作为一名大数据开发者,我经常需要处理海量的数据传输和存储。在这个过程中,选择一个高效、可靠的数据序列化工具至关重要。今天,我想和大家分享一下我在项目中使用 Protobuf 的经历。

故事背景
在我们团队的一个项目中,我们需要从多个传感器收集实时数据,并将这些数据传输到集中式服务器进行分析。起初,我们使用的是 JSON 格式,因为它易于阅读和调试。然而,随着数据量的增加,我们遇到了性能瓶颈:数据传输的速度越来越慢,服务器的处理负荷也越来越重。
在这种情况下,我们开始寻找一种更高效的数据传输方案。经过调研和比较,我们最终选择了 Google 的 Protocol Buffers(简称 Protobuf)。
Protobuf 简介
Protobuf 是一种灵活、高效的序列化工具,由 Google 开发。它可以将结构化的数据序列化为二进制格式,这种格式比 JSON 或 XML 更加紧凑和高效。

优点:
- 高效的二进制格式:Protobuf 使用二进制格式进行数据传输,比 JSON 更小、更快。
- 强类型定义:通过 .proto 文件定义数据结构,保证了数据的严格类型约束。
- 多语言支持:支持多种编程语言,如 C++、Java、Python、Go 等。
实战案例
以下是几个使用 Protobuf 进行数据传输的示例:
示例一:传感器数据
首先,我们需要定义一个 .proto 文件,描述数据结构。例如,我们的传感器数据包含传感器 ID、时间戳和温度值,可以这样定义:
syntax = "proto3";
message SensorData {
int32 sensor_id = 1;
int64 timestamp = 2;
float temperature = 3;
}
然后,使用 protoc 编译 .proto 文件,生成相应语言的代码。假设我们使用 Python,可以运行以下命令:
protoc --python_out=. sensor.proto
接下来,我们可以编写 Python 代码来序列化和反序列化数据:
import sensor_pb2
# 创建一个 SensorData 对象
sensor_data = sensor_pb2.SensorData()
sensor_data.sensor_id = 1
sensor_data.timestamp = 1623072023
sensor_data.temperature = 23.5
# 序列化为二进制数据
serialized_data = sensor_data.SerializeToString()
# 反序列化为对象
sensor_data_parsed = sensor_pb2.SensorData()
sensor_data_parsed.ParseFromString(serialized_data)
# 打印结果
print(f"Sensor ID: {sensor_data_parsed.sensor_id}")
print(f"Timestamp: {sensor_data_parsed.timestamp}")
print(f"Temperature: {sensor_data_parsed.temperature}")
示例二:用户信息
假设我们需要传输用户信息,包括用户 ID、用户名和邮箱地址,可以定义如下的 .proto 文件:
syntax = "proto3";
message User {
int32 user_id = 1;
string username = 2;
string email = 3;
}
同样地,使用 protoc 编译 .proto 文件,生成相应的 Python 代码:
protoc --python_out=. user.proto
然后,编写 Python 代码来处理用户信息:
import user_pb2
# 创建一个 User 对象
user = user_pb2.User()
user.user_id = 123
user.username = "Alice"
user.email = "alice@example.com"
# 序列化为二进制数据
serialized_user = user.SerializeToString()
# 反序列化为对象
user_parsed = user_pb2.User()
user_parsed.ParseFromString(serialized_user)
# 打印结果
print(f"User ID: {user_parsed.user_id}")
print(f"Username: {user_parsed.username}")
print(f"Email: {user_parsed.email}")
示例三:复杂数据结构
如果我们需要传输更复杂的数据结构,例如用户信息包含多个地址,可以定义如下的 .proto 文件:
syntax = "proto3";
message Address {
string street = 1;
string city = 2;
string state = 3;
string zip = 4;
