我们知道跳表是一种简单,高效的数据结构,在很多知名的开源存储产品中有着广泛的应用,比较广为人知的就是Redis中的有序集合,此外在Kafka、LevelDB等需要高性能索引的数据库相关产品中,也有skiplist的身影。
多年前,第一次接触到跳表的时候,就有一种震撼的感觉。数组的特点是可以索引,但是动态扩容要重新分配空间;而链表可以动态分配空间,却没有索引能力,只能遍历比较查询元素。
跳表的出现,通过空间换时间的方式,利用有层级结构的链表,打破了在开始学习数据结构的时候,就建立的链表只能遍历查询的固有认知,通过前向指针,可以在有序的链表中,快速检索节点,在大多数情况下,达到接近,甚至超越平衡术的检索性能。

本系列文章,旨在通过阅读一系列论文,了解包括跳表这种数据结构在内的各种数据结构,是如何发现和进化,并且在现在的互联网主流基础设置中应用。
第一篇论文是William Pugh关于跳表数据结构的开创性论文,"Skip Lists: A Probabilistic Alternative to Balanced Trees",论文中介绍了跳表的设计和基本操作。
论文解读:
作者首先解释二叉搜索树和平衡树等数据结构的局限性,并提出跳表作为一个可行的替代方案,具有实现简单的特点,在特定的应用场景,是比树更自然的索引实现方式。
跳表可以达到与平衡树相当的平均搜索、插入和删除操作性能,并通过随机化层级来优化整体结构,随机化是跳表结构保持平衡的重要机制。
论文比较了传统二叉搜索树可能需要进行大量比较才能找到特定元素(例如,在含100个元素的完全平衡二叉搜索树中最多需要7次比较),而使用跳表则可以显著减少这一过程(同样大小数据集合下只需约3次)。
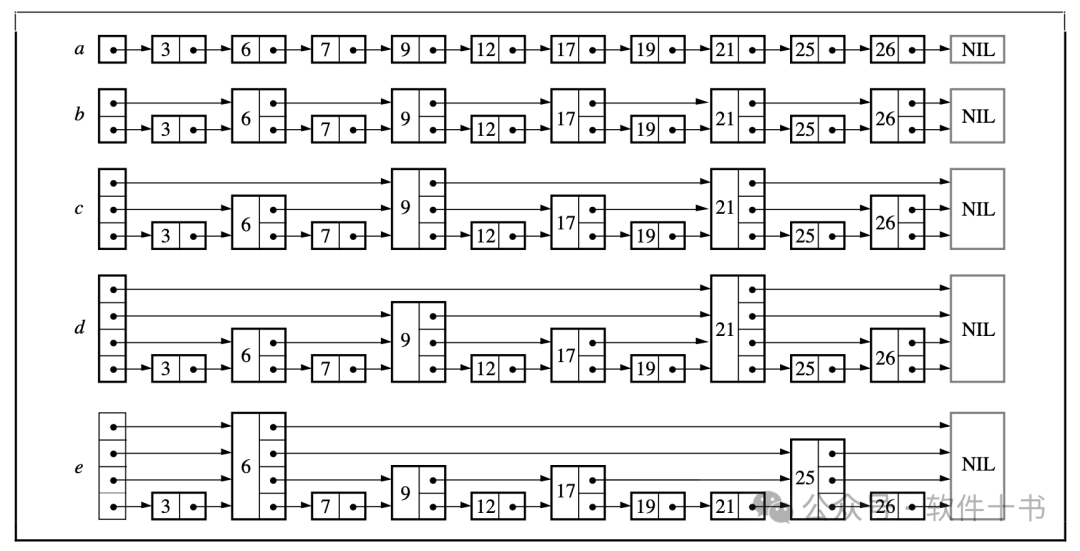
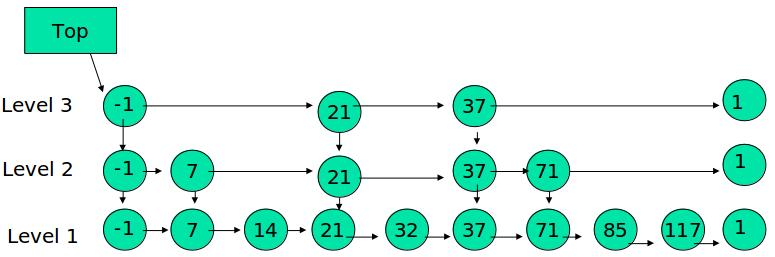
什么是跳表(Skip Lists):
跳表(Skip Lists)是一种有多层额外指针的链表,通过前进指针(Forward Points),可以在在查询特定元素的过程中,跳过中间节点,从而不需要从头开始,在链表中逐一检查元素。类似于在分页查询时先快速翻阅索引页来缩小范围。
从顺序排列的链表开始,我们可以逐层构建前进指针,每隔一个节点,设置一个前进指针,这样每层的节点数量,不会超过[n/2^i + i]个,层级越高,节点越少,最多增加一倍的指针数量,就可以构建一个支持快速搜索的多层检索链表。
当然只是检索是不够的,跳表还需要能够高效的处理插入和删除,如果每次插入删除都要重新平衡整个结构,代价会非常大。
如果在插入删除的过程中,随机选择新插入节点层级,就可以只在局部修改前进节点和指针,一旦插入,层级就不再需要改变。
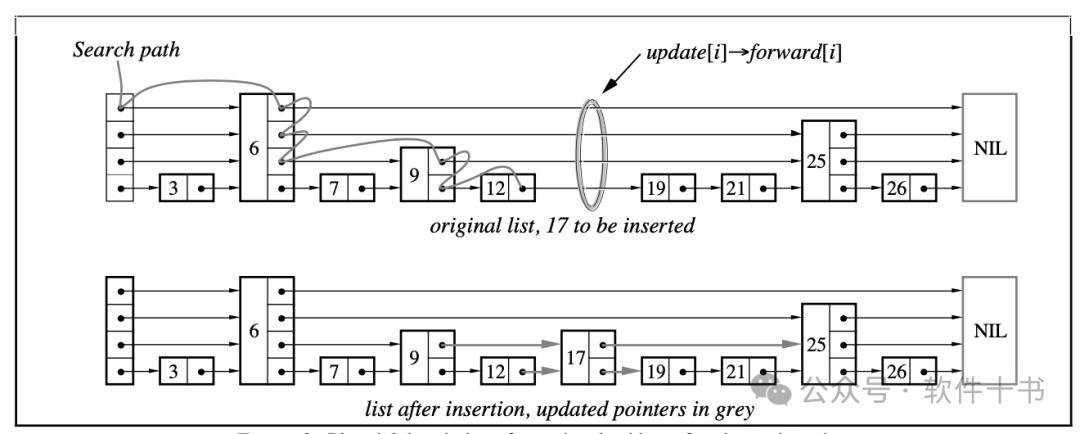
跳表的算法
