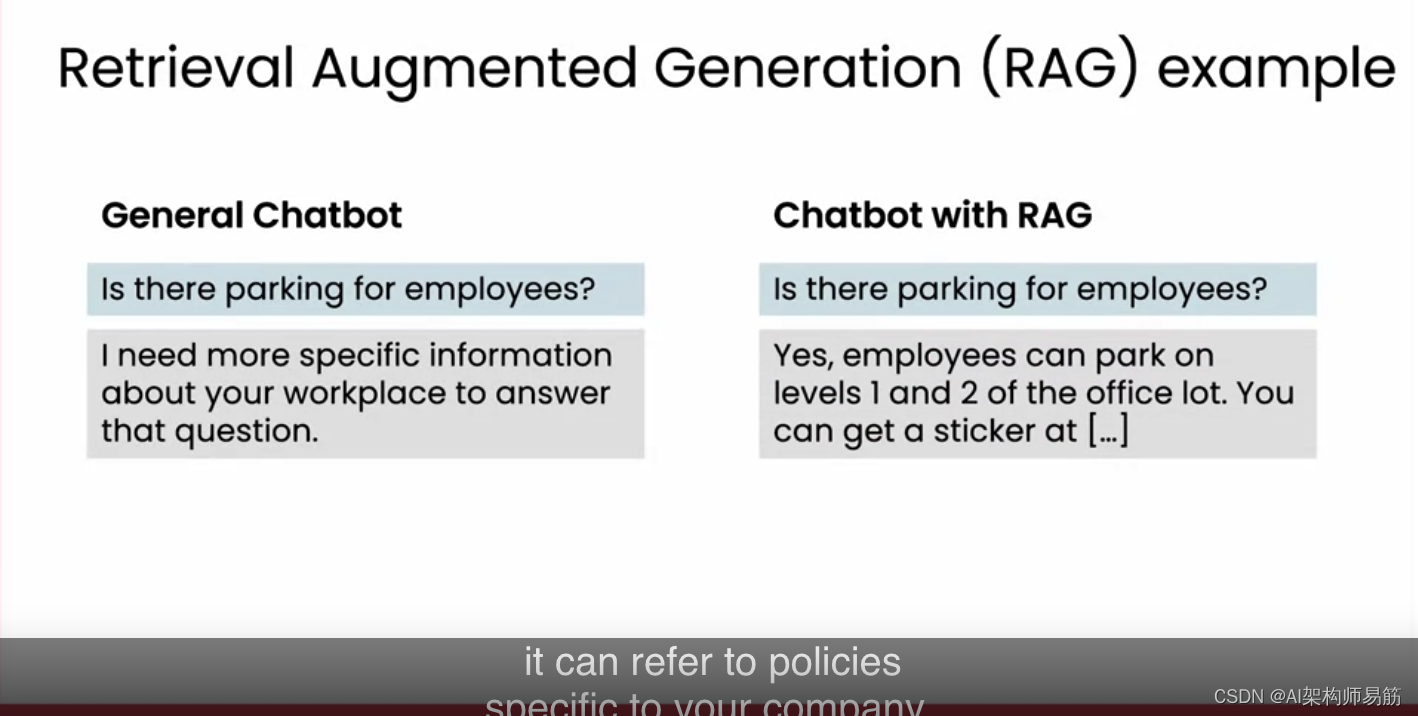
Midjourney 的知识图谱聊天机器人的想法。
大型语言模型 (LLM) 的第一波炒作来自 ChatGPT 和类似的基于网络的聊天机器人,这些模型在理解和生成文本方面非常出色,这让人们(包括我自己)感到震惊。
我们中的许多人登录并测试了它写俳句、动机信或电子邮件回复的能力。很快我们就发现,法学硕士不仅擅长生成创造性背景,还擅长解决典型的自然语言处理和其他任务。
LLM 炒作开始后不久,人们就开始考虑将其集成到他们的应用程序中。不幸的是,如果您只是围绕 LLM API 开发包装器,那么您的应用程序很可能会失败,因为它没有提供额外的价值。
LLM 的一个主要问题是所谓的知识截止。知识截止术语表示 LLM不知道他们接受培训后发生的任何事件。例如,如果你向 ChatGPT 询问 2023 年发生的某件事,你会得到以下回应。
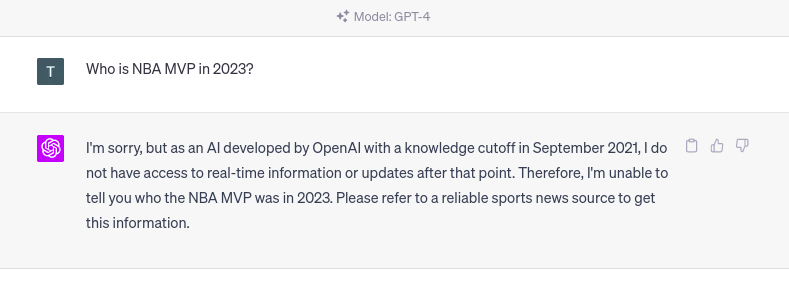
ChatGPT 的知识截止日期。图片由作者提供。
如果您向法学硕士询问其训练数据集中不存在的任何事件,也会出现同样的问题。虽然知识截止日期与任何公开可用的信息相关,但法学硕士并不了解在知识截止日期之前可能存在的私人或机密信息。
例如,大多数公司都有一些他们不会公开分享的机密信息,但可能对拥有能够回答这些问题的定制法学硕士感兴趣。另一方面,法学硕士知道的许多公开信息可能已经过时了。
因此,更新和扩展法学硕士学位的知识在今天非常重要。
LLM 的另一个问题是,它们被训练来生成听起来很逼真的文本,但这些文本可能并不准确。有些无效信息比其他信息更难发现。尤其是对于缺失数据,LLM 很可能会编造一个听起来令人信服但实际上错误的答案,而不是承认它在训练中缺乏基本事实。
例如,研究或法庭引证可能更容易验证。几周前,一名律师因盲目相信 ChatGPT 提供的法庭引证而陷入麻烦。
我还注意到,LLM 会持续提供有关任何类型的 ID(例如 WikiData 或其他识别号码)的自信但虚假的信息。
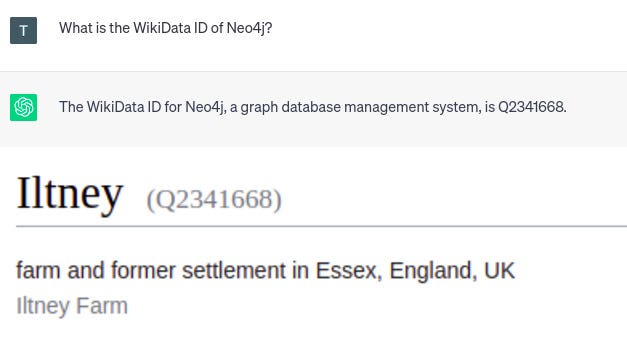
ChatGPT 的幻觉。图片由作者提供。
