不知不觉已经到了第16天,打卡营已经时间过半了。今天学的内容是GPT2文本摘要,记录一下:
基于MindSpore的GPT2文本摘要
数据集加载与处理
数据集加载
本次实验使用的是nlpcc2017摘要数据,内容为新闻正文及其摘要,总计50000个样本。
数据预处理
原始数据格式:
article: [CLS] article_context [SEP] summary: [CLS] summary_context [SEP]预处理后的数据格式:
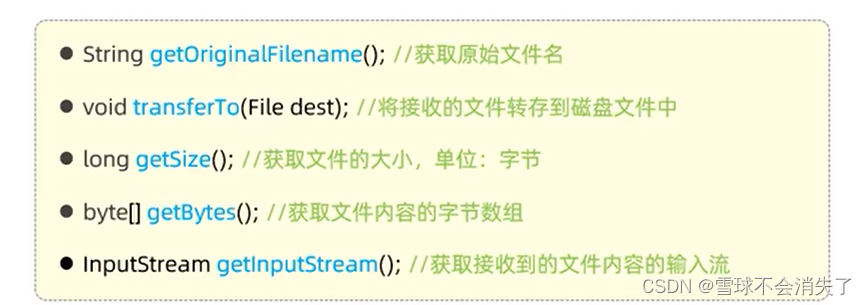
[CLS] article_context [SEP] summary_context [SEP]因GPT2无中文的tokenizer,我们使用BertTokenizer替代。
模型构建
- 构建GPT2ForSummarization模型,注意shift right的操作。
- 动态学习率
模型训练
模型推理
数据处理,将向量数据变为中文数据
model = GPT2LMHeadModel.from_pretrained('./checkpoint/gpt2_summarization_epoch_0.ckpt', config=config)
model.set_train(False)
model.config.eos_token_id = model.config.sep_token_id
i = 0
for (input_ids, raw_summary) in test_dataset.create_tuple_iterator():
output_ids = model.generate(input_ids, max_new_tokens=50, num_beams=5, no_repeat_ngram_size=2)
output_text = tokenizer.decode(output_ids[0].tolist())
print(output_text)
i += 1
if i == 1:
break