跳表(SkipList)学习
1. 什么是跳表?
基于“空间换时间”思想,通过给链表建立索引,使得链表能够实现二分查找。
跳表是可以实现二分查找的有序链表。
2. 从单链表到跳表
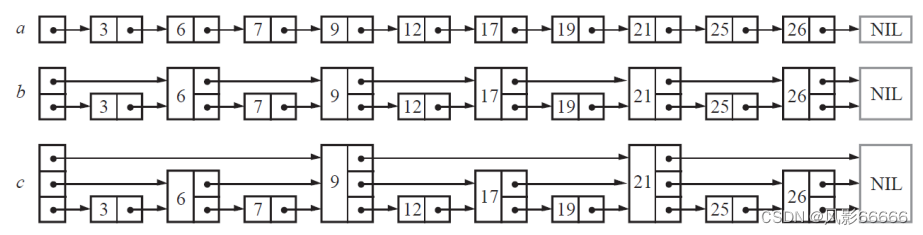
对于一般的单链表,在其中进行查询是比较复杂的,时间复杂度为O(n)。
因此,可以通过加入新的索引,来加快查询,如加入第一层索引:

此时,我们可以先在第一层索引中进行查找,确定范围后再转到原始链表中(索引是指向原始链表的)查询,可以有效减少查询的时间。基于此,可以不断地加入索引(加入索引会导致内存占用增加,所以即==“空间换时间”==):

如上图所示,带有索引的单链表 —— 跳表,可以实现二分查找。
3. 跳表的查找
3.1 时间复杂度 —— O(logn) (原始单链表时间复杂度为O(n))
查找元素的过程是从最高级索引开始,一层一层遍历最后下沉到原始链表。因此,可以定义:
时间复杂度 = 索引的高度 * 每层索引要遍历的次数
假设当前跳表存在n个节点且每两个结点会抽出一个结点作为上一级索引的结点,首先来计算**索引的高度**:
假设原始链表为第0层,那第i层的索引所包含的节点数为: n / 2^i
因此,当无法再向上层提供索引时,当前的索引k满足:2 = n / 2^k
所以最高级索引k可以计算得:k = log2(n) - 1
由于存在第0层,所以最终 索引的高度 = k + 1 = log2(n)
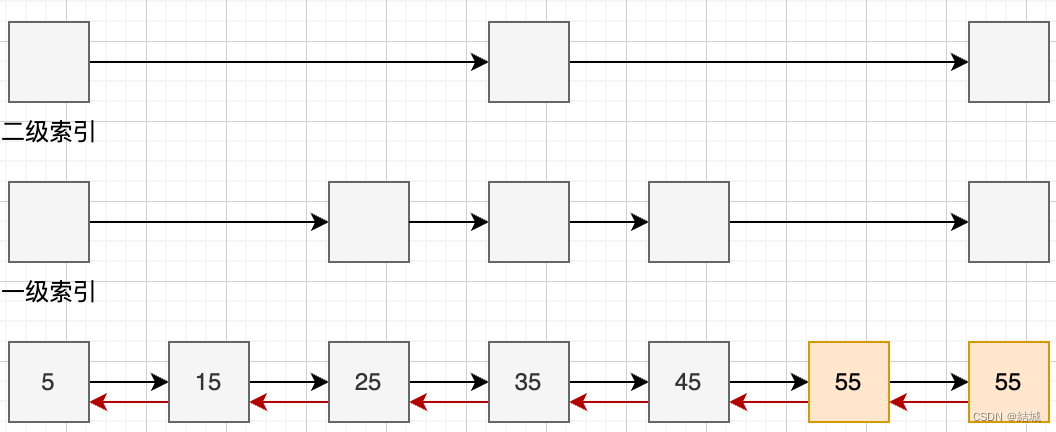
另外,如图所示,由于每两个结点抽出一个上级索引节点,所以在一层索引中至多遍历3个节点
于是:时间复杂度 = log2(n) * 3 = O(logn)
3.2 空间复杂度 —— O(n)
同样以n个节点且每两个结点会抽出一个结点作为上一级索引的结点为例,一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,新增的空间复杂度是 O(n)。
显然,每x个结点抽取一个结点会显著影响到时间和空间复杂度:**x越小,跳表的查询速度越快,额外占用的内存越大。**在实际中需要综合考虑实际需求。
同时,由于我们在索引中不需要保存全部内容,只需要保存键值key和几个指针,而不是完整的对象,所以当单个结点对象很大时,索引所带来的空间占用甚至可以忽略不计。
4. 跳表的插入
跳表的原始链表需要保持有序,所以我们像查找元素一样,找到元素应该插入的位置。
重点是在插入数据的时候,索引节点也需要相应的增加、或者重建索引。避免一直往原始列表中添加数据,但是不更新索引,就可能出现两个索引节点之间数据非常多的情况,极端情况甚至退化为单链表。但是如果是重建索引,会**导致每插入一个元素都需要重建索引,造成插入的时间复杂度为O(n)**。
4.1 跳表中维护索引的方法 —— 索引随机分布
前面我们提到一种建立索引的方式是每x个结点会抽出一个结点作为上一级索引的结点,但这样会导致索引的维护更加困难。因此,在跳表中使用的是**索引随机分布**这种方式来建立索引。