由于 ChatGPT 的响应是肯定的,您可能希望它是准确的。但是,给定的 WikiData id 指向英格兰的一个农场。因此,您必须非常小心,不要盲目相信 LLM 产生的一切。验证答案或从 LLM 产生更准确的结果是另一个需要解决的大问题。
当然,LLM 还存在其他问题,例如偏见、即时注入等。不过,我们不会在这里讨论这些问题。相反,在这篇博文中,我们将介绍并重点介绍微调和检索增强型 LLM 的概念,并评估它们的优缺点。
法学硕士 (LLM) 的监督微调
解释 LLM 的培训方式超出了本博文的范围。相反,您可以观看Andrej Karpathy 的这段精彩视频,了解 LLM 的最新情况并了解 LLM 培训的不同阶段。
通过微调 LLM,我们参考监督训练阶段,在此期间您提供额外的问答对以优化大型语言模型 (LLM) 的性能。
此外,我们还确定了两种用于微调 LLM 的不同用例。
一个用例是微调模型以更新和扩展其内部知识。
相反,另一个用例则专注于针对特定任务(如文本摘要或将自然语言转换为数据库查询)微调模型。
首先,我们将讨论第一个用例,我们使用微调技术来更新和扩展 LLM 的内部知识。
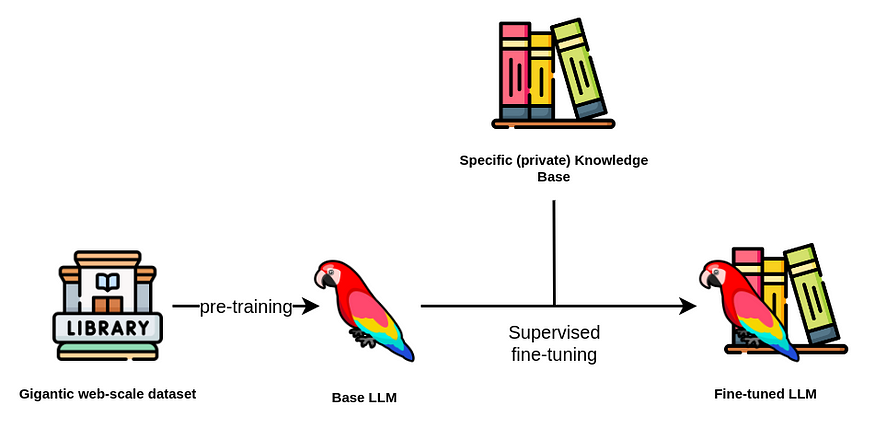
监督微调流程。图片由作者提供。图标来自Flaticons。
通常,你会想要避免对 LLM 进行预训练,因为成本可能高达数十万甚至数百万美元。基础 LLM 是使用庞大的文本语料库进行预训练的,通常有数十亿甚至数万亿个标记。
虽然LLM 的参数数量至关重要,但它并不是选择基础 LLM 时应该考虑的唯一参数。除了许可证之外,您还应该考虑预训练数据集和基础 LLM 的偏差和毒性。
选择基础 LLM 后,您可以开始下一步微调。由于有 LoRa和QLoRA等可用技术,微调步骤的计算成本相对较低。
但是,构建训练数据集更加复杂,而且成本高昂。如果你负担不起专门的注释团队,那么似乎趋势是使用LLM 构建训练数据集来微调你想要的 LLM(这真的很复杂)。
例如,斯坦福的羊驼训练数据集是使用 OpenAI 的 LLM 创建的,生成 5.2 万条训练指令的成本约为 500 美元,相对便宜。
另一方面,Vicuna 模型通过使用用户在 ShareGPT.com 上发布的 ChatGPT 对话进行了微调。
H2O还有一个相对较新的项目,名为 WizardLM,旨在将文档转换为可用于微调 LLM 的问答对。
我们还没有发现任何最近的文章描述如何使用知识图来准备可以用于微调 LLM 的良好问答对。
