第2章实时数仓项目需求及架构设计
2.1 项目需求分析
1)采集平台
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
2)离线需求
…
2.2 项目框架
2.2.1 技术选型
技术选型主要因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算等。
- 数据采集传输:Flume、Kafka、Maxwell、Filebeat、Logstash
- 数据存储OLTP:MySQL、HDFS、HBase、Redis、MongoDB、
- 数据存储OLAP:Clickhouse、Greenplum、TDengine、influxdb
- 数据计算: Hive、Spark、Flink
- 数据查询:Kylin、Clickhouse、Greenplum、Doris
- 数据可视化:DataV、Superset、Echarts
- 任务调度:DolphinScheduler、Azkaban、Airflow、Oozie、Xxl-job
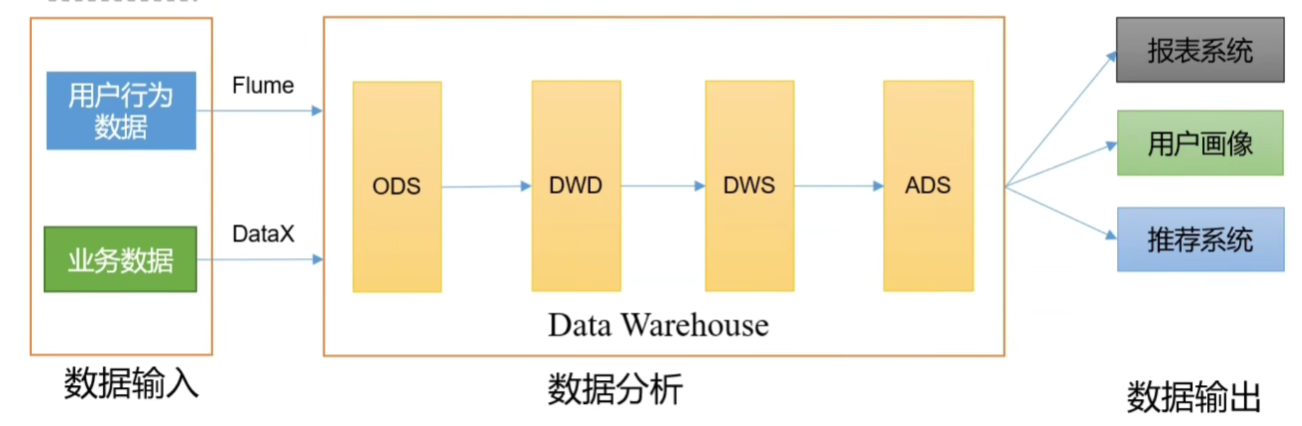
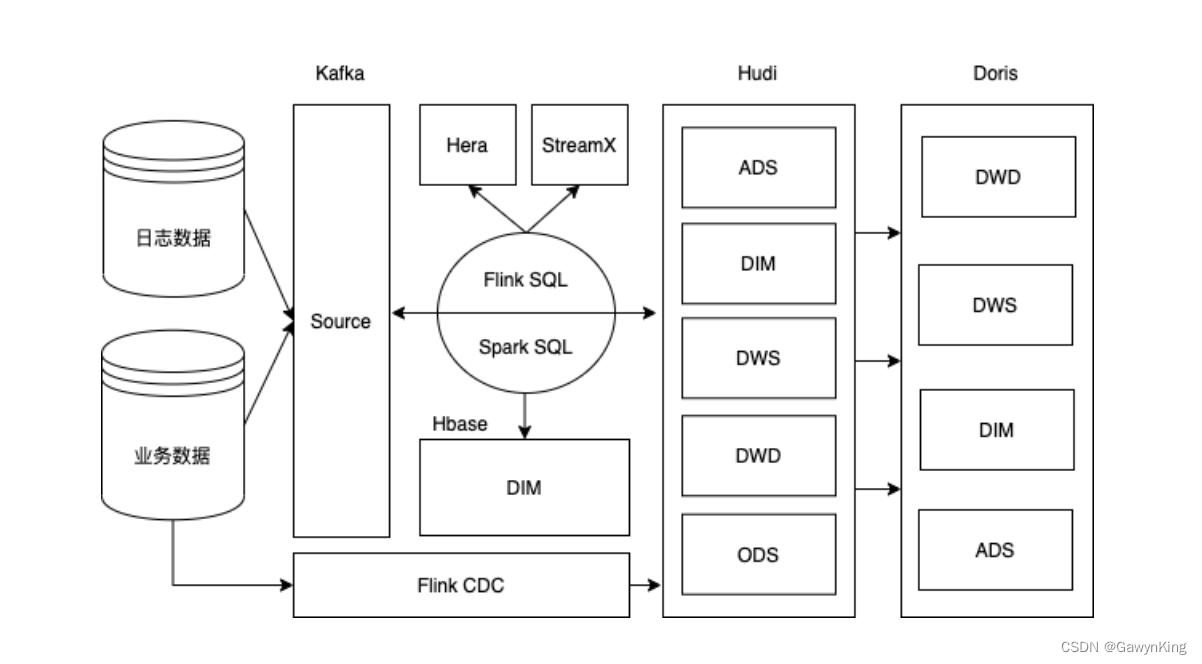
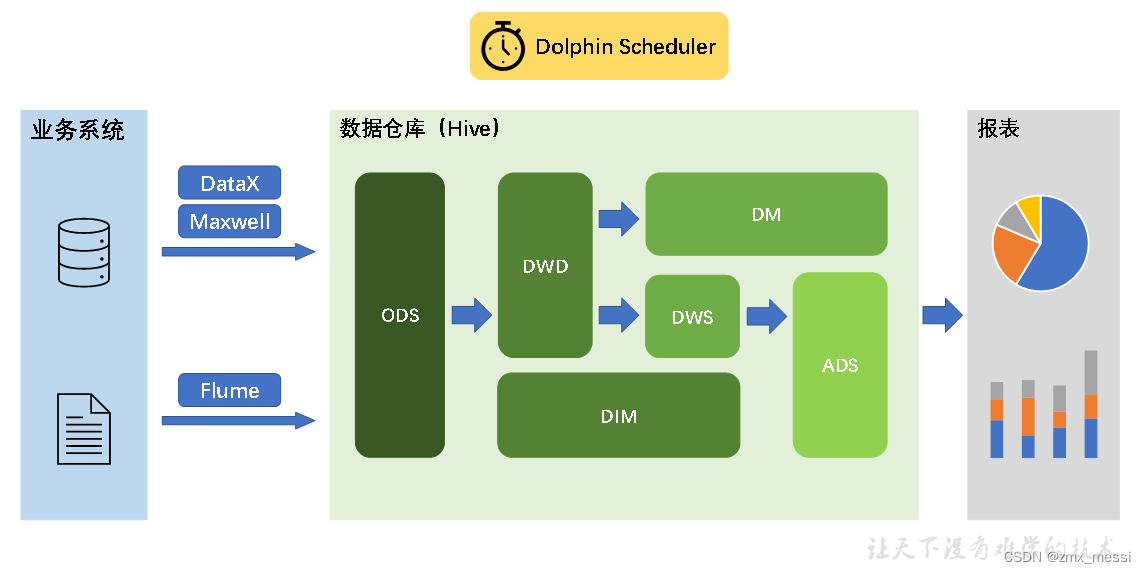
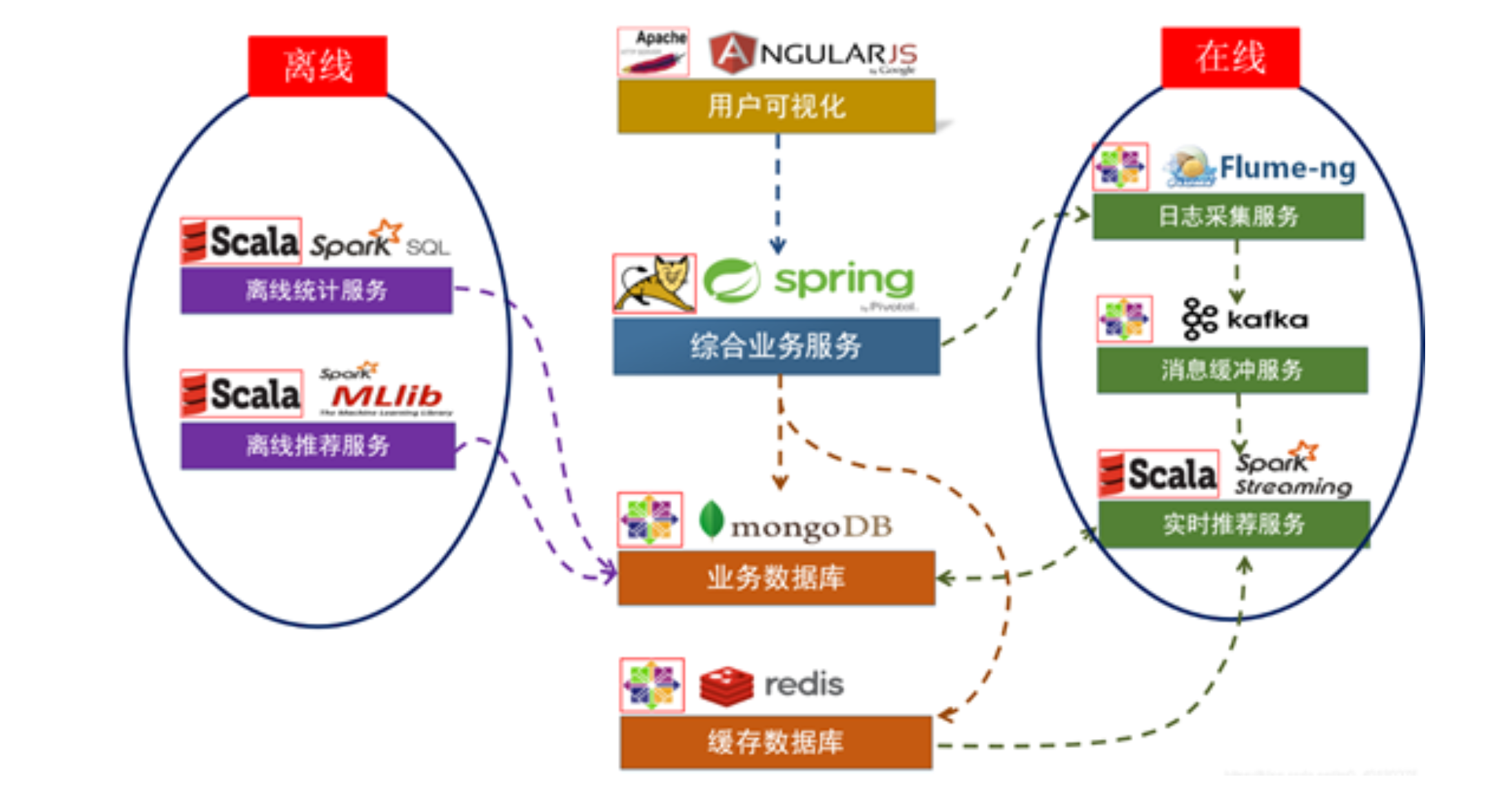
2.2.2 系统数据流程设计
数据流图 略
2.2.4 服务器选型
物理机VS云主机
物理服务器:物理服务器是指独立服务器,也就是指物理上的单独服务器,物理服务器的构成包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高
云服务器:云服务器是一种简单高效、安全可靠、处理能力可弹性伸缩的计算服务。其管理方式比物理服务器更简单高效。用户无需提前购买硬件,即可迅速创建或释放任意多台云服务器。
| 物理机 | 云主机 | |
|---|---|---|
| 投入成本 | 高额的信息化成本投入 | 按需付费,无需服务器网络和硬件维护,0运维成本,有效降低综合成本 |
| 产品性能 | 难以确保获得持续可控的产品性能 | 硬件资源的隔离+独享带宽,采用高端服务器进行部署,同时采用集中的管理与监控,确保业务稳定可靠; |
| 管理能力 | 日趋复杂的业务管理能力 | 集中化的远程管理平台+多业务备份 |
| 扩展能力 | 服务环境缺乏灵活的业务弹性 | 按用户需求灵活配置,快速的业务部署与配置、规模的弹性扩展能力 |
| 技术方面 | ||
| 安全方面 | ||
| 可靠性方面 | 而物理机则相对来说硬件冗余较少,故障率较高 | 云服务器是基于服务器集群的,因此硬件冗余度较高,故障率低 |
| 稳定性方面 | 物理机宕机就是宕机,无法挽救 | 云服务器可以故障自动迁移 |
2.2.5 集群规模
如何计算集群规模?
