本文介绍了雪花ID的应用场景,以及针对雪花id生成精度过大导致数据缺失的解决方案。
一、概念
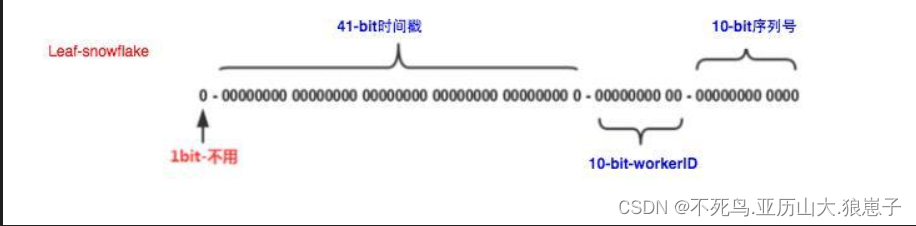
雪花 ID是一种分布式 ID 生成策略,保证全局唯一,位数组成中含有时间戳,相比UUID,故也能保证自增。
二、应用场景
分库、分表、分片、中间件集群部署、数据合并中,
如果使用自增id,易造成冲突
三、实现方式
1、生成雪花id算法
SnowflakeIdGenerator.java
package com.inspur.common.utils;
import org.springframework.beans.factory.annotation.Value;
public class SnowflakeIdGenerator {
@Value("${snowflake.dataCenterId}")
private static long dataCenterId;// 数据中心ID(可根据实际情况配置)
@Value("${snowflake.machineId}") // 机器ID(可根据实际情况配置)
private static long machineId;
// 起始的时间戳,可以根据实际情况调整
private static final long START_TIMESTAMP = 1609459200000L; // 2021-01-01 00:00:00
// 每部分占用的位数
private static final long SEQUENCE_BIT = 10; // 序列号占用的位数
private static final long MACHINE_BIT = 1; // 机器标识占用的位数
private static final long DATA_CENTER_BIT = 1; // 数据中心标识占用的位数
// 每部分的最大值
private static final long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
private static final long MAX_MACHINE_ID = ~(-1L << MACHINE_BIT);
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_BIT);
// 每部分向左的位移
private static final long MACHINE_LEFT = SEQUENCE_BIT;
private static final long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private static final long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
/*// 数据中心ID(可根据实际情况配置)
private final long dataCenterId;
// 机器ID(可根据实际情况配置)
private final long machineId;*/
// 序列号
private long sequence = 0L;
// 上次生成ID的时间戳
private long lastTimestamp = -1L;
/**
* 初始化 SnowflakeIdGenerator 对象,并设置数据中心标识和机器标识
* @param dataCenterId 数据中心标识
* @param machineId 机器标识
*/
public SnowflakeIdGenerator(long dataCenterId , long machineId) {
if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) { // 进行合法性检查,确保传入的数据中心标识和机器标识在合理范围内,否则抛出 IllegalArgumentException。
throw new IllegalArgumentException("Data center ID can't be greater than " + MAX_DATA_CENTER_ID + " or less than 0");
}
if (machineId > MAX_MACHINE_ID || machineId < 0) {
throw new IllegalArgumentException("Machine ID can't be greater than " + MAX_MACHINE_ID + " or less than 0");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* 生成雪花算法的唯一ID
* @return 最终的64位ID
*/
//确保在多线程环境下生成的ID是唯一的,防止并发冲突。如果您的应用是单线程或者在多线程环境下并发要求不高,可以适当简化同步逻辑。
public synchronized long generateId() {
long currentTimestamp = System.currentTimeMillis(); // 获取当前时间戳 currentTimestamp,以毫秒为单位。
if (currentTimestamp < lastTimestamp) { // 检查当前时间戳是否小于上一次生成ID的时间戳 lastTimestamp,如果是,说明发生了时钟回拨,抛出 RuntimeException。
throw new RuntimeException("Clock moved backwards. Refusing to generate ID for " + (lastTimestamp - currentTimestamp) + " milliseconds.");
}
if (currentTimestamp == lastTimestamp) { // 如果当前时间戳与上一次时间戳相等,则递增序列号 sequence,并通过位运算确保序列号不超过最大值。如果序列号归零,表示在同一毫秒内生成的ID数量超过限制,调用 waitNextMillis 方法等待下一毫秒。