这是我们计划在 NaLLM 项目中探索的一个领域。我们有一些利用 LLM 从知识图谱上下文构建问答对的想法。
然而,目前仍有许多未知数。
例如,你能否对同一个问题提供两个不同的答案,然后 LLM 以某种方式将它们合并到其内部知识库中?
另一个考虑因素是,如果不考虑其关系,知识图谱中的某些信息就不相关。因此,我们是否必须预先定义相关查询,或者是否有更通用的方法来实现它?或者我们可以使用表示主语-谓语-宾语表达式的节点-关系-节点模式来生成相关对?
这些是我们打算在即将发布的博客文章中回答的一些问题。
想象一下,你以某种方式设法根据知识图谱中存储的信息生成包含问答对的训练数据集。因此,LLM 现在包含更新的知识。
然而,对模型进行微调并不能解决知识截止问题,因为它只是将知识截止推迟到以后的日期。
因此,我们建议仅针对缓慢变化或更新的数据通过微调技术更新 LLM 的内部知识。例如,您可以使用微调模型来提供旅游信息。
但是,当您想在回复中包含特殊的时间相关(实时)或个性化促销时,您就会遇到麻烦。同样,微调模型对于分析工作流程来说并不理想,因为在分析工作流程中,您会询问公司在过去一周内获得了多少新客户。
目前,微调方法可以帮助减轻幻觉,但不能完全消除幻觉。一个问题是,LLM在提供答案时不会引用其来源。因此,你不知道答案是来自预训练数据、微调数据集还是由 LLM 编造的。此外,如果你使用 LLM 创建微调数据集,可能还有另一个可能的虚假来源。
最后,经过微调的模型无法根据用户提出的问题自动提供不同的答案。同样,也没有访问限制的概念,这意味着与 LLM 交互的任何人都可以访问其所有信息。
检索增强生成
大型语言模型在自然语言应用中表现非常出色,例如
- 文本摘要,
- 提取相关信息,
- 实体消歧
- 从一种语言翻译成另一种语言,甚至
- 将自然语言转换为数据库查询或脚本代码。
此外,以前的 NLP 模型通常是针对特定领域和任务的,这意味着您很可能需要根据您的用例和领域训练自定义自然语言模型。但是,得益于 LLM 的泛化能力,可以应用单个模型来解决各种任务集合。
我们观察到使用检索增强型 LLM 的趋势相当明显,即不再使用 LLM 来访问其内部知识,而是使用 LLM作为自然语言界面您的公司或私人信息。
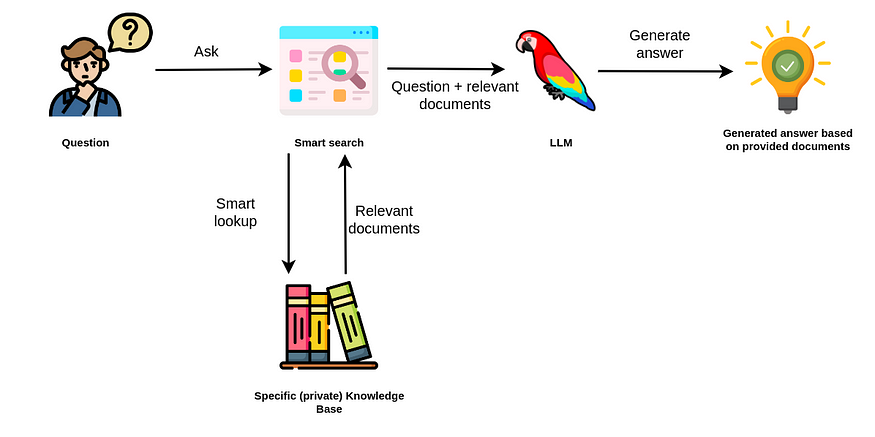
