0.前言
本系列以同济大学的检索增强生成(RAG)综述[1],ACL2023 检索增强语言模型(RALM) Tutorial[2]作为参考材料,讲解RAG的前世今身,包含概述,评估方法,检索器,生成器,增强方法,多模态RAG等内容。
本篇为评估篇,介绍RAG的评估目标以及常见的基准和工具。
1.评估目标
1.1 质量
一般从检索质量和生成质量两方面进行评估。
1.1.1 检索质量
首先需要评估数据,可以采用现有信息检索数据集或用LLM构造自己领域的专属数据集,对每个查询-文档对都需要标注是否相关,或者相关程度。
一般采用搜索引擎,推荐系统和信息检索系统中的指标来衡量RAG检索效果。比如Hit Rate(类似Recall@K),MRR,NDCG[3]。
1.1.2 生成质量
生成质量评估可以根据生成内容的目标来分类,即无标签的和有标签。对于无标签内容,主要从生成答案的诚实性,相关性和无害性来评估。对于有标签内容,可以从生成内容的准确性来评估。检索和生成质量都可以用人工或自动评估方法[4,5]。
1.2 需求
1.2.1 质量需求
包含上下文相关性,答案诚实性和答案相关性[6,7,8]。
- 上下文相关性:检索到的文档的准确性和特异性,确保相关性,尽量降低无关内容的处理成本。(检索)
- 答案诚实性:生成的答案相对于检索到的上下文保持真实和一致。(生成)
- 答案相关性:生成的答案和用户提出问题相关,有效地解决核心问题。(生成)
1.2.2 能力需求
包含四个方面的能力用来评估RAG的适应性和效率[9,10]:
- 噪声鲁棒性:模型管理和问题相关但缺乏足够信息的文档的能力。(检索)
- 负排斥:当检索到的文档不包含回答问题所必需的知识时,模型是否能够拒绝回答。(生成)
- 信息集成:从多个文档中综合信息来解决复杂问题能力。(生成)
- 反事实鲁棒性:测试模型识别和忽略文档中不准确信息的能力,即使已经被要求使用错误信息。(检索)
1.3 评价指标
[1]中的下图展示了各个需求对应的指标:
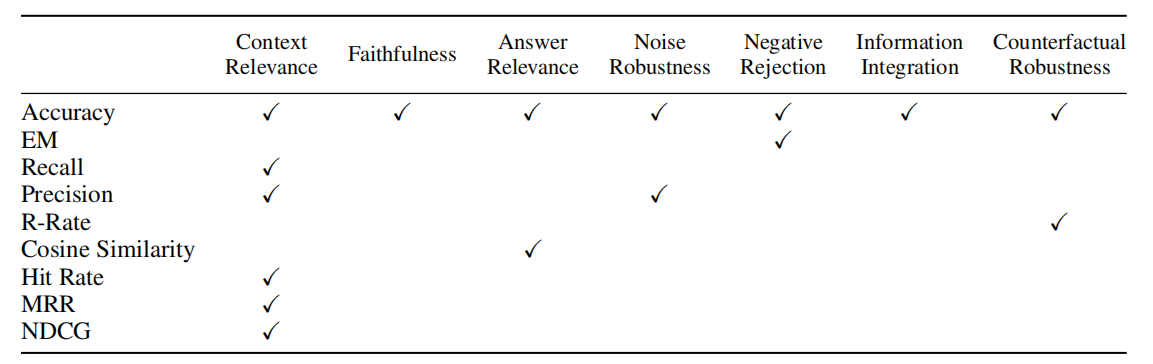
接下来介绍常见指标的定义。首先是机器学习常见指标:
- Accuracy:正确识别正负样本的比例(即考虑每个样本的预测是否正确)。 a c c u r a c y = T P + T N P + N accuracy=\frac {TP+TN} {P+N} accuracy=P+NTP+TN
- Recall:正确识别正样本的比例。(即所有的正样本被召回的比例)。 r e c a l l = T P T P + F N recall=\frac {TP} {TP+FN} recall=TP+FNTP
- Precision:预测为正样本的样本中确实为正样本的比例(只考虑预测为正样本的这一部分)。 p r e c i s i o n = T P T P + F P precision=\frac {TP} {TP+FP} precision=TP+FPTP
- F分数: F β = ( 1 + β 2 ) × p r e c i s i o n × r e c a l l β 2 × p r e c i s i o n + r e c a l l F_\beta=\frac {(1+\beta^2)\times precision\times recall} {\beta^2\times precision + recall} Fβ=β2×precision+recall(1+β2)×precision×recall
之后是一些常见的推荐/检索指标:
EM(Exact Match):常用于问答系统,预测中和正确答案(ground truth answers)完全匹配的百分比
MRR(mean reciprocal rank):评估排序性能,每个rank表示这个query对应的target文档在候选文档中的排序。 M R R = 1 Q ∑ i = 1 Q 1 r a n k i MRR=\frac 1 Q \sum_{i=1}^Q\frac 1 {rank_i} MRR=Q1∑i=1Qranki1
Cosine Similarity:两个文档的表征的余弦相似度
MAP:AP的平均值。AP可以被简单定义为:如果某个查询有K个相关文档,返回结果中这K个文档的排序为 r a n k i rank_i ranki (从小到大),则 A P = ∑ i = 1 K i r a n k i AP=\sum_{i=1}^K\frac i {rank_i} AP=∑i=1Krankii,MAP是多个查询的AP的平均值。
NDCG:
- N D C G = D C G / I D C G NDCG=DCG/IDCG NDCG=DCG/IDCG
- D C G = ∑ i = 1 k r e l ( i ) l o g 2 ( i + 1 ) DCG=\sum_{i=1}^k\frac {rel(i)} {log_2 (i+1)} DCG=∑i=1klog2(i+1)rel(i) r e l ( i ) rel(i) rel(i)代表返回列表中第i个文档与查询的相关程度
- I D C G IDCG IDCG 代表最理想的返回列表的 D C G DCG DCG 结果,即按照 r e l ( i ) rel(i) rel(i) 从高到低排序。
Hit Rate(Recall@K):对每个查询返回的前K个文档中含有正确文档的比例
2.评估基准与工具
2.1 基准
主流的基准有RGB[9]和RECALL[10],侧重评估RAG的基础能力。
RGB
- 开源地址:https://github.com/chen700564/RGB
- 问答对形式,1000个问题,600个基础问题,200个专门面向信息集成的问题,200个专门面向反事实鲁棒性的问题。一半中文一半英文。
- 从互联网和新闻中搜寻文档,利用编码模型m3e(中文)和mpnet(英文)进行重排。