如上图所示,跳表的索引不是严格的按照每几个取一个索引,而是随机选择n / 2个作为一级索引、n / 4个作为二级索引…
于是再插入的时候只需要考虑这个元素需要插入到几级索引中,然后再维护索引并把这个元素插入原链表中。而确定这个元素需要插入到几级索引是通过概率算法:有 1/2 的几率建立一级索引、1/4 的几率建立二级索引、1/8 的几率建立三级索引,以此类推…(是有可能不插入索引的)
在确定了要插入的索引等级进行插入时,插入的时间复杂度和查找一致,都是O(logn)。
5. 跳表的删除
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素 x,则执行删除操作。如果链表的高度为logn,那时间复杂度最多logn + logn,即O(logn)。
6. 总结
- 跳表是可以实现二分查找的有序链表;
- 每个元素插入时随机生成它的level;
- 最底层包含所有的元素;(原始链表)
- 如果一个元素出现在level(x),那么它肯定出现在x以下的level中;
- 每个索引节点包含两个指针,一个向下,一个向右;(Redis实际实现没有向下的,只维护了向右的,为什么?)
- 跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近;
7. 一些问题
为什么Redis选择使用跳表而不是红黑树(或其他平衡树)来实现有序集合?
Redis 中的有序集合(zset) 支持的操作:
- 插入一个元素
- 删除一个元素
- 查找一个元素
- 有序输出所有元素
- 按照范围区间查找元素(比如查找值在 [100, 356] 之间的数据)
其中,前四个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。而红黑树只能定位到端点后,再从首位置开始每次都要查找后继节点,相对来说是比较耗时的。
此外,跳表实现起来很容易且易读,红黑树实现起来相对困难,所以Redis选择使用跳表来实现有序集合。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
总结:
- 从内存占用上来比较,跳表比平衡树更灵活一些。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis 里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对原始链表进行遍历就可以。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
Redis中的zset实现没有向下的指针,那怎么从二级索引跳到一级索引呢? 为什么?
查找过程从最高层开始,逐层向下进行。zset虽然没有显式的向下指针,但通过逐层的前向指针可以实现向下移动的效果。以下是查找过程的示例伪代码:
zskiplistNode *zslSearch(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x = zsl->header;
for (int i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward != NULL &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele, ele) < 0))) {
x = x->level[i].forward; // 到了下一层,还是从这个节点开始,和使用向下的指针结果一致
}
}
x = x->level[0].forward;
if (x != NULL && score == x->score && sdscmp(x->ele, ele) == 0) {
return x;
}
return NULL;
}
在这个示例中:
- 从最高层(
zsl->level - 1)开始查找。 - 在当前层中,利用
forward指针向右移动,直到找到大于或等于目标分数和元素的位置。 - 如果在当前层无法找到,则移动到下一层(
i--),继续查找。 - 重复上述过程,直到到达最底层(
level[0])。 - 在最底层进行最终查找,找到目标节点。
虽然 Redis 跳表的节点没有显式的向下指针,但它通过以下方式实现多层级搜索:
- 多层级结构:节点在不同层级上都有前向指针,允许在每层进行搜索。(是维护一个节点指针数组,表示这个节点在各个层上的指向节点,而不是保存每个层的链表)
- 逐层向下:查找过程从最高层开始,逐层向下进行,虽然没有显式的向下指针,但通过控制层级(
i--)实现向下移动的效果。(因为移动了层级,但还是会在同一个节点上,本质上没区别) - 前向指针:每个层级都有前向指针,通过这些指针在同一层中进行快速搜索。
Redis 的跳表实现选择使用多级向右指针而不是显式的向下指针,主要是为了简化实现、节省空间、提高性能,并减少指针操作的复杂性。这种设计使得跳表在实际应用中表现优异,成为一种高效的数据结构。
参考文献
图片来源:一文彻底搞懂跳表的各种时间复杂度、适用场景以及实现原理_跳表时间复杂度-CSDN博客