检索增强生成。图片由作者提供。图标来自Flaticons。
检索增强方法使用 LLM 根据从数据源额外提供的相关文档生成答案。
因此,你不需要依赖 LLM 的内部知识来回答问题。相反,LLM 只用于从你传入的文档中提取相关信息并进行总结。
例如,ChatGPT 插件可以被视为 LLM 应用程序的检索增强方法。启用浏览插件的 ChatGPT 界面允许 LLM 搜索互联网以访问最新信息并使用它来构建最终答案。
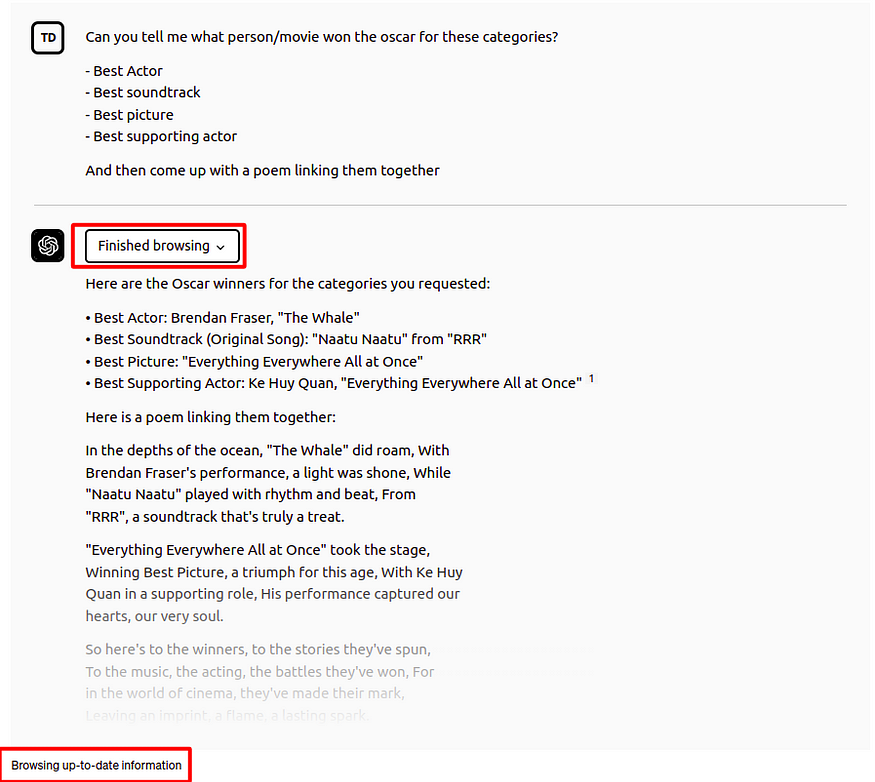
带有浏览插件的 ChatGPT。图片由作者提供。
在这个例子中,ChatGPT 能够回答谁在 2023 年获得了奥斯卡各个奖项。但请记住,ChatGPT 的知识截止日期是 2021 年,因此它无法从其内部知识中知道谁获得了 2023 年奥斯卡奖。因此,它通过浏览插件访问外部信息,这使它能够使用最新信息回答问题。这些插件在 OpenAI 平台内部提供了一种集成的增强机制。
如果您一直关注 LLM 领域,您可能听说过LangChain 库。
LangChain 库可用于让 LLM 访问来自各种来源(如 Google 搜索、矢量数据库或知识图谱)的实时信息。例如,LangChain 添加了Cypher Search 链,它将自然语言问题转换为 Cypher 语句,使用它从 Neo4j 数据库中检索信息,并根据提供的信息构建最终答案。
通过 Cypher 搜索链,LLM 不仅可用于构建最终答案,还可将自然语言问题转化为 Cypher 查询。
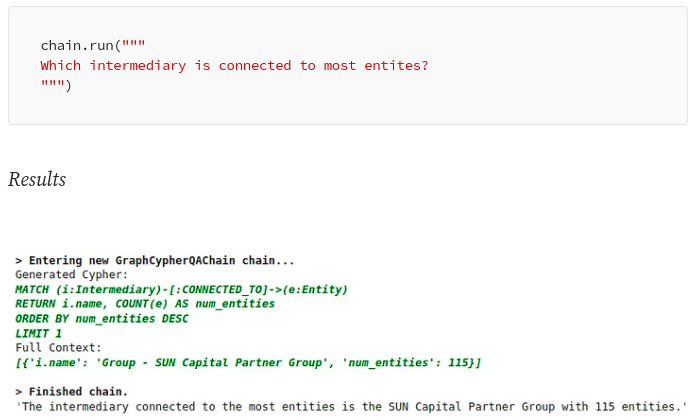
LangChain 中的 Cypher 搜索。图片由作者提供。
另一个用于检索增强型 LLM 工作流的流行库是LlamaIndex (GPT Index)。LlamaIndex 是一个全面的数据框架,旨在通过使大型语言模型 (LLM) 能够利用私有或自定义数据来提高其性能。
首先,LlamaIndex 提供数据连接器,方便接收各种数据源和格式的数据,涵盖从 API、PDF、文档到 SQL 或图形数据的所有内容。
此功能可轻松将现有数据集成到 LLM 中。其次,它提供了使用索引和图表构建所摄取数据的有效机制,确保数据经过适当排列以用于 LLM。此外,它还包括一个高级检索和查询界面,使用户能够输入 LLM 提示并接收上下文检索、知识增强的输出。