每天日活用户100W,没人一天平均100条。100W*100条=1亿条数据
每条数据1K左右,每天1亿数据。1亿/1024/1024=100G
1年内服务器: 100G*360天 = 36T
副本数量:3个副本。 3*36T = 108T
预留20%-30%Buffer。 108T/0.7= 150T
假如每台服务器8T硬盘 128G内存。 150T/8T=20台服务器
分仓分层则还需要重新计算。
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
2.3 规范
数据仓库建设命名规范
2.3.1 表名规范
ODS层表名: 前缀为ODS_应用系统名(缩写)数据表名 。数据表名称必须以有特征含义的单词或缩写组成,中间可以用“”分割,例如:ODS_FUN_CUSTOMERINFO。表名称不能用双引号包含,表名长度不超过30个字符。如果ODS设计采用贴源设计,数据表名应与源系统一致
集成入库,一般用这样的命名规范来表示:
imp_ods_{源系统库}_{源表名}_date表的命名,基本可以遵循以下规范:
ods_{源系统库}_{源表名}_date如果有特殊的时间要求,可在表后面加对应的时间标识,如 1d 或者 1m。
DW事实表表名: 前缀为DW_主题名(缩写)功能描述 。数据表名称必须以有特征含义的单词或缩写组成,中间可以用“”分割,例如:DW_ORD_DETAIL。表名称不能用双引号包含,表名长度不超过30个字符。
维度表表名
前缀为dm_ 。数据表名称必须以有特征含义的单词或缩写组成,中间可以用“_”分割,例如:D_ACCOUNT、D_PUB_DATE。表名称不能用双引号包含,表名长度不超过30个字符。
元数据表名: 前缀为M_应用名(缩写)功能描述 。数据表名称必须以有特征含义的单词或缩写组成,中间可以用“”分割,例如:M_ETL_TASK。表名称不能用双引号包含,表名长度不超过30个字符
第3章 用户行为日志
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点等。
****代码埋点****是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
****可视化埋点****只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
****全埋点****是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
3.2 用户行为日志内容
本项目收集和分析的用户行为信息主要有****页面浏览记录、动作记录、曝光记录、启动记录和错误记录。****
3.2.1 页面浏览记录
页面浏览记录,记录的是访客对页面的浏览行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及页面信息等。
第4章 用户行为数据采集模块
flum安装配置
kafka安装配置
数据采集测试
宽表、窄表、维度表、事实表
一、概念
宽表:把多个维度的字段都放在一张表存储,增加数据冗余是为了减少关联,便于查询,查询一张表就可以查出不同维度的多个字段
窄表:和我们MySql普通表三范式相同,把相同维度的字段组成一张表,表和表之间关联查询其他维度数据。
维度表:包含维度编码和该维度下的多个属性。
注意 dw(dwd 和dws):存放着明细事实数据、维表数据及公共指标汇总数据,其中明细事实数据,维表数据一般通过ODS层数据加工生成;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
事实表:包含一个业务事件的相关属性。
事实表就是交易表。
维度表就是基础表。
用来解释事实表中关键字纬度的具体内容
二、宽表
2.1 宽表概念
宽表,顾名思义,就是比普通的数据表宽的表,比如数据库表一,在数据库中是五个字段,表二是四个字段,宽表就是把这两个有业务联系的表通过关联字段弄到一个大表中,这样列数自然就变多了,表也就宽了,所以就有了宽表。
2.2 为什么要用宽表
业务人员在做数据分析时,所需要的数据往往会存储在数据库的多张数据表中,比如订单表中存储了订单编号、商品编号、订购日期等,商品表中存储了商品名称、单价等商品信息,如果要同时查看订单和商品信息,业务人员不知道数据结构,也很难做表间关联,所以就要技术人员将两个表提前关联好形成宽表。
在olap技术发展过程中主要有MOLAP和ROLAP两种形式,MOLAP中的数据文件通常叫做“CUBE”,这个名字大家都比较熟悉了,一般是各个olap产品自己的数据文件格式。而随着数据库性能的提升,ROLAP 产品逐渐流行起来(本文后续用到的产品润乾报表就是一个典型的 ROLAP 产品),ROLAP 中数据保留在关系数据库的事实表中,在使用用途上来说宽表约等于 CUBE。
