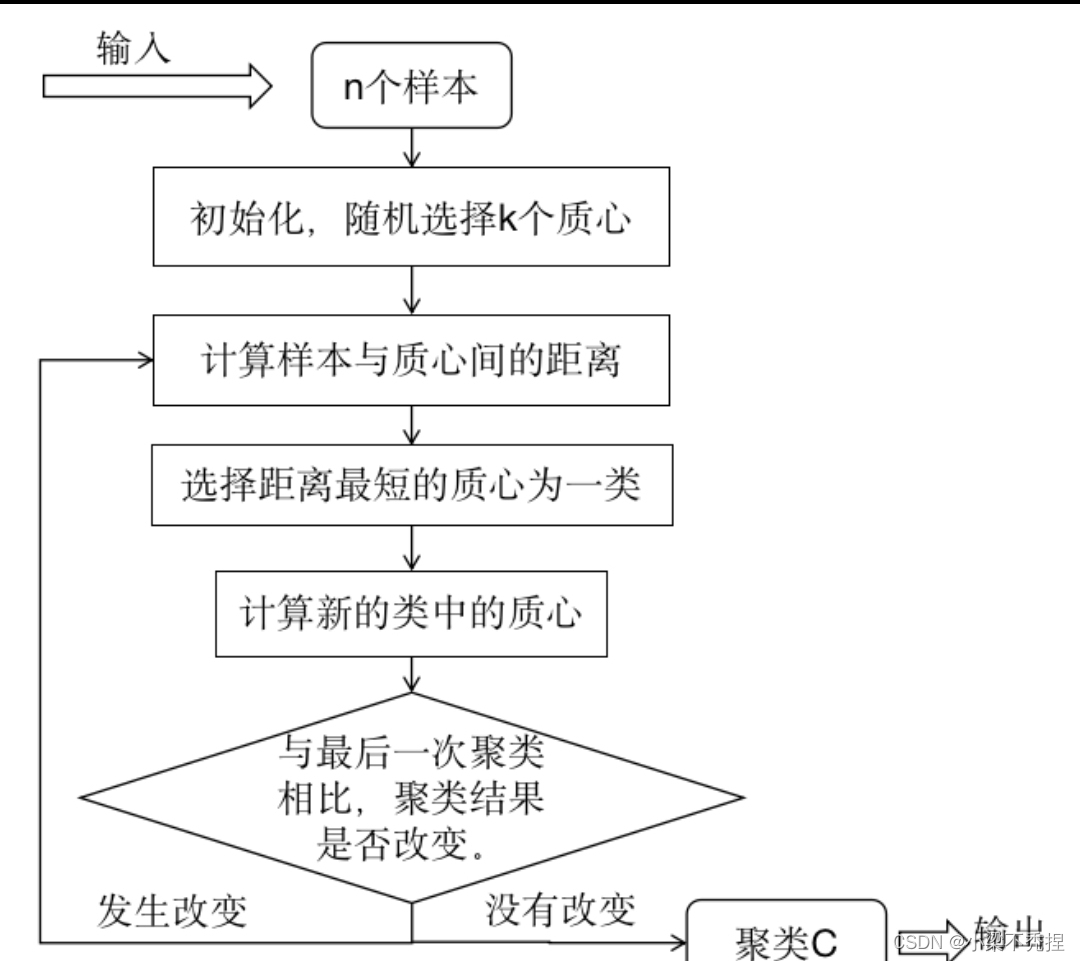
用sklearn实现决策树与随机森林
1. 简介
决策树和随机森林是机器学习中的两种强大算法。决策树通过学习数据特征与标签之间的规则来进行预测,而随机森林则是由多棵决策树组成的集成算法,能有效提高模型的稳定性和准确性。
2. 安装sklearn
首先,确保安装了scikit-learn库。如果没有安装,可以使用以下命令进行安装:
pip install scikit-learn
3. 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
from sklearn import tree
4. 加载数据集
我们将使用一个示例数据集来展示决策树和随机森林的实现。这里我们使用sklearn自带的iris数据集。
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
5. 决策树分类器
5.1 训练决策树模型
# 初始化决策树分类器
dt_classifier = DecisionTreeClassifier(random_state=42)
# 训练模型
dt_classifier.fit(X_train, y_train)
5.2 模型预测与评估
# 进行预测
y_pred_dt = dt_classifier.predict(X_test)
# 评估模型
accuracy_dt = accuracy_score(y_test, y_pred_dt)
conf_matrix_dt = confusion_matrix(y_test, y_pred_dt)
class_report_dt = classification_report(y_test, y_pred_dt)
print(f"决策树分类器准确率: {accuracy_dt}")
print("决策树分类器混淆矩阵:\n", conf_matrix_dt)
print("决策树分类器分类报告:\n", class_report_dt)
5.3 可视化决策树
plt.figure(figsize=(20,10))
tree.plot_tree(dt_classifier, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
6. 随机森林分类器
6.1 训练随机森林模型
# 初始化随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
6.2 模型预测与评估
# 进行预测
y_pred_rf = rf_classifier.predict(X_test)
# 评估模型
accuracy_rf = accuracy_score(y_test, y_pred_rf)
conf_matrix_rf = confusion_matrix(y_test, y_pred_rf)
class_report_rf = classification_report(y_test, y_pred_rf)
print(f"随机森林分类器准确率: {accuracy_rf}")
print("随机森林分类器混淆矩阵:\n", conf_matrix_rf)
print("随机森林分类器分类报告:\n", class_report_rf)
7. 比较与总结
决策树和随机森林各有优缺点。决策树简单易理解,但容易过拟合;随机森林通过集成多棵决策树提高了模型的稳定性和泛化能力。通过上述步骤,我们可以看到在相同的数据集上,随机森林通常比单棵决策树表现更好。
8. 进一步阅读
通过这篇教程,你应该已经掌握了如何使用sklearn实现和评估决策树与随机森林分类器。如果有任何问题或进一步的需求,请随时告诉我!