目录
读写csv 文件时,通常需要处理文件路径、打开模式、字符编码等问题。newline='' 参数通常在读写csv 文件时需要用到,可确保不会因为 Windows 系统的换行符而影响文件的读写。txt文件和csv文件之间本身支持相互转换,因此txt文件的读写等操作方法完全适用于csv文件。
csv库方法参数
| 参数 | 默认值 | 描述 |
| delimiter | , | 它是指用于分隔 CSV 文件中的值(或字段)的字符。 |
| skipinitialspace | FALSE | 它控制定界符后面的空格的解释方式。 如果为True,则将删除初始空格。 |
| lineterminator | \r\n | 它是指用于终止行的字符序列。 |
| quotechar | " | 它指的是如果字段中出现特殊字符(如定界符),则将用于引用值的单个字符串。如对于“0,0”中包含”,“的情况,可以使用quotechar="\"" 将”“内的数据作为一个整体,使用‘0,0’则将quotechar="'"即可 |
| quoting | csv.QUOTE_NONE | 控制引号由作者生成或由读者识别的时间(其他选项请参见上文)。 |
| escapechar | None | 引用设置为引号时,它用于转义定界符的一字符字符串。 |
| doublequote | TRUE | 控制字段内引号的处理。 当True时,在读取期间将两个连续的引号解释为一个,而在写入时,将嵌入数据中的每个引号字符写入为两个引号。默认情况下,doublequote设置为True。 结果,在读取两个连续的双引号时会被解释为一个。如果将doublequote设置为False,则连续的双引号将出现在输出中。 |
读取数据
csv.reader方法
import csv
with open(file_name, 'r', encoding='utf-8-sig') as f:
reader = csv.reader(f) # 创建csv阅读器对象,读取所有有效数据,返回结果为一个迭代器类对象
for data in reader: # 遍历每一行的数据
print(data)encoding可指定编码格式为utf-8-sig ,这样可自动处理BOM字符,消除\ufeff的出现.
文件指定行或列数据读取操作
with open(file_name, 'r', encoding='utf-8-sig') as f:
reader = csv.reader(f)
list_csv = list(reader)
for i in range(len(list_csv)-5,len(list_csv)): # 如读取后5行数据
print(list_csv[i])
print(list_csv[i][:3]) # 读取指定列数据txt文件的readlines、read方法
使用txt文件的读取方式readlines()、read(),读取数据中有换行符需要处理。不需要导入csv库
with open(file_name, 'r', encoding='utf-8-sig') as f:
reader_lines = f.readlines() # 读取所有行放在一个列表中
for da in reader_lines: # 也可以使用range方法读取指定行的数据,读取结果中有换行符需要处理
print(da.replace('\n',''))
reader = f.read()
print(reader)csv.DictReader方法
以字典形式读取数据,打印出的数据为字典键值对形式的数据。
with open(file_name,'r', encoding='utf-8-sig',newline='') as f:
reader =csv.DictReader(f)
for r in reader:
print(r)写入数据
txt文件的write,writelines
无需要导入csv库
使用txt文件的write,writelines 写入数据,在使用时将字符中的英文逗号识别为横向制表符tab,将换行符识别为纵向制表符enter进行换行。如果要插入空行,写入数据参数用换行符,如果写入空的单元格,写入数据参数为英文逗号。
with open(file_name, 'w', newline='') as f:
f.write('测试写入数据操作\n')
f.write('\n')
f.writelines(["角色管理,测试测试", "账号管理\n", "部门管理\n"]) 
csv.writer方法
写入数据时接受一个变量可以是字符串,列表,元组,集合,字典等可遍历的对象[字符串会将每个字符分开填入到单元格,字典将key遍历写入]。writerow单行数据写入、writerows多行数据写入。
with open(file_name, 'w', newline='') as f:
ws = csv.writer(f) # 创建一个写入文件对象
ws.writerow([]) # 列表内容为空,插入的是一个空行
ws.writerow(["设备实时监控", "设备数据列表", "设备报警分析"]) # 列表数据
ws.writerow(("角色管理", "账号管理", "部门管理")) # 元组数据
write_data = ['贾史王薛',
['贾不假,白玉为堂金作马', '阿房宫,三百里,住不下金陵一个史', '东海缺少白玉床,龙王请来金陵王',
'丰年好大雪,珍珠如土金如铁'], ('cao', 'xue', 'qin', 'shu'), {'曹', '雪', '芹', '书'},
{'贾': '宝玉', '史': '湘云', '王': '熙凤', '薛': '宝钗'},
{'贾': '宝玉', '史': '湘云', '王': '熙凤', '薛': '宝钗'}.values()]
ws.writerows(write_data) # writerows写入多行数据
csv.DictWriter方法
DictWriter写入数据时需要根据字典key判断 key是否在fieldnames中,不存在会报错,如果需要添加所有已知及未知字典数据,可以先读取需要写入的数据所有key,进行和原文件表头对比(读取原文件表头),将其加入表头列表中再写入数据。

fieldnames = ['姓氏', '人物', '说明'] # 表头
dictate = [{'姓氏': '贾', '人物': "宝玉"}, {'姓氏': '史', '人物': "湘云"}, {'姓氏': '王', '人物': "熙凤"},
{'姓氏': '薛', '人物': "宝钗"}]
with open(file_name, 'w', newline='') as f:
write = csv.DictWriter(f, fieldnames=fieldnames, delimiter=',')
write.writeheader() # 写入表头
write.writerow({'姓氏': '贾', '人物': "宝玉"}) # 单行模式写入
write.writerows(dictate) # 多行模式写入读写联合(修改及插入数据)
原理:先读取原文件数据,转列表存储,再获取的列表基础上使用列表方法做增删等操作,最后将修改后的列表数据采用多行写入的方式写入到文件中。
# 第一步:读取数据
with open(file_name, 'r+', newline='') as f:
file_csv_data = list(csv.reader(f))
# 第二步:操作数据
# 插入数据
file_csv_data.insert(2, '贾史王薛') # 在某行插入一行数据,如在第3行插入数据
file_csv_data[2].insert(0, '红楼四大家族') # 在指定单元格插入数据,如在3行1列的单元格插入数据
# 修改数据
file_csv_data[2] = ['贾不假,白玉为堂金作马', '阿房宫,三百里,住不下金陵一个史', '东海缺少白玉床,龙王请来金陵王',
'丰年好大雪,珍珠如土金如铁', ''] # 修改指定行一行数据
file_csv_data[2][4] = '葫芦僧判葫芦案' # 修改某一单元格数据,如修改3行5列数据
# 修改符合条件的数据数据
# 修改符合要求的单元格数据:通过for循环遍历判断,例如修改单元格中包含1的数据,将1替换成一
# for r_id, row in enumerate(file_csv_data): # 通过行号列号修改
# for c_id, col in enumerate(row):
# if '1' in col:
# file_csv_data[r_id][c_id] = col.replace('1', '一')
for row in file_csv_data: # 通过行数据及列号修改,比上面更方便
for c_id, col in enumerate(row):
if '1' in col:
row[c_id] = col.replace('1', '一')
# 第三步:写入报存数据
with open(file_name, 'w', newline='') as f:
write_file = csv.writer(f)
write_file.writerows(file_csv_data)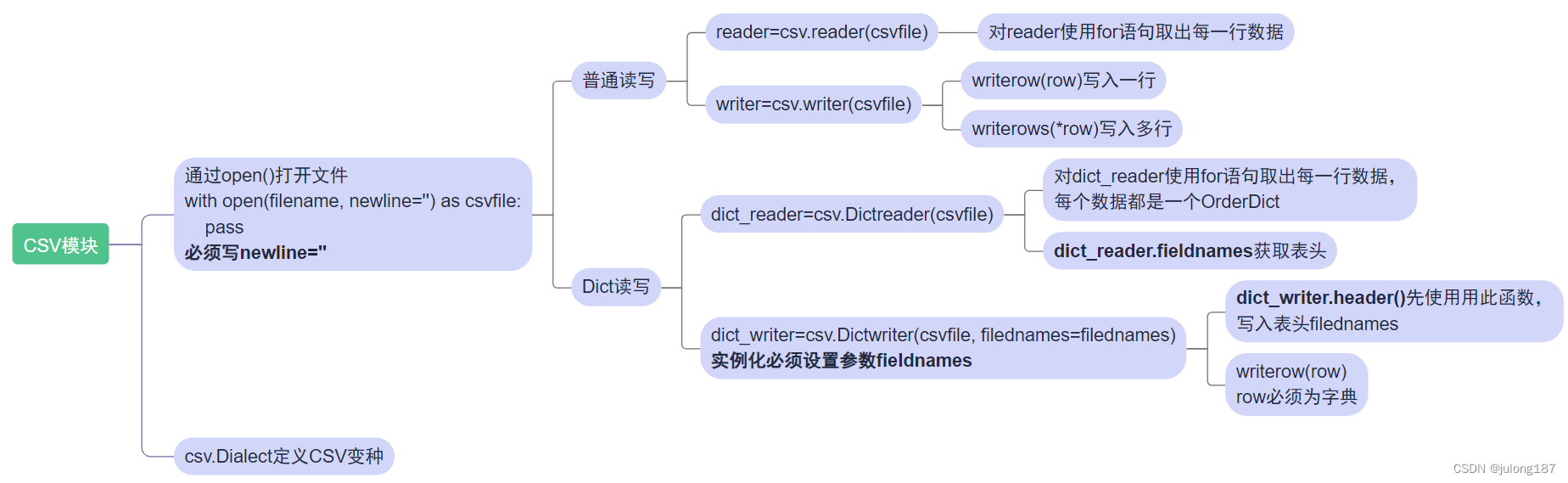



































![[图解]SysML和EA建模住宅安全系统-13-时间图](https://i-blog.csdnimg.cn/direct/3da983450460400cbee73a30af6e9c5e.png)