通过宽表的使用,既能解决多维分析时多表的关联问题又能提高数据查询的速度和分析操作的便捷性。
功能模型
元数据管理
基础事件维护
基础事件元数据表
| 字段名 | 类型 | 说明 |
|---|---|---|
| event_id | bigint | 主键 |
| event_name | varchar | 事件名称 |
| event_mark | varchar | 事件标识符 |
| event_group | bigint | 事件分组 |
| event_change | int(1) | 标记为转化 0 否 1 是 |
| create_time | datetime | 创建时间 |
| attr_ids | varchar | 属性列表 |
事件属性维护
属性表
| 字段名 | 类型 | 说明 |
|---|---|---|
| attr_id | bigint | 主键 |
| attr_name | varchar | 属性名 |
| attr_mark | varchar | 属性标识符 |
| attr_type | int(1) | 属性类型 1 文本 2 数字 3 是非 |
| create_time | datetime | 创建时间 |
ods 明细表
ods_pv_event_yyyyMMdd
| 字段 | 类型 | 说明 |
|---|---|---|
| create_time | datetime | 访问时间 |
| source | varchar | 来源 |
| url | varchar | 页面url |
| client_ip | varchar | 访问ip |
| uid | varchar | 访客标识码 |
| client_type | int(1) | 设备类型:1 pc 2 h5 3 app |
| method | varchar | enum :get post delete put |
| result_code | varchar | 访问结果状态码 |
dim维度表
dim_省份
| 字段 | 类型 | 说明 |
|---|---|---|
| city_id | int | id |
| city_name | varchar | 城市名称 |
| parent_id | int | 父id |
| city_code | varchar | 城市编码 |
| create_time | datetime | 创建时间 |
dim_客户端类型
| 字段 | 类型 | 说明 |
|---|---|---|
| client_id | int | id |
| client_name | varchar | 城市名称 |
| create_time | datetime | 创建时间 |
dw汇总数据
dw_pv_uv_cnt
| 字段 | 类型 | 说明 |
|---|---|---|
| yyyyMMdd | datetime | 日 |
| pv_num | int | pv浏览量 |
| uv_num | int | uv浏览量 |
| create_time | datetime | 创建时间 |
数据下载
数据治理
元数据管理实践&数据血缘
什么是元数据?元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如数据表格的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等等。
管理这些附加MetaData信息的目的,一方面是为了让用户能够更高效的挖掘和使用数据,另一方面是为了让平台管理人员能更加有效的做好系统的维护管理工作。
元数据管理平台管什么
数据治理的第一步,就是收集信息,很明显,没有数据就无从分析,也就无法有效的对平台的数据链路进行管理和改进。所以元数据管理平台很重要的一个功能就是信息的收集,至于收集哪些信息,取决于业务的需求和我们需要解决的目标问题。信息收集再多,如果不能发挥作用,那也就只是浪费存储空间而已。所以元数据管理平台还需要考虑如何以恰当的形式对这些元数据信息进行展示,进一步的,如何将这些元数据信息通过服务的形式提供给周边上下游系统使用,真正帮助大数据平台完成质量管理的闭环工作。
应该收集那些信息,虽然没有绝对的标准,但是对大数据开发平台来说,常见的元数据信息包括:
- 数据的表结构Schema信息
- 数据的空间存储,读写记录,权限归属和其它各类统计信息
- 数据的血缘关系信息
- 数据的业务属性信息


























![算法:[动态规划] 斐波那契数列模型](https://img-blog.csdnimg.cn/direct/90585557400244abbdbd6329c06ac1c3.png)