命令执行的时候有时会输出数据,有的命令输出的数据太繁杂了。
那么我们怎么去筛选这些信息来得到我们所想要的格式?
这就牵涉到管道命令的问题了(pipe),管道命令使用的是【|】这个界定符号。另外,管道命令与【连续执行命令】是不一样的,这点下面我们再说明。
下面我们先举一个例子来说明一下简单的管道命令
假设我们想要知道/etc/下面有多少文件,那么可以利用Is/etc来查看,不过,因为/etc下面的文件太多,导致一口气就将屏幕塞满了,不知道前面输出的内容是啥?

此时,我们可以通过less命令的协助:如此一来,使用Is命令输出后的内容,就能够被 less 读取,并且利用less的功能,我们就能够前后翻动相关的信息了。很方便是吧?

我们就来了解一下这个管道命令【|】的用途吧!其实这个管道命令【|】仅能处理经由前面一个命令传来的正确信息,也就是标准输出的信息,对于标准错误并没有直接处理的能力。
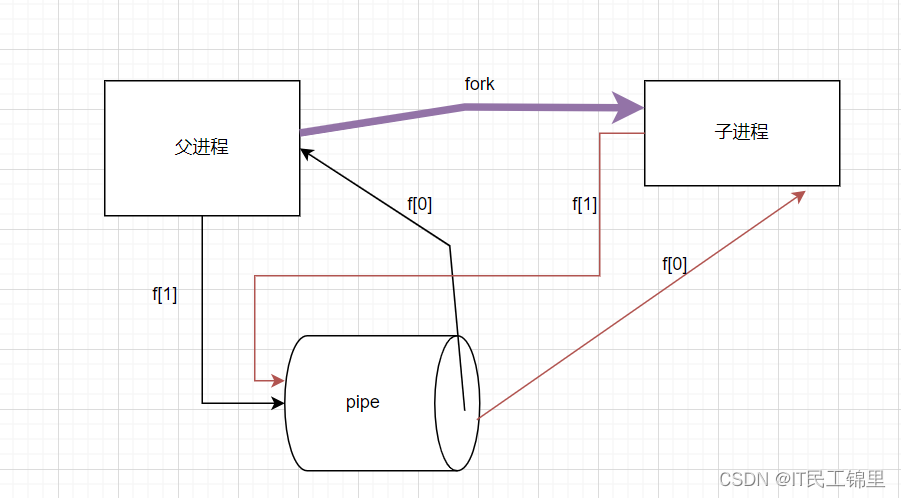
那么整体的管道命令可以使用下图表示;

在每个管道后面接的第一个数据必定是【命令】,而且这个命令必须要能够接受标准输入的数据才行,这样的命令才可为管道命令,
- 例如less、more、head、tail 等都是可以接受标准输入的管道命令,
- 至于例如 Is、cp、mv 等就不是管道命令。因为Is、cp、mv 并不会接受来自stdin 的数据,
也就是说,管道命令主要有两个比较需要注意的地方:
- 管道命令仅会处理标准输出,对于标准错误会予以忽略;
- 管道命令必须要能够接受来自前一个命令的数据成为标准输入继续处理才行。
想一想,如果你硬要让标准错误可以被管道命令所使用,那该如何处理?
其实就是通过数据流重定向,让2>&1加入命令中,就可以让2>变成1>,了解了吗?
多说无益,让我们来玩一些管道命令吧!下面的东西对系统管理非常有帮助。
1.选取命令:cut、grep
什么是选取命令?
说穿了,就是将一段数据经过分析后,取出我们所想要的,或是经由分析关键词,取得我们所想要的那一行。
不过,要注意的是,一般来说,选取信息通常是针对【一行一行】来分析的,并不是整篇信息分析,
下面我们介绍两个很常用的信息选取命令:
1.1.cut
cut 不就是【切】吗?
没错,这个命令可以将一段信息的某一段给它【切】出来,处理的信息是以【行】为单位,下面我们就来谈一谈:

- cut -d '分隔字符' -f fields<==用于有特定分隔字符。
- cut -c 字符区间 <==用于排列整齐的信息。
选项与参数:
- -d:后面接分隔字符,与-f一起使用;
- -f:根据-d的分隔字符将一段信息划分成为数段,用-f 取出第几段的意思;
- -c:以字符(characters)的单位取出固定字符区间;
范例一:将PATH变量取出,我要找出第五个路径。
我们是以【:】作为分隔,那么如果想要列出第3段与第5段?,就是这样:范例二:将export 输出的信息,取得第12字符以后的所有字符
.…(其他省略)……#注意看,每个数据都是排列整齐的输出,如果我们不想要【declare-x】时,就得这么做。
……(其他省略)…
#知道怎么回事了吧?用-c可以处理比较具有格式的输出数据,我们还可以指定某个范围的值,例如第12-20的字符、就是cut -c 12-20等.
.
范例三:用last 将显示的登录者的信息中,仅留下使用者大名。
last可以输出【账号/终端/来源/日期时间】的数据,并且是排列整齐的。
由输出的结果我们可以发现第一个空白分隔的栏位代表账号,所以使用如上命令.但是因为root pts/1之间空格有好几个,并不是只有一个,pts/1其实不能以cut -d ' ' -f 1,2所以,如果要找出,输出的结果会不是我们想要的。







cut 主要的用途在于将同一行里面的数据进行分解,最常使用在分析一些数据或文字数据的时候。这是因为有时候我们会以某些字符当作划分的参数,然后来将数据加以分割,以取得我们所需要的数据。
不过,cut在处理多空格相连的数据时,可能会比较吃力一点,所以某些时刻可能会使用awk来替换。
1.2.grep
刚刚的cut是将一行信息当中,取出某部分我们想要的,而grep则是分析一行信息,若当中有我们所需要的信息,就将该行拿出来,
简单的语法是这样的:
- grep [-acinv] [--color=auto] '查找字符' filename
选项与参数:
- -a:将二进制文件以文本文件的方式查找数据
- -c:计算找到‘查找字符’的次数。
- -i:忽略大小写的不同,所以大小写视为相同
- -n:顺便输出行号
- -v:反向选择,亦即显示出没有‘查找字符’内容的那一行。
- --color=auto:可以将找到的关键字部分加上颜色的显示
范例一:将last当中,有出现root的那一行就显示出来。
范例二:与范例一相反,只要没有root的就取出
范例三:在last 的输出信息中,只要有root 就取出,并且仅取第一栏。
#在取出root 之后,利用上个命令cut 的处理,就能够仅取得第一栏。
范例四:取出/etc/man db.conf内含MANPATH的那几行。
#神奇的是,如果加上--color=auto的选项,找到的关键字部分会用特殊颜色显示。




grep是个很棒的命令,它支持的语法实在是太多了,用在正则表达式里面,能够处理的数据实在是多得很。不过,我们这里先不谈正则表达式,您先了解一下,grep可以解析一行文字,取得关键词,若该行有存在关键词,就会整行列出来。
另外,CentOS7当中,默认的grep已经主动使用--color=auto选项在alias中了。
2.排序命令:sort、wc、uniq
很多时候,我们都会去计算一次数据里面的相同形式的数据总数,举例来说,使用last可以查得系统上面有登录主机者的身份。
那么我可以针对每个用户查出它们的总登录次数吗?
此时就要排序与计算之类的命令来辅助,下面我们介绍几个好用的排序与统计命令。
2.1.sort
sort 是很有趣的命令,它可以帮我们进行排序,而且可以根据不同的数据形式来排序,例如数字与文字的排序就不一样。
此外,排序的字符与语系的编码有关,因此,如果您需要排序时,建议使用LANG=C来让语系统一,数据排序比较好一些。

