背景信息
团队:百度
代码:https://github.com/bdvisl/DriveInsight
论文思想简述:这篇论文并不是提出SOTA模型,而是提出了一些评估模型的方法。
目前已有的分析方法
- 大语言模型。VAQ来提供解释性,比如DriveVLM,问题是存在inaccurate explanations(这个问题怎么证明?)
- 因果注意力模块,比如NEAT(Neat: Neural attention fields for end-to-end
autonomous driving,2021, ICCV)(我没看过,不懂) - 反事实解释conterfactual explanation。比如Octet(Octet:
Object-aware counterfactual explanations,2023,CVPR)(我没看过,不懂) - 辅助任务auxiliary tasks。辅助输出目标检测、语义分割、障碍物预测等。
- 因果鉴定casual identification。多种输入可能导致因果迷惑casual confusion,PlanTF等在尝试解决。
本文先定性分析因果因素causal factors,然后定量分析每个因素的贡献。
模型评估方法
先自己搭了一个模型
- image encoder -> Resnet with fetrure pyramid network
- lidar encoder -> 3D sparse convolution + hourglass vonvolution
- multi-modal fusion -> fuse image and lidar input -> 2D convolution + Squeeze and Excitation blocks -> BEV_t
- temporal fusion -> 多个历史时刻下BEV -> convolution + SE blocks
- planning decoder -> fused BEV + ego vehicle status + environment(HD, obs, traffic lights, stop signs) + navigation(command, target point, routing)
模型结果评估
- RC, route completion
- IS, infration score
- DS, driving score,上述之乘积
模型因果评估
消融实验
BEV,routing,目标位置必不可少(为什么模型要target point呢?这是不是提示太明显了)
历史速度信息可以去掉,没啥影响
反事实干涉conterfactual intervention
- 如果输入错误的routing和目标位置,模型是会出错的the behavior of the ego vehicle can be successfully intervened;
- 当前速度有很大影响。很无聊,肯定会学错的;
- Map没啥影响,因为BEV已经给足够的信息了;
- Traffic light有很大影响。废话。
可视化分析
- 不同token的梯度,反应当前的关注程度(为啥得是梯度呢?)
- 不同head中,不同token的梯度,反应不同head对信息的倾向程度preferences
- 激活地图可视化activation map visualization。(看不明白为什么要对p求偏导)。反映对场景中不同区域的关注程度。
评价
- 有些方法早已经在用了(消融实验)
- 有些点很小(反事实干涉,名字比较高大上)
- 可视化分析的充分性如何证明?

![[<span style='color:red;'>论文</span><span style='color:red;'>精读</span>]Dynamic Coarse-<span style='color:red;'>to</span>-Fine Learning for Oriented Tiny Object Detection](https://img-blog.csdnimg.cn/direct/84be855d8fee435d834abf7d45d81a7c.png)
![【<span style='color:red;'>论文</span><span style='color:red;'>精读</span>】L-QoCo: Learning <span style='color:red;'>to</span> Optimize Cache Capacity Overloading in Storage Systems 存储方向A类<span style='color:red;'>论文</span>[更新完成]](https://img-blog.csdnimg.cn/direct/7cc30786de694d1296c865ad426df1b8.png)

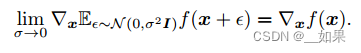




















![[Python学习篇] Python模块和包](https://i-blog.csdnimg.cn/direct/5d2220e96d09450b981b6ac6780087b1.png)