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
currentTimestamp = waitNextMillis(currentTimestamp);
}
} else {
sequence = 0L; // 如果当前时间戳大于上一次时间戳,将序列号重置为零。
}
lastTimestamp = currentTimestamp;
/* System.out.println( ((currentTimestamp) << TIMESTAMP_LEFT) |
(dataCenterId << DATA_CENTER_LEFT) |
(machineId << MACHINE_LEFT) |
sequence);*/
// 将当前时间戳、数据中心标识、机器标识和序列号按照雪花算法的规则组合起来,生成最终的64位ID。
return ((currentTimestamp - START_TIMESTAMP) << TIMESTAMP_LEFT) |
(dataCenterId << DATA_CENTER_LEFT) |
(machineId << MACHINE_LEFT) |
sequence;
}
/**
* 时钟回拨策略:发生时钟回拨时等待下一个合适的时间戳。
* @param currentTimestamp 方法被调用时的当前时间戳
* @return 返回新的时间戳,以确保生成的ID是在递增的时间戳基础上生成的。
*/
private long waitNextMillis(long currentTimestamp) {
long timestamp = System.currentTimeMillis();
// 判断 timestamp 是否小于等于上一次生成ID的时间戳 lastTimestamp。如果是,说明当前时间戳仍然没有超过上一次生成ID的时间戳,继续在循环内等待。
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis(); // 不断更新 timestamp 为当前时间戳,直到 timestamp 大于 lastTimestamp。
}
return timestamp; // 返回新的时间戳,以确保生成的ID是在递增的时间戳基础上生成的。
}
public synchronized static long getId() {
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(dataCenterId, machineId);
return idGenerator.generateId();
}
public static void main(String[] args) {
// 根据情况决定
long dataCenterId = 1L; // 数据中心标识
long machineId = 1L; // 机器标识
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(dataCenterId, machineId);
// 使用 idGenerator 生成唯一ID
long uniqueId = idGenerator.generateId();
System.out.print(String.valueOf(uniqueId));
}
}2、应用
(1) 插入语句
objectPo.setId(SnowflakeIdGenerator.getId());
objectPo.setCreateTime(DateUtils.getNowDate());
int i = objectPoMapper.insertObjectPo(objectPoReason);(2) Mapper层
insert into objectPo_table_name
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id != null and id != ''">id,</if>
<if test="createTime != null">create_time,</if>
<if test="其他 != null">...</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="id != null and id != ''">#{id},</if>
<if test="createTime != null">#{createTime},</if>
<if test="其他!= null">#{其他},</if>
</trim>四、前后台精度缺失问题
由于雪花算法长度较大,前端接收数据类型为number类型 , 最大为16位, 如果后端 id 大于16位, 则会出现 精度丢失问题, 如雪花算法 id 为18位,就会造成精度缺失。
可以缩短雪花生成算法中的工作机器位数和序列号位数; 或者将id添加添加一个数据类型转换器,后台传至前台时Long型转为String, 前台传至后台时String转为Long。
 1、后台序列化
1、后台序列化
实体类的id或者引用存储其他表id的字段,加上:
@JsonSerialize(using = ToStringSerializer.class)
private Long id;
@JsonSerialize(using = ToStringSerializer.class)
private Long relaTableId;2、前台number
取消Number()函数使用。
3、jsonBig转化
如果存储的json数据含有雪花id, 在JSON字符串转化实体类时,注意:
JSON.parse(jsonString)会造成精度丢失,用JSONBig.parse(jsonString)取代。
npm install json-bigint
import JSONBig from 'json-bigint'4、雪花id生成位数
在雪花id生成算法中(SnowflakeIdGenerator.java),适当缩小工作机器位数和序列号位数。
如:
MACHINE_BIT
DATA_CENTER_BIT