- sort [-fbMnrtuk] [file or stdin]
选项与参数:
- -f:忽略大小写的差异,例如A与a 视为编码相同;
- -b:忽略最前面的空格字符部分;
- -M:以月份的名字来排序,例如JAN、DEC等的排序方法;
- -n:使用【纯数字】进行排序(默认是以文字形式来排序的)反向排序;
- -u:就是unig,相同的数据中,仅出现一行代表;
- -t:分隔符号,默认是用[Tab]键来分隔;
- -k:以哪个区间(field)来进行排序的意思
范例一:个人账号都记录在/etc/passwd 下,请将账号进行排序
#省略很多的输出,由上面的信息看起来,sort是默认【以第一个】条信息来排序,而且默认是以【文字】形式来排序的,所以由a开始排到最后。范例二:/etc/passwd内容是以:来分隔的,我想以第三栏来排序,该如何?
+看到特殊字体的输出部分了吧?怎么会这样排列?呵呵,没错。如果是以文字形式来排序的话,原本就会是这样,想要使用数字排序:
这样才行,用那个-n来告知sort 以数字来排序。范例三:利用last,将输出的数据仅显示账号,并加以排序。




sort 同样是很常用的命令,因为我们常常需要比较一些信息。
举个上面的第二个例子来说,今天假设你有很多的账号,而且你想要知道最大的用户ID目前到哪一个了。呵呵,使用sort 一下子就可以知道答案。当然其使用还不止此,有空的话不妨玩一玩。
2.2.uniq
如果我排序完成了,想要将重复的数据仅列出一个显示,可以怎么做?

- uniq [-ic]
选项与参数:
- -i:忽略大小写字符的不同;
- -c:进行计数;
范例一,使用last 将账号列出,仅取出账号栏,进行排序后仅取出一位.
范例二:承上题,如果我还想要知道每个人的登录总次数?
从上面的结果可以发现reboot有6次,root 登录则有23次,大部分是以zs_108来操作.
#wtmp与第一行的空白都是1ast的默认字符,那两个可以忽略的。


这个命令用来将重复的行删除掉只显示一个,
举个例子来说,你要知道这个月份登录你主机的用户有谁,而不在乎它的登录次数,那么就使用上面的范例,(1)先将所有的数据列出;(2)再将人名独立出来;(3)经过排序;(4)只显示一个。由于这个命令是在将重复的东西减少,所以当然需要配合排序过的文件来处理
2.3.wc
如果我想要知道/etc/man_db.conf这个文件里面有多少字?多少行?多少字符的话,可以怎么做?
其实可以利用wc 这个命令来完成,它可以帮我们计算输出信息的整体数据。

- wc [-lwm]
选项与参数:
- -l:仅列出行
- -w:仅列出多少字(英文字母);
- -m:多少字符;
范例一:那个/etc/man db.conf里面到底有多少相关字、行、字符数?
输出的三个数字中,分别代表:【行、字数、字符数】范例二:使用last可以输出登录者,但是last 最后两行并非账号内容,那么请问。
我该如何以一行命令串取得登录系统的总人次?
由于last 会输出空白行、wtmp、unknown、reboot 等无关账号登录的信息,因此,我利用
grep 取出非空白行,以及去除上述关键字那几行,再计算行数,就能够了解。


wc也可以当作命令?这可不是上洗手间的WC,这是相当有用的计算文件内容的一个工具。
举个例子来说,当你要知道目前你的账号文件中有多少个账号时,就使用这个方法:【cat /etc/passwd|wc -l】因为/etc/passwd里面一行代表一个用户,所以知道行数就晓得有多少的账号在里面了,而如果要计算一个文件里面有多少个字符时,就使用wc-m这个选项。
3.双向重定向:tee
想个简单的东西,我们由知道>会将数据流整个传送给文件或设备,因此我们除非去读取该文件或设备,否则就无法继续利用这个数据流。
万一我想要将这个数据流的处理过程中将某段信息存下来,应该怎么做?
利用tee就可以,我们可以这样简单的看一下:
tee 会同时将数据流分送到文件与屏幕(screen ),而输出到屏幕的,其实就是stdout,那就可以让下个命令继续处理。

- tee [-a] file
选项与参数:
- -a:以累加(append)的方式,将数据加入 file 当中
范例一,让我们将last的输出存一份到last.list 文件中;

范例二则是将 ls的数据存一份到~/homefile,同时屏幕也有输出信息

要注意,tee后接的文件会被覆盖,若加上-a 这个选项则能将信息累加。
tee可以让 standard output转存一份到文件内并将同样的数据继续送到屏幕去处理,这样除了可以让我们同时分析一份数据并记录下来之外,还可以作为处理一份数据的中间缓存记录之用,tee这家伙在很多选择/填空的认证考试中很容易考。