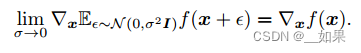不像视觉领域,在Bert出现之前的nlp领域还没有一个深的网络,使得能在大数据集上训练一个深的神经网络,并应用到很多nlp的任务上
Abstract
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al, 2018a; Radford et al, 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
翻译:
我们引入了一种新的语言表示模型BERT,它代表来自transformer的双向编码器表示。与最近的语言表示模型不同(Peters等人,2018a;Radford等人,2018),BERT旨在通过在所有层中对左右上下文进行联合条件反射,从未标记的文本中预训练深度双向表示。因此,预训练的BERT模型可以通过一个额外的输出层进行微调,从而为广泛的任务(如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改。
总结:
提了与gpt和ELMo的区别——gpt单向,BERT双向;ELMo是RNN架构,BERT是transformer架构,使得BERT微调更简单且有效
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
翻译:
BERT在概念上简单,经验上强大。它在11个自然语言处理任务上获得了新的最先进的结果,包括将GLUE得分提高到80.5%(绝对提高7.7%),将多项准确性提高到86.7%(绝对提高4.6%),将SQuAD v1.1问答测试F1提高到93.2(绝对提高1.5分)和SQuAD v2.0测试F1提高到83.1(绝对提高5.1分)。
Introduction
Language model pre-training has been shown to be effective for improving many natural language processing tasks (Dai and Le, 2015; Peters et al, 2018a; Radford et al, 2018; Howard and Ruder, 2018). These include sentence-level tasks such as natural language inference (Bowman et al, 2015; Williams et al, 2018) and paraphrasing (Dolan and Brockett, 2005), which aim to predict the relationships between sentences by analyzing them holistically, as well as token-level tasks such as named entity recognition and question answering, where models are required to produce fine-grained output at the token level (Tjong Kim Sang and De Meulder, 2003; Rajpurkar et al, 2016).
翻译:
语言模型预训练已被证明对改善许多自然语言处理任务是有效的(Dai and Le, 2015;Peters等人,2018a;Radford et al, 2018;Howard and Ruder, 2018)。其中包括句子级任务,如自然语言推理(Bowman et al, 2015;Williams等人,2018)和释义(Dolan和Brockett, 2005),其目的是通过整体分析来预测句子之间的关系,以及词语级任务,如命名实体识别和问答,其中需要模型在标记级产生细粒度输出(Tjong Kim Sang和De Meulder, 2003;Rajpurkar et al, 2016)。
总结:
其实在BERT之前,nlp的预训练想法就比较成熟了,只是BERT让预训练在nlp火出圈了
There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning. The feature-based approach, such as ELMo (Peters et al, 2018a), uses task-specific architectures that include the pre-trained representations as additional features. The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) (Radford et al, 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pretrained parameters. The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations.
翻译:
将预训练的语言表示应用于下游任务有两种现有策略:基于特征和微调。基于特征的方法,如ELMo (Peters等人,2018a),使用特定于任务的架构,其中包括预训练的表示作为附加特征。微调方法,如生成式预训练转换器(OpenAI GPT) (Radford等人,2018),引入了最小的任务特定参数,并通过简单地微调所有预训练参数来对下游任务进行训练。这两种方法在预训练过程中具有相同的目标函数,它们使用单向语言模型来学习一般的语言表示。
总结:
以ELMo为代表的基于特征的预训练模型:将预训练的表示作为额外特征输入网络,辅助训练
以GPT为代表的基于微调的预训练模型:权重根据新数据再训练
We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches. The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-toright architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al, 2017). Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying finetuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
翻译:
我们认为当前的技术限制了预训练表征的力量,特别是对于微调方法。主要的限制是标准语言模型是单向的,这限制了在预训练期间可以使用的体系结构的选择。例如,在OpenAI GPT中,作者使用左-右架构,其中每个token只能关注Transformer自注意力层中的前一个token(Vaswani et al, 2017)。这种限制对于句子级任务来说是次优的,并且在将基于调优的方法应用于诸如问答之类的token级任务时可能非常有害,在这些任务中,结合两个方向的上下文是至关重要的。
总结:
认为单向限制了模型能力,不管是在句子级还是单词级任务上,双向看句子也理应是合理的
In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers.
BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective, inspired by the Cloze task (Taylor, 1953). The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-toright language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer. In addition to the masked language model, we also use a “next sentence prediction” task that jointly pretrains text-pair representations.
