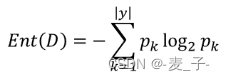决策树是一种常用的监督学习算法,既可以用于分类任务也可以用于回归任务。决策树通过递归地将数据集划分成更小的子集,逐步建立树结构。每个节点对应一个特征,树的叶子节点表示最终的预测结果。构建决策树的关键是选择最佳的特征来分割数据,而信息增益(Information Gain)和熵(Entropy)是常用的度量标准。
熵(Entropy)
原理
熵是衡量随机变量不确定性的指标。在决策树中,熵用于衡量数据集的纯度或混乱程度。熵越高,数据集越混乱;熵越低,数据集越纯净。
公式
对于一个包含 ( n ) 个类别的分类问题,数据集 ( S ) 的熵定义为:
Entropy ( S ) = − ∑ i = 1 n p i log 2 ( p i ) \text{Entropy}(S) = -\sum_{i=1}^{n} p_i \log_2(p_i) Entropy(S)=−i=1∑npilog2(pi)
其中,( p_i ) 是数据集中第 ( i ) 类的比例。
示例
假设数据集 ( S ) 有两类(正例和反例),其中正例占比 ( p ),反例占比 ( 1-p ),则熵为:
Entropy ( S ) = − p log 2 ( p ) − ( 1 − p ) log 2 ( 1 − p ) \text{Entropy}(S) = -p \log_2(p) - (1-p) \log_2(1-p) Entropy(S)=−plog2(p)−(1−p)log2(1−p)
信息增益(Information Gain)
原理
信息增益用于衡量选择某个特征进行划分后,数据集的纯度增加了多少。信息增益越大,说明通过该特征进行划分,能够更好地区分数据。因此,决策树在选择特征进行划分时,会选择信息增益最大的特征。
公式
特征 ( A ) 对数据集 ( S ) 的信息增益定义为:
Gain ( S , A ) = Entropy ( S ) − ∑ v ∈ Values ( A ) ∣ S v ∣ ∣ S ∣ Entropy ( S v ) \text{Gain}(S, A) = \text{Entropy}(S) - \sum_{v \in \text{Values}(A)} \frac{|S_v|}{|S|} \text{Entropy}(S_v) Gain(S,A)=Entropy(S)−v∈Values(A)∑∣S∣∣Sv∣Entropy(Sv)
其中,Values(A) 表示特征 ( A ) 的所有可能取值,( S_v ) 表示在特征 ( A ) 上取值为 ( v ) 的子集。
示例
假设我们有一个数据集 ( S ),特征 ( A ) 有两个可能取值 ( {a_1, a_2} ),则信息增益计算过程如下:
- 计算整个数据集的熵: Entropy ( S ) \text{Entropy}(S) Entropy(S)
- 计算特征 ( A ) 各个取值子集的熵: Entropy ( S a 1 ) \text{Entropy}(S_{a_1}) Entropy(Sa1) 和 Entropy ( S a 2 ) \text{Entropy}(S_{a_2}) Entropy(Sa2)
- 计算信息增益:
Gain ( S , A ) = Entropy ( S ) − ( ∣ S a 1 ∣ ∣ S ∣ Entropy ( S a 1 ) + ∣ S a 2 ∣ ∣ S ∣ Entropy ( S a 2 ) ) \text{Gain}(S, A) = \text{Entropy}(S) - \left( \frac{|S_{a_1}|}{|S|} \text{Entropy}(S_{a_1}) + \frac{|S_{a_2}|}{|S|} \text{Entropy}(S_{a_2}) \right) Gain(S,A)=Entropy(S)−(∣S∣∣Sa1∣Entropy(Sa1)+∣S∣∣Sa2∣Entropy(Sa2))
基尼指数(Gini Index)
除了熵和信息增益,基尼指数也是常用的决策树分裂准则。基尼指数衡量数据集的不纯度,值越小越纯。
公式
对于一个包含 ( n ) 个类别的数据集 ( S ),基尼指数定义为:
Gini ( S ) = 1 − ∑ i = 1 n p i 2 \text{Gini}(S) = 1 - \sum_{i=1}^{n} p_i^2 Gini(S)=1−i=1∑npi2
其中,( p_i ) 是数据集中第 ( i ) 类的比例。
示例
假设数据集 ( S ) 有两类(正例和反例),其中正例占比 ( p ),反例占比 ( 1-p ),则基尼指数为:
Gini ( S ) = 1 − ( p 2 + ( 1 − p ) 2 ) = 2 p ( 1 − p ) \text{Gini}(S) = 1 - (p^2 + (1-p)^2) = 2p(1-p) Gini(S)=1−(p2+(1−p)2)=2p(1−p)
信息增益率(Information Gain Ratio)
信息增益率是信息增益的一种改进形式,旨在处理信息增益对取值较多的特征的偏好问题。
公式
特征 ( A ) 对数据集 ( S ) 的信息增益率定义为:
GainRatio ( S , A ) = Gain ( S , A ) SplitInformation ( A ) \text{GainRatio}(S, A) = \frac{\text{Gain}(S, A)}{\text{SplitInformation}(A)} GainRatio(S,A)=SplitInformation(A)Gain(S,A)
其中,分裂信息(Split Information)定义为:
SplitInformation ( A ) = − ∑ v ∈ Values ( A ) ∣ S v ∣ ∣ S ∣ log 2 ( ∣ S v ∣ ∣ S ∣ ) \text{SplitInformation}(A) = -\sum_{v \in \text{Values}(A)} \frac{|S_v|}{|S|} \log_2 \left( \frac{|S_v|}{|S|} \right) SplitInformation(A)=−v∈Values(A)∑∣S∣∣Sv∣log2(∣S∣∣Sv∣)
用法
- 分类:用于分类任务,目标变量是类别。
- 回归:用于回归任务,目标变量是连续值。
优点
- 易于理解和解释。
- 处理类别特征和数值特征。
- 不需要大量数据预处理。
缺点
- 容易过拟合,尤其在树深度较大时。
- 对噪声数据敏感。
代码实例
以下是使用 scikit-learn 实现决策树分类和回归的代码示例。
from sklearn.datasets import load_iris, load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.metrics import accuracy_score, mean_squared_error
# 分类任务
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f"Classification Accuracy: {accuracy_score(y_test, y_pred)}")
# 回归任务
boston = load_boston()
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
reg = DecisionTreeRegressor()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
print(f"Regression MSE: {mean_squared_error(y_test, y_pred)}")
随机森林
随机森林是集成学习方法的一种,通过生成多个决策树,并结合它们的预测结果来提高模型的性能和稳定性。
用法
- 分类:用于分类任务,通过多个决策树的投票来确定类别。
- 回归:用于回归任务,通过多个决策树的平均值来预测连续值。
优点
- 减少过拟合的风险。
- 更高的预测准确性。
- 能处理高维数据和缺失值。
缺点
- 计算开销较大,尤其是树的数量较多时。
- 模型复杂性较高,不易解释。
代码实例
以下是使用 scikit-learn 实现随机森林分类和回归的代码示例。
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# 分类任务
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f"Random Forest Classification Accuracy: {accuracy_score(y_test, y_pred)}")
# 回归任务
reg = RandomForestRegressor(n_estimators=100, random_state=42)
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
print(f"Random Forest Regression MSE: {mean_squared_error(y_test, y_pred)}")
进阶用法和参数调整
决策树参数
criterion: 分裂的评价标准(gini或entropy用于分类;mse或mae用于回归)。max_depth: 树的最大深度,防止过拟合。min_samples_split: 分裂内部节点所需的最小样本数。min_samples_leaf: 叶节点的最小样本数。
随机森林参数
n_estimators: 决策树的数量。max_features: 每次分裂时考虑的特征数量。bootstrap: 是否在构建树时使用自助法采样。oob_score: 是否使用袋外样本评估模型性能。
# 调整决策树参数
clf = DecisionTreeClassifier(max_depth=5, min_samples_split=10, criterion='entropy')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f"Tuned Decision Tree Classification Accuracy: {accuracy_score(y_test, y_pred)}")
# 调整随机森林参数
reg = RandomForestRegressor(n_estimators=200, max_features='sqrt', oob_score=True, random_state=42)
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
print(f"Tuned Random Forest Regression MSE: {mean_squared_error(y_test, y_pred)}")
print(f"Out-of-Bag Score: {reg.oob_score_}")
可视化决策树
可以使用 graphviz 库可视化决策树,以便更好地理解其结构。
from sklearn.tree import export_graphviz
import graphviz
# 导出决策树图像
dot_data = export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("decision_tree")
通过这些实例,展示了决策树和随机森林在分类和回归任务中的应用。可以根据具体问题调整参数,提升模型的性能和稳定性。