}
message User {
int32 user_id = 1;
string username = 2;
string email = 3;
repeated Address addresses = 4;
}
编译 .proto 文件,生成相应的代码:
protoc --python_out=. user.proto
然后,编写 Python 代码来处理复杂数据结构:
import user_pb2
# 创建一个 User 对象
user = user_pb2.User()
user.user_id = 123
user.username = "Alice"
user.email = "alice@example.com"
# 添加地址
address1 = user.addresses.add()
address1.street = "123 Main St"
address1.city = "Springfield"
address1.state = "IL"
address1.zip = "62701"
address2 = user.addresses.add()
address2.street = "456 Oak St"
address2.city = "Metropolis"
address2.state = "NY"
address2.zip = "10001"
# 序列化为二进制数据
serialized_user = user.SerializeToString()
# 反序列化为对象
user_parsed = user_pb2.User()
user_parsed.ParseFromString(serialized_user)
# 打印结果
print(f"User ID: {user_parsed.user_id}")
print(f"Username: {user_parsed.username}")
print(f"Email: {user_parsed.email}")
for address in user_parsed.addresses:
print(f"Address: {address.street}, {address.city}, {address.state} {address.zip}")
性能对比
为了展示 Protobuf 的优势,我们做了一个简单的性能对比实验。在相同的数据量下,我们分别使用 JSON 和 Protobuf 进行序列化和反序列化,并比较两者的性能。
以下是 Python 代码示例,用于对比 JSON 和 Protobuf 的性能:
import time
import json
import sensor_pb2
# 生成样本数据
data = {
"sensor_id": 1,
"timestamp": 1623072023,
"temperature": 23.5
}
# JSON 序列化和反序列化
start_time = time.time()
for _ in range(100000):
json_data = json.dumps(data)
data_parsed = json.loads(json_data)
end_time = time.time()
json_time = end_time - start_time
# Protobuf 序列化和反序列化
sensor_data = sensor_pb2.SensorData()
sensor_data.sensor_id = 1
sensor_data.timestamp = 1623072023
sensor_data.temperature = 23.5
start_time = time.time()
for _ in range(100000):
serialized_data = sensor_data.SerializeToString()
sensor_data_parsed = sensor_pb2.SensorData()
sensor_data_parsed.ParseFromString(serialized_data)
end_time = time.time()
protobuf_time = end_time - start_time
print(f"JSON time: {json_time} seconds")
print(f"Protobuf time: {protobuf_time} seconds")
结果显示,Protobuf 的序列化和反序列化速度远高于 JSON,尤其在数据量较大的情况下,这种优势更加明显。
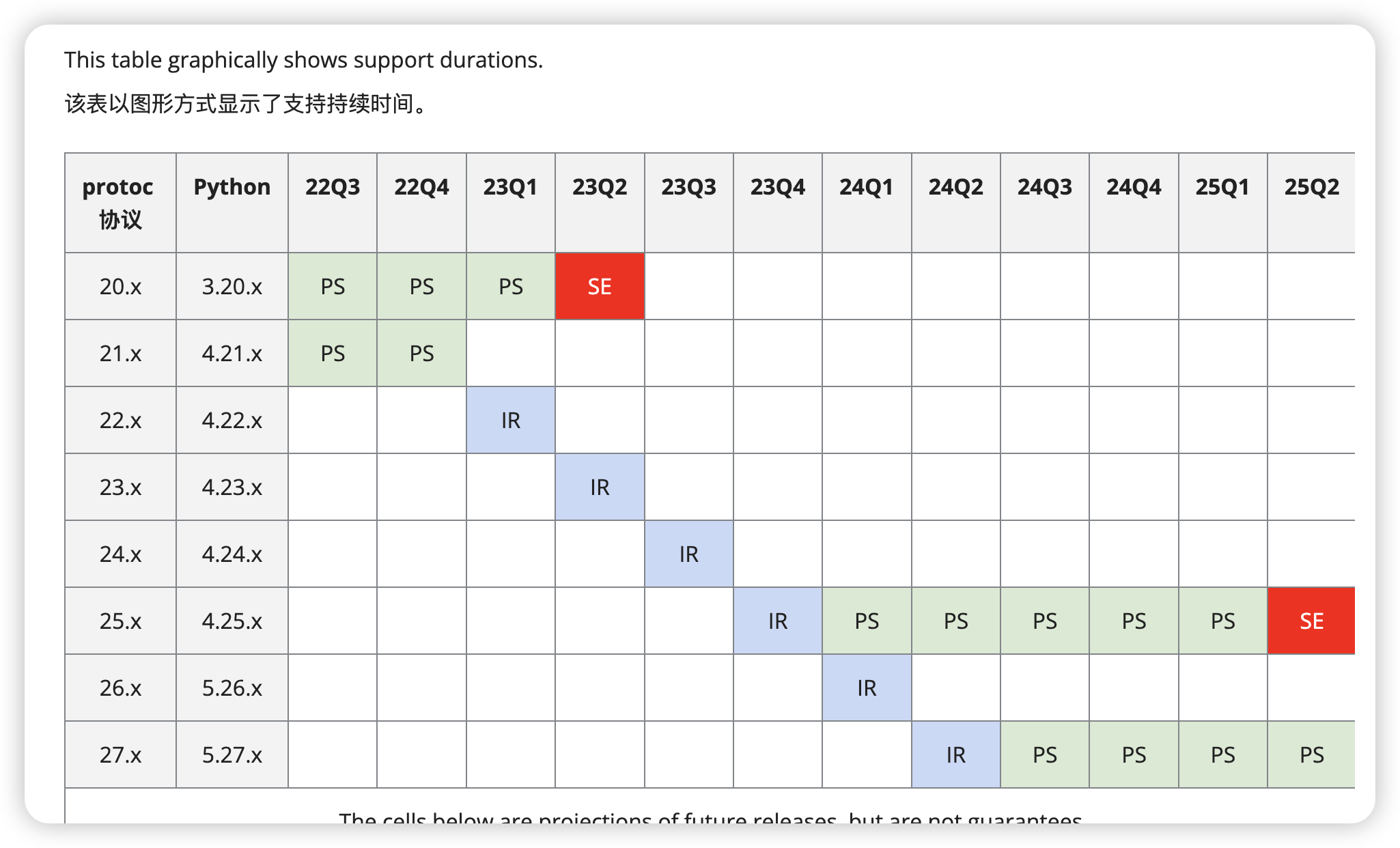
版本说明
2.x 早就过时了

现在都用 4.25x 这样的,甚至是 5.27x,对应的编译器版本是 27x
总结
通过这些示例,我们可以看到 Protobuf 在大数据传输中的强大优势。它不仅提高了数据传输的效率,还保证了数据的类型安全。
如果你的项目中也需要处理大量的数据传输,不妨尝试一下 Protobuf,如果不大量还是 json 吧~