翻译:
在本文中,我们通过提出BERT:来自transformer的双向编码器表示来改进基于微调的方法。
BERT通过使用受完形填空任务(Taylor, 1953)启发的“掩模语言模型”(MLM)预训练目标,缓解了前面提到的单向性约束。屏蔽语言模型随机屏蔽输入中的一些标记,目标是仅根据其上下文预测被屏蔽词的原始词汇表id。与左右语言模型预训练不同,MLM目标使表示能够融合左右上下文,这允许我们预训练深度双向Transformer。除了屏蔽语言模型,我们还使用了“下一个句子预测”任务,联合预训练文本对表示。
总结:
单词级上:利用掩码遮住单词,让模型双向看完之后做完形填空
句子级上:随机挑两个句子,让模型判断这两个句子是连着的还是随机抽取的
The contributions of our paper are as follows:
We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.
• We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.
• BERT advances the state of the art for eleven NLP tasks. The code and pre-trained models are available at https://github.com/ google-research/bert.
翻译:
本文的贡献如下:
我们证明了双向预训练对语言表征的重要性。与Radford等人(2018)使用单向语言模型进行预训练不同,BERT使用屏蔽语言模型来实现预训练的深度双向表示。这也与Peters等人(2018a)形成对比,后者使用独立训练的从左到右和从右到左的LMs的浅连接。
我们表明,预训练的表示减少了对许多重型工程任务特定架构的需求。BERT是第一个基于调优的表示模型,它在大量句子级和单词级任务上实现了最先进的性能,优于许多特定于任务的架构。
BERT在11个NLP任务中推进了最先进的技术。代码和预训练模型可在https://github.com/ google-research/bert上获得。
总结:
展示了双向信息的重要性;是第一个达到SOTA的基于微调的模型
Related Work
Unsupervised Feature-based Approaches
Learning widely applicable representations of words has been an active area of research for decades, including non-neural and neural methods. Pre-trained word embeddings are an integral part of modern NLP systems, offering significant improvements over embeddings learned from scratch. To pretrain word embedding vectors, left-to-right language modeling objectives have been used, as well as objectives to discriminate correct from incorrect words in left and right context.
These approaches have been generalized to coarser granularities, such as sentence embeddings or paragraph embeddings. To train sentence representations, prior work has used objectives to rank candidate next sentences, left-to-right generation of next sentence words given a representation of the previous sentence, or denoising autoencoder derived objectives.
ELMo and its predecessor generalize traditional word embedding research along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual representation of each token is the concatenation of the left-to-right and right-to-left representations.
When integrating contextual word embeddings with existing task-specific architectures, ELMo advances the state of the art for several major NLP benchmarks including question answering, sentiment analysis, and named entity recognition. Melamud et al proposed learning contextual representations through a task to predict a single word from both left and right context using LSTMs. Similar to ELMo, their model is feature-based and not deeply bidirectional. Fedus et al shows that the cloze task can be used to improve the robustness of text generation models.
翻译:
几十年来,学习广泛适用的单词表示一直是一个活跃的研究领域,包括非神经和神经方法。预训练词嵌入是现代自然语言处理系统的一个组成部分,与从零开始学习的嵌入相比,它提供了显著的改进。为了预训练词嵌入向量,使用了从左到右的语言建模目标,以及在左右上下文中区分正确和不正确单词的目标。
这些方法已经被推广到更粗的粒度,如句子嵌入或段落嵌入。为了训练句子表示,之前的工作使用目标对候选下一个句子进行排序,根据前一个句子的表示从左到右生成下一个句子单词,或者去噪自动编码器派生的目标。
ELMo及其前身将传统的词嵌入研究推广到了一个不同的维度。他们从从左到右和从右到左的语言模型中提取上下文敏感的特征。每个标记的上下文表示是从左到右和从右到左表示的连接。
当将上下文词嵌入与现有的任务特定架构集成在一起时,ELMo在几个主要的NLP基准测试(包括问答、情感分析和命名实体识别)中提升了技术水平。Melamud等人提出通过使用lstm从左右上下文中预测单个单词的任务来学习上下文表示。与ELMo类似,他们的模型是基于特征的,而不是深度双向的。Fedus等人表明,完形任务可以用来提高文本生成模型的鲁棒性。
总结:
介绍之前的基于特征的无监督的一些工作
Unsupervised Fine-tuning Approaches
As with the feature-based approaches, the first works in this direction only pre-trained word embedding parameters from unlabeled text.
More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task. The advantage of these approaches is that few parameters need to be learned from scratch. At least partly due to this advantage, OpenAI GPT achieved previously state-of-the-art results on many sentencelevel tasks from the GLUE benchmark. Left-to-right language modeling and auto-encoder objectives have been used for pre-training such models.