Search(list, searchKey)x := list→header-- loop invariant: x→key < searchKeyfor i := list→level downto 1 dowhile x→forward[i]→key < searchKey dox := x→forward[i]-- x→key < searchKey ≤ x→forward[1]→keyx := x→forward[1]if x→key = searchKey then return x→valueelse return failure
跳表的检索很简单,先从多层链表的最顶层开始检索,直到没有比要查找的值更大的值的位置,就将遍历指针移动到当前位置,然后从刚才的位置开始,在下一层中继续查找。
直到遍历完最底层,从最底层的前进节点中,取出对应的节点值,比较是否跟要查找的值匹配,匹配就说明找到元素,如果不匹配,说明要找的节点不存在。
跳表的查询方式类似二分查找,通过类似分层索引的方式,可以达到O(log n)的平均查询时间复杂度。实际应用中,跳表的查询效率通常高于 O(log n),因为跳表的跳跃指针可以跳过大量节点,从而减少比较次数。
randomLevel()lvl := 1-- random() that returns a random value in [0...1)while random() < p and lvl < MaxLevel dolvl := lvl + 1return lvl
插入新节点的时候,算法中最核心的是随机选择当前节点的层级,首先需要根据跳表大小和性能需求,确定一个最大层数的常量。
然后随机生成0到1之间的随机数,随机数小于某个预设值p的时候,就把节点的层数加1,直到层数到最高或者随机数小于预设值。
假设 MaxLevel = 4,p = 1/2。生成随机数序列 0.3, 0.6, 0.2,则新节点的层数选择过程如下:
第 1 次:0.3 < 1/2,层数增加 1,当前层数为 2。
第 2 次:0.6 >= 1/2,层数不变,当前层数为 2。
第 3 次:0.2 < 1/2,层数增加 1,当前层数为 3。
最终,新节点的层数为 3。
p的选择对于性能的影响是非常重要的,p 越小,节点拥有更高层级的概率越小,跳表的空间利用率越高,但搜索效率可能略有下降。论文中的预设值是1/2,相对来说可以获得较好的性能和空间利用率。
Insert(list, searchKey, newValue)local update[1..MaxLevel]x := list→headerfor i := list→level downto 1 dowhile x→forward[i]→key < searchKey dox := x→forward[i]-- x→key < searchKey ≤ x→forward[i]→keyupdate[i] := xx := x→forward[1]if x→key = searchKey then x→value := newValueelselvl := randomLevel()if lvl > list→level