1.简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析“标签树”等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
2.Beautiful Soup安装
目前,Beautiful Soup的最新版本是4.x版本,之前的版本已经停止开发,这里推荐使用pip来安装,安装命令如下:
pip install beautifulsoup4
验证安装:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','html.parser')
print(soup.p.string)
执行结果如下:
Hello
注意:这里虽然安装的是beautifulsoup4这个包,但是引入的时候却是bs4,因为这个包源代码本身的库文件名称就是bs4,所以安装完成后,这个库文件就被移入到本机Python3的lib库里,识别到的库文件就叫作bs4。
因此,包本身的名称和我们使用时导入包名称并不一定是一致的。
3. BeautifulSoup库解析器
解析器 |
使用方法 |
条件 |
bs4的HTML解析器 |
BeautifulSoup(mk,'html.parser') |
安装bs4库 |
lxml的HTML解析器 |
BeautifulSoup(mk,'lxml') |
pip install lxml |
lxml的XML解析器 |
BeautifulSoup(mk,'xml') |
pip install lxml |
html5lib的解析器 |
BeautifulSoup(mk,'htmlslib') |
pip install html5lib |
如果使用lxml,在初始化BeautifulSoup时,把第二个参数改为lxml即可:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','lxml')
print(soup.p.string)
4. BeautifulSoup的基本用法
BeautifulSoup类的基本元素
基本元素 |
说明 |
Tag |
标签,基本信息组织单元,分别用<>和</>标明开头和结尾 |
Name |
标签的名字,<p></p>的名字是‘p’,格式:<tag>.name |
Attributes |
标签的属性,字典形式组织,格式:<tag>.attrs |
NavigableString |
标签内非属性字符串,<>...<>中字符串,格式:<tag>.string |
Comment |
标签内字符串的注释部分,一种特殊的Comment类型 |
实例展示BeautifulSoup的基本用法:
>>> from bs4 import BeautifulSoup
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title #获取标题
<title>This is a python demo page</title>
>>> soup.a #获取a标签
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.title.string
'This is a python demo page'
>>> soup.prettify() #输出html标准格式内容
'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p class="title">\n <b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p class="course">\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n </a>\n and\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>'
>>> soup.a.name #每个<tag>都有自己的名字,通过<tag>.name获取
'a'
>>> soup.p.name
'p'
>>> tag = soup.a
>>> tag.attrs
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class']
['py1']
>>> tag.attrs['href']
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs)
<class 'dict'>
>>> type(tag)
<class 'bs4.element.Tag'>
>>>
5. 标签树的遍历
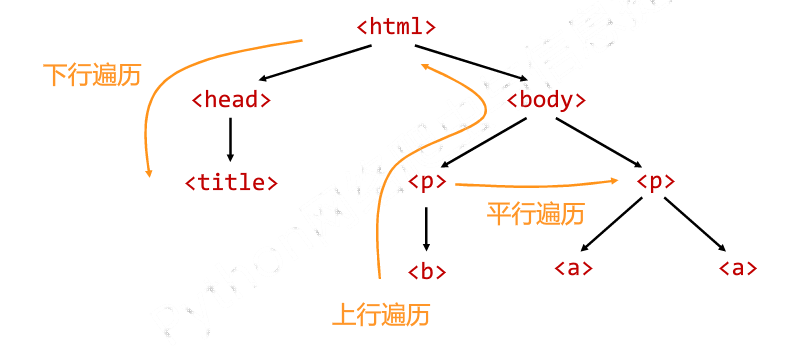
标签树的下行遍历

标签树的上行遍历:遍历所有先辈节点,包括soup本身

标签树的平行遍历:同一个父节点的各节点间

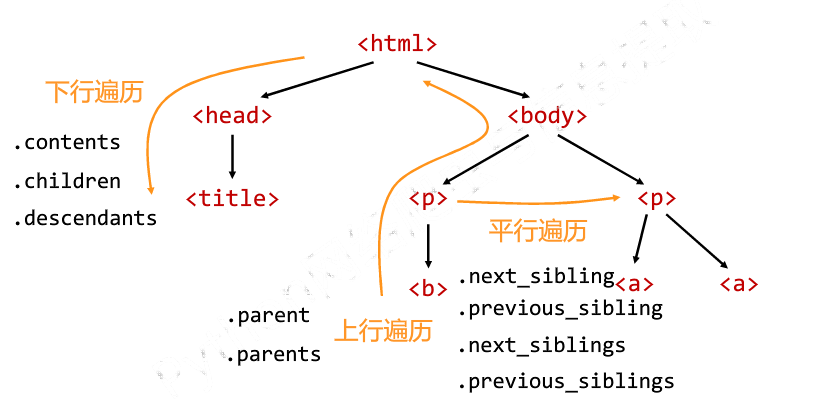
实例演示:
from bs4 import BeautifulSoup
import requests
demo = requests.get("http://python123.io/ws/demo.html").text
soup = BeautifulSoup(demo,"html.parser")
#标签树的上行遍历
print("遍历儿子节点:\n")
for child in soup.body.children:
print(child)
print("遍历子孙节点:\n")
for child1 in soup.body.descendants:
print(child1)
print(soup.title.parent)
print(soup.html.parent)
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
#标签树的平行遍历
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
最后:如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】

























![DWM 相关实现代码 [自用]](https://i-blog.csdnimg.cn/direct/ffe39003f5a54dffb16d27804131740e.png)

![关于delete和delete[ ]混用的未定义问题解释](https://i-blog.csdnimg.cn/direct/d54be688f17d47f78d81e3b531a284f2.png)