翻译:
与基于特征的方法一样,第一种方法只从未标记的文本中预训练单词嵌入参数。
最近,产生上下文token表示的句子或文档编码器已经从未标记的文本中进行了预训练,并针对监督的下游任务进行了微调。这些方法的优点是很少有参数需要从头学习。至少部分由于这一优势,OpenAI GPT在GLUE基准测试的许多句子级任务上取得了以前最先进的结果。从左到右的语言建模和自动编码器目标已经被用于预训练这样的模型。
总结:
介绍之前的基于微调的无监督的一些工作
Transfer Learning from Supervised Data
There has also been work showing effective transfer from supervised tasks with large datasets, such as natural language inference (Conneau et al, 2017) and machine translation (McCann et al, 2017). Computer vision research has also demonstrated the importance of transfer learning from large pre-trained models, where an effective recipe is to fine-tune models pre-trained with ImageNet (Deng et al, 2009; Yosinski et al, 2014).
翻译:
也有研究表明,大型数据集的监督任务可以有效转移,例如自然语言推理(Conneau等人,2017)和机器翻译(McCann等人,2017)。计算机视觉研究也证明了从大型预训练模型迁移学习的重要性,其中一个有效的方法是对使用ImageNet预训练的模型进行微调(Deng et al ., 2009;Yosinski et al, 2014)。
总结:
在有标号的数据集上预训练后放到其他下游任务中的效果并不理想,一方面是可能两个任务差别比较大(与CV领域比较),另一方面可能是数据量还不够大
BERT之后的一些工作证明了,nlp中在没有标号的大量数据集上训练成的模型比有标号的相对小点的数据集上训练的效果更好
BERT
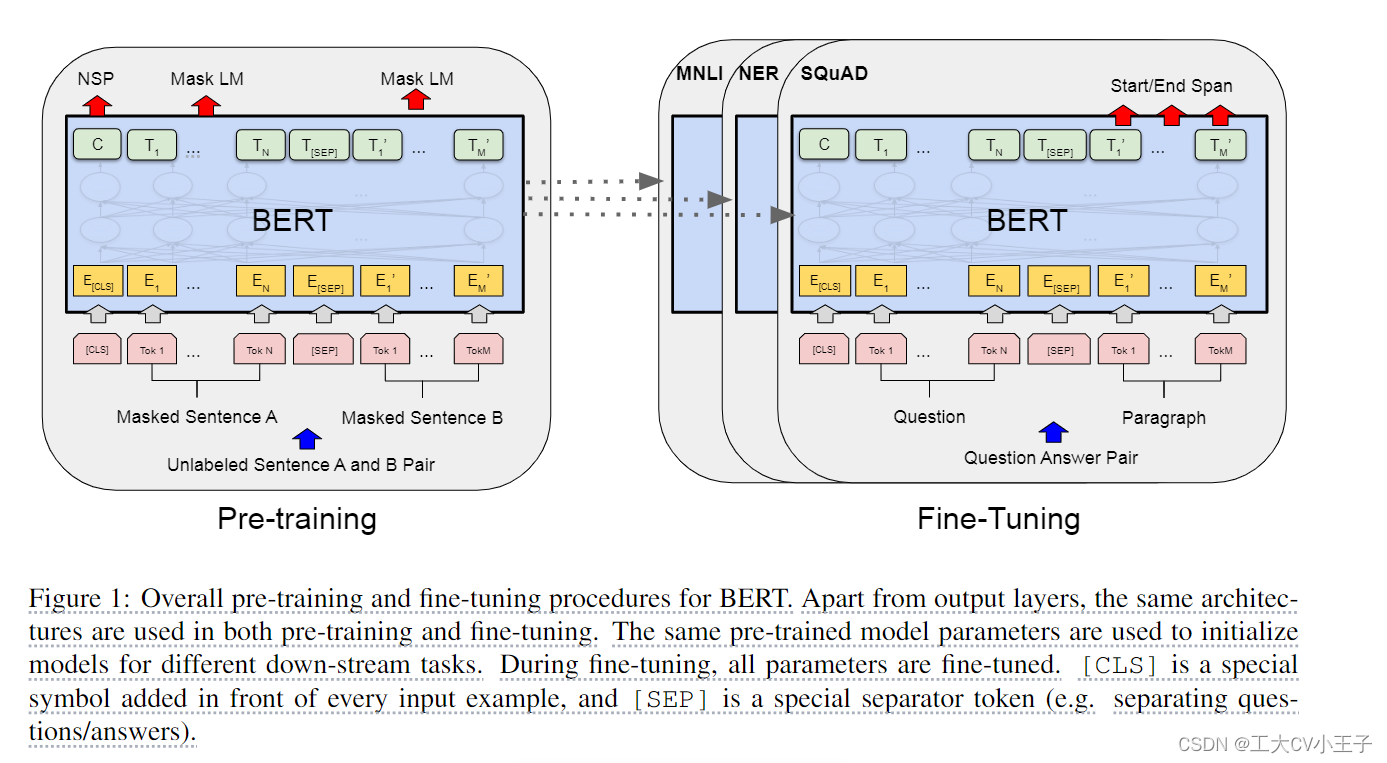
We introduce BERT and its detailed implementation in this section. There are two steps in our framework: pre-training and fine-tuning. During pre-training, the model is trained on unlabeled data over different pre-training tasks. For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters. The question-answering example in Figure 1 will serve as a running example for this section.