thenfor i := list→level + 1 to lvl doupdate[i] := list→headerlist→level := lvlx := makeNode(lvl, searchKey, value)for i := 1 to level dox→forward[i] := update[i]→forward[i]update[i]→forward[i] := x
插入和删除操作的更多代码,可以直接参看论文原文,无论插入还是删除,核心逻辑都是要先在跳表中检索,并且在从最高层级向下检索的过程中,维护一个更新数组,更新数组中对应第i层的update[i],指向目标键值左侧的最后一个节点。
找到目标位置的前一个节点之后,就可以开始插入,插入的时候,先要随机获取节点所在的层数。
如果新节点的层数,比当前的最大层级更高,要先更新跳表的最大层级,将跳表的头部节点,指向新节点,因为这个时候,在新的最高层,只有新节点。
最后就可以调整指针,要调整的主要是更新数组,更新数组中相应层级节点的指针,要指向新节点;而新节点,也要指向更新数组中相应层级的节点。
删除的过程,整体跟插入比较接近,主要目的就是要调整指向待删除节点的前序节点的各层级指针,将指针指向待删除节点的指针原来指向的节点。
通过算法介绍,我们看到,随机产生层数的常量p和MaxLevel为对跳表的性能产生重大的影响,所以,论文探讨了如何选择常量的值,还有从哪一层开始搜索的策略。
如果随机产生的层级,导致仅有一个节点在非常高的层级,这时候从最高层开始搜索,就会导致不必要的开销,论文引入了 L(n) 表示在跳表中,期望有多少个节点具有最高层级。公式为 L(n) = log1/p n。
论文介绍了三种方法,应对这种情况:
保持简单:直接从最顶层开始搜索,根据分析,产生非常高层级节点的情况非常少,因此对性能的影响非常有限。可以直接忽略。
使用更少的层级:根据节点数量,只设置最高L(n)的层数,而不是最高层数,有一些方法能实现,但是实现很复杂,所以不推荐
调整骰子:也就是说,不完全依赖随机生成的层数,如果算出的层数比当前最高层数高出很多,那么新节点的层数是当前最高层数加1,虽然从理论上,这种做法会破坏随机性,影响性能的评估,但是在实践中,这种方式看起来是有效的。所以实践中根据情况可以一试。
通过对最高层级问题的讨论,论文提出,将MaxLevel设置成L(n)是一个比较好的选择。
跳表算法分析
从算法的实现中,我们可以看到,影响搜索、插入和删除节点的主要时间开销,都是以检索节点的时间为主。而检索的时间开销,是由我们穿过链表时节点在不同层级的样式或者形态决定的。因此通过随机生成级别,保证了良好的搜索性能。
生成的跳表结构,完全是由节点的数量还有插入是随机数生成器决定的,跟插入的顺序完全没有关系。
通过采用无限列表假设和倒推分析,可以证明了Skip Lists的搜索路径长度是O(log n),搜索性能和平衡二叉树相当。