ChatGPT Plugins 和 LangChain 等检索增强型 LLM 应用程序的理念是避免仅依赖内部 LLM 知识来生成答案。相反,LLM 用于解决诸如从自然语言构建数据库查询以及根据外部提供的信息或利用插件/代理进行检索来构建答案等任务。
检索增强方法比微调方法具有一些明显的优势:
- 答案可以引用其信息来源,这允许您验证信息并根据需要更改或更新基础信息
- 幻觉不太可能发生,因为你不依赖法学硕士的内部知识来回答问题,而只使用相关文件中提供的信息
- 当你将问题从 LLM 维护转变为数据库维护、查询和上下文构建问题时,更改、更新和维护 LLM 使用的底层信息会变得更加容易
- 答案可以根据用户上下文或其访问权限进行个性化
另一方面,使用检索增强方法时应考虑以下限制:
- 答案与智能搜索工具一样好
- 应用程序需要访问您的特定知识库,可以是数据库或其他数据存储
- 完全忽略语言模型的内部知识会限制可以回答的问题数量
- 有时 LLM 不遵循指示,因此如果在上下文中找不到相关的答案数据,则可能会忽略上下文或出现幻觉。
概括
这篇博文深入探讨了大型语言模型 (LLM) 的局限性,例如
- 知识断层,
- 幻觉,以及
- 缺乏用户定制。
为了克服这些问题,我们探索了两个概念,即微调和检索增强 LLM 的使用。
微调 LLM涉及监督训练阶段,在此阶段提供问答对以优化 LLM 的性能。这可用于更新和扩展 LLM 的内部知识或针对特定任务对其进行微调。但是,微调无法解决知识截止问题,因为它只是将截止时间推迟到以后。它也不能完全消除幻觉。因此,我们建议对允许某些幻觉的缓慢变化数据集使用微调方法。由于微调 LLM 相对较新,我们渴望了解有关微调方法和最佳实践的更多信息。
克服 LLM 局限性的第二种方法是所谓的检索增强生成,其中 LLM 充当访问外部信息的自然语言接口,从而不仅仅依赖其内部知识来产生答案。检索增强方法的优点包括来源引用、可忽略的幻觉、易于更改和更新信息以及个性化。
然而,它严重依赖智能搜索工具来检索相关信息,并且需要访问用户的知识库。此外,它只有在拥有解决问题所需的信息时才能回答查询。
项目开源地址
NaLLM项目开源地址:GitHub - neo4j/NaLLM: Repository for the NaLLM project