翻译:
我们将在本节中介绍BERT及其详细实现。在我们的框架中有两个步骤:预训练和微调。在预训练过程中,模型在不同的预训练任务上对未标记数据进行训练。对于微调,首先使用预训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。图1中的问答示例将作为本节的运行示例
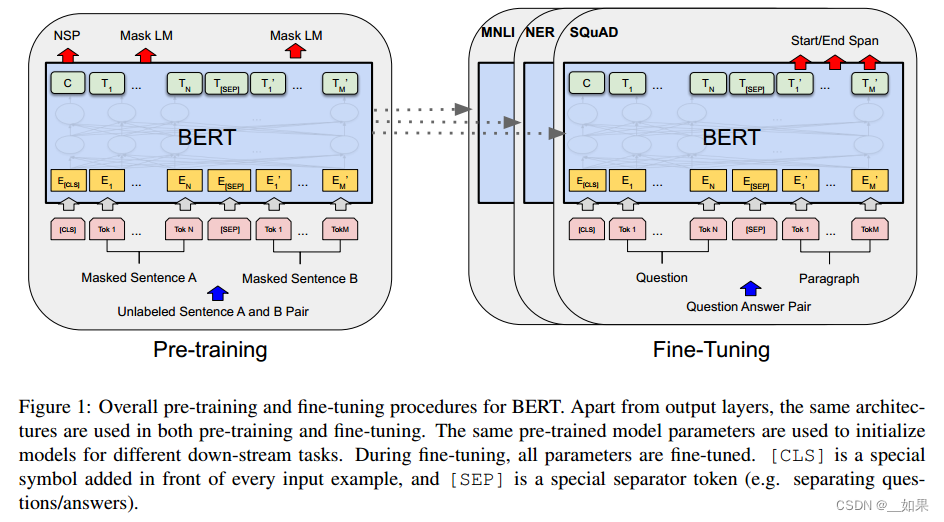
预训练时输入没有标号的句子对,微调时利用每个任务的有标号的数据训练
A distinctive feature of BERT is its unified architecture across different tasks. There is minimal difference between the pre-trained architecture and the final downstream architecture.
翻译:
BERT的一个显著特征是其跨不同任务的统一架构。预训练的体系结构和最终的下游体系结构之间的差别很小。
Model Architecture
BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al (2017) and released in the tensor2tensor library.1 Because the use of Transformers has become common and our implementation is almost identical to the original, we will omit an exhaustive background description of the model architecture and refer readers to Vaswani et al (2017) as well as excellent guides such as “The Annotated Transformer”.
翻译:
BERT的模型架构是一个多层双向transformer编码器,基于Vaswani等人(2017)描述的原始实现,并在tensor2tensor库中发布由于Transformer的使用已经变得普遍,并且我们的实现几乎与原始版本相同,因此我们将省略对模型体系结构的详尽背景描述,并将读者推荐给Vaswani等人(2017)以及优秀的指南,例如“注释的Transformer”。
总结:
相较于transformer,模型架构与代码几乎没有改动
In this work, we denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A.
3 We primarily report results on two model sizes: BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
BERTBASE was chosen to have the same model size as OpenAI GPT for comparison purposes.
Critically, however, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
翻译:
在这项工作中,我们表示层数(即transformer块)为L,隐藏大小为H,自注意头的数量为A。
我们主要报告了两种模型尺寸的结果:BERTBASE (L=12, H=768, A=12, Total Parameters=110M)和BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)。
为了进行比较,选择BERTBASE与OpenAI GPT具有相同的模型大小。
然而,关键的是,BERT Transformer使用双向自注意力,而GPT Transformer使用约束自注意力,其中每个token只能关注其左侧的上下文。
总结:
BERT的模型复杂度与层数L是线性关系,与宽度H是平方关系,因此BERT Large层数变成之前的两倍,宽度的平方也要变成之前的两倍
Input/Output Representations
To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., h Question, Answeri) in one token sequence.