我们假设从末尾开始,逐层向上、向左,沿着搜索路径倒推,并且假设节点的层数直到回溯经过的时候,观察的瞬间才会确定下来。在推导过程中,假设Skip Lists长度是无限的,分析搜索路径在无限列表中爬升k层的期望成本C(k),然后通过递归,推导出C(k)=k/p。
当我们向上爬升的时候,如果碰到碰到Header,我们不做任何动作,只是简单的继续爬升,因此我们能够得到在有n个元素的列表中,从第一层爬升到第L(n)层的路径的期望长度(L(n)-1)/p,然后采用不同的分析技术,计算剩余向左移动的次数,该次数取决于L(n)或者更高层元素的数量,计算出的期望值是1/p。
另一方面,我们继续从L(n)向上爬升到链表的最高层,跳表中最高层数大于k的概率是1-(1-pk)n,也就是npk,根据这个概率,我们可以计算出最大层数的期望不会超过L(n) + 1/(1-p)。
把所有结果放在一起,计算出在有n个元素的跳表中爬出时,总的期望成本小于等于L(n)/p+1/(1-p),也就是O(log n)。
由于每次搜索路径上的位置都需要进行比较,因此比较次数分析中实际比较次数为路径长度加 1。
算法选择
跳表所解决的搜索性能问题,使用类似AVL的平衡树,或者自调整树,都可以获得同样的性能表现,在什么情况下使用不同的算法,可以综合以下几个因素考虑:实现难度、常数因子、性能边界问题、还有非均衡的查询分布。
相比其他数据结构,跳表通常实现起来都更加简单。
同样的算法,在不同的实际应用中,可能有非常不同的常数因子;跳表算法的常数因子通常较低,执行速度快,尤其是在非递归实现的情况下。
三种对比的算法,有三种不同的性能界限,平衡树有最坏情况时间界限;自调整树有摊销时间界限,虽然有的操作可能只有O(n)的时间复杂度,但是大多数时候都被一系列操作的时间摊销;而跳表有概率事件界限,在某些操作上可能超过预期时间。
相比自调整的树,跳表在更均衡的数据上会有更好的表现,但是在高度倾向的数据分布时,跳表的性能表现不如有自平衡能力的自调整树,在这种情况下,使用自调整树或者用缓存强化跳表是更好的选择。
关于跳表的更多工作
最后论文探讨了跳表在其他领域的应用和扩展。
作者专门用一篇论文,讨论了并发更新跳表的算法,比并发平衡树算法更简单,且锁竞争更少,之后会专门解读这篇论文。
使用跳表可以轻松实现平衡树的各种操作,例如搜索指针、合并跳表和排名操作,在redis实现有序集合的排序能力,就是最经典的应用之一。
总之,跳表(Skip Lists)是一种可以在大多数应用场景中替代平衡树的简单数据结构,跳表算法实现简单、扩展和修改方便;几乎可以达到接近高度优化的平衡树的速度,而且可以稳定的比大多数随意实现的平衡树速度更快。
如果您喜欢这篇文章,欢迎关注我的公众号【软件十书】,获取更多精彩内容,点击阅读原文。


























![[Python自动化办公]--从网页登录网易邮箱进行邮件搜索并下载邮件附件](https://i-blog.csdnimg.cn/direct/0c0aee33193441149f7815f1fad1641d.png)