- 评估模型:ChatGPT,ChatGLM,Vicuna-7B,Qwen-7B,BELLE-7B-2M
- 结论:对于噪声鲁棒性,随着噪声文档的增加(即不相关文档数量增加),RAG的性能逐渐下降;负排斥,信息集成,反事实鲁棒性对于RAG都很困难,提升空间都很大。
- 关注RAG的整体
RECALL
- 问答对形式,每个问题的提示都含有一段包含错误内容的文本,有的文本修改答案文本,有的文本修改非答案文本。模型被提供正确和错误答案两个选项。
- 评估模型:ChatGLM2,Llama2,Vicuna,Baichuan2
- 结论:模型很容易被错误的上下文误导,且内在知识和上下文矛盾时很容易产生质量较低的回复。通过提示词优化与推理干预方法没法很好的解决,需要设计更好的方法。
- 只关注生成。
2.2 工具
最先进的自动化工具有RAGAS[6],ARES[7]和Trulens[11],使用LLM来自动评估。这部分工作主要以和人类的标注对齐为主要贡献,没有给出不同方法的对比。
RAGAS
- 开源地址:https://github.com/explodinggradients/ragas
- 创建了WikiEval数据集:https://huggingface.co/datasets/explodinggradients/WikiEval。根据50个wiki页面提示ChatGPT得到问题和答案。
- 提示ChatGPT的方式评估,实验表明人类标注和RAGAS提出的标注方式的结果基本一致。
- 评估目标包含上下文相关性,答案诚实性,答案相关性。
- 关注RAG整体
ARES
- 开源地址:https://github.com/stanford-futuredata/ARES
- 和RAGAS的评估目标一致。训练一个小型LM来进行评估。
- 包含KILT和SuperGLUE中的6个不同的知识密集型任务。
- 关注RAG整体
Trulens
- 开源地址:https://github.com/truera/trulens
- 和RAGAS的评估目标一致。
- 关注RAG整体
2.3 常见评估方式
语言模型评估
- Perplexity(困惑度)
- 代表方法:ICRALM[13]
- p e r p l e x i t y = ( ∏ i = 1 n 1 p ( w i ∣ w 1 , . . . , w i − 1 ) ) 1 n perplexity=(\prod_{i=1}^n\frac {1} {p(w_i|w_{1},...,w_{i-1})})^{\frac 1 n} perplexity=(∏i=1np(wi∣w1,...,wi−1)1)n1
- 取对数其实就得到了语言模型的交叉熵损失函数: L = − 1 n ∑ i = 1 n log p ( w i ∣ w 1 , . . . , w i − 1 ) \mathcal L=-\frac 1 n\sum_{i=1}^n\log p(w_i|w_{1},...,w_{i-1}) L=−n1∑i=1nlogp(wi∣w1,...,wi−1)
- 一般是使用wikitext[15]训练集作为检索文档集,使用wikitext测试集验证困惑度
- 在GPT2,GPT3,ChatGPT,LLaMA等模型上测试
- BPB(bits per UTF-8 encoded byte)
- 代表方法:REPLUG[12]
- B P B = ( L T / L B ) log 2 ( e L ) = ( L T / L B ) L / ln 2 BPB=(L_T/L_B)\log_2(e^\mathcal L)=(L_T/L_B)\mathcal L/\ln 2 BPB=(LT/LB)log2(eL)=(LT/LB)L/ln2; L T L_T LT代表token长度, L B L_B LB代表字节长度;
- BPB是Pile[14]建议的评估指标,因此一般也在Pile的测试集上测试
- 在GPT2,GPT3,ChatGPT,LLaMA等模型上测试
下游任务评估
- 专业知识问答
- 代表方法:REPLUG[12]
- 用选择题的准确率来评估
- 数据集:MMLU[16]
- 开放领域问答
- 代表方法:REPLUG[12]
- 用问答的准确率来评估
- 数据集:Natural Questions (NQ) [17],TriviaQA[18]
3.结论
[1]中的下图展示了各个基准或工具的相应评估目标,其中Evaluation Targets代表是哪个方面的质量,Evaluation Aspects代表是哪个方面的需求。个人认为,综合易用性和全面性,比较适合用于学术评估的是RGB和RAGAS。TruLens含有对向量数据库的支持,ARES需要对特定领域进行打分器训练后再评估,可以考虑根据不同用途选用这两个工具进行评估。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!
4.引用
[1]Gao Y, Xiong Y, Gao X, et al. Retrieval-augmented generation for large language models: A survey[J]. arXiv preprint arXiv:2312.10997, 2023.
[2]Asai A, Min S, Zhong Z, et al. Retrieval-based language models and applications[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts). 2023: 41-46.
[3]Isabelle Nguyen. Evaluating rag part i: How to evaluate document retrieval. https://www.deepset.ai/blog/rag-evaluation-retrieval, 2023.
[4]Tian Lan, Deng Cai, Yan Wang, Heyan Huang, and Xian-Ling Mao. Copy is all you need. In The Eleventh International Conference on Learning Representations, 2022.
[5]Quinn Leng, Kasey Uhlenhuth, and Alkis Polyzotis. Best practices for llm evaluation of rag applications. https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG, 2023.
[6]Es S, James J, Espinosa-Anke L, et al. Ragas: Automated evaluation of retrieval augmented generation[J]. arXiv preprint arXiv:2309.15217, 2023.
[7]Saad-Falcon J, Khattab O, Potts C, et al. Ares: An automated evaluation framework for retrieval-augmented generation systems[J]. arXiv preprint arXiv:2311.09476, 2023.
[8]Colin Jarvis and John Allard. A survey of techniques for maximizing llm performance. https://community.openai.com/t/openai-dev-day-2023-breakout-sessions/505213#a-survey-of-techniques-for-maximizing-llm-performance-2, 2023.
[9]Chen J, Lin H, Han X, et al. Benchmarking large language models in retrieval-augmented generation[J]. arXiv preprint arXiv:2309.01431, 2023.
[10]Liu Y, Huang L, Li S, et al. RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge[J]. arXiv preprint arXiv:2311.08147, 2023.
[11]https://www.trulens.org/trulens_eval/core_concepts_rag_triad/
[12]Shi W, Min S, Yasunaga M, et al. Replug: Retrieval-augmented black-box language models[J]. arXiv preprint arXiv:2301.12652, 2023.
[13]Ram O, Levine Y, Dalmedigos I, et al. In-context retrieval-augmented language models[J]. arXiv preprint arXiv:2302.00083, 2023.
[14]Gao L, Biderman S, Black S, et al. The pile: An 800gb dataset of diverse text for language modeling[J]. arXiv preprint arXiv:2101.00027, 2020.
[15]Karpukhin V, Oguz B, Min S, et al. Dense Passage Retrieval for Open-Domain Question Answering[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 6769-6781.
[16]Hendrycks D, Burns C, Basart S, et al. Measuring Massive Multitask Language Understanding[C]//International Conference on Learning Representations. 2020.
[17]Kwiatkowski T, Palomaki J, Redfield O, et al. Natural Questions: a Benchmark for Question Answering Research[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 452-466.
[18]Joshi M, Choi E, Weld D S, et al. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017: 1601-1611.

![[<span style='color:red;'>论文</span>阅读] |<span style='color:red;'>RAG</span><span style='color:red;'>评估</span>_Retrieval-Augmented Generation Benchmark](https://img-blog.csdnimg.cn/direct/77abf882e4ca477fa70852e5cd7bcc7a.png)