Throughout this work, a “sentence” can be an arbitrary span of contiguous text, rather than an actual linguistic sentence. A “sequence” refers to the input token sequence to BERT, which may be a single sentence or two sentences packed together.
翻译:
为了使BERT处理各种下游任务,我们的输入表示能够在一个token序列中明确地表示单个句子和一对句子(例如,h Question, Answeri)。
在整个工作中,一个“句子”可以是一个连续文本的任意跨度,而不是一个实际的语言句子。“序列”指的是BERT的输入token序列,它可以是一个句子或两个句子组合在一起。
总结:
BERT只有一个编码器,所以为了能处理两个句子,需要把两个句子变成一个序列
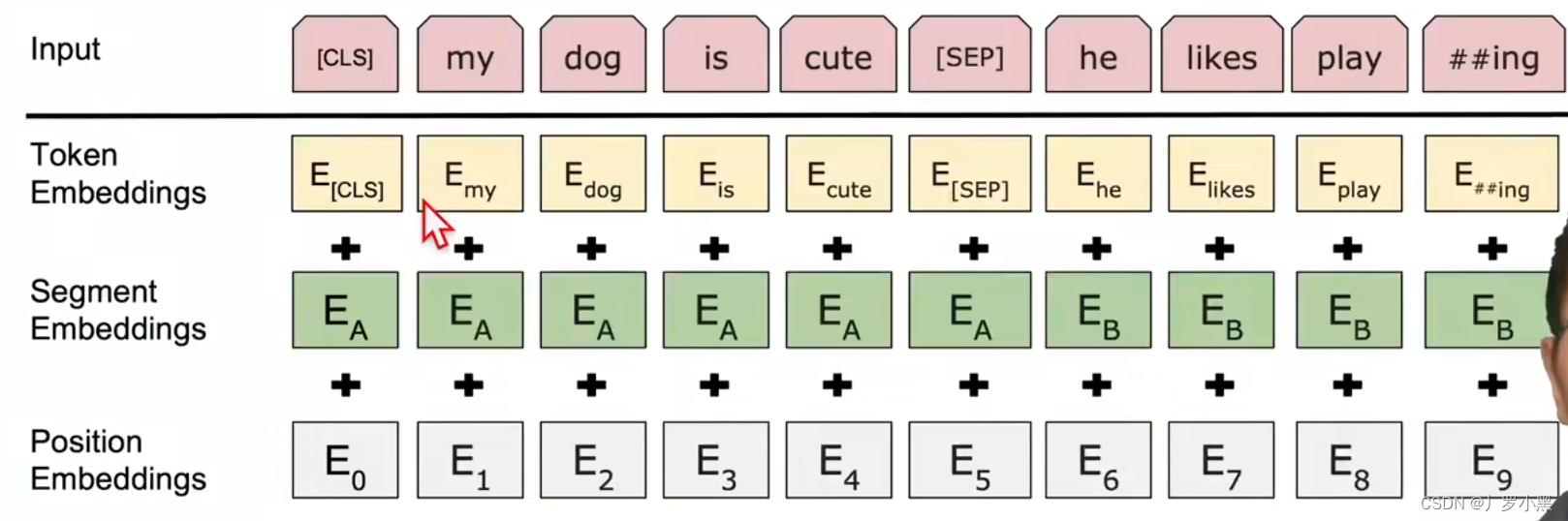
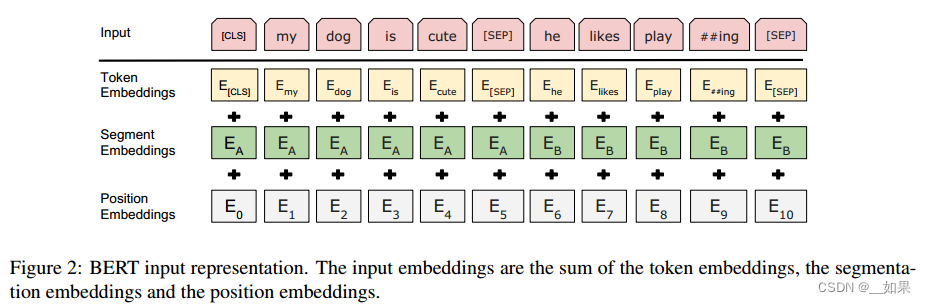
We use WordPiece embeddings (Wu et al, 2016) with a 30,000 token vocabulary. The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B. As shown in Figure 1, we denote input embedding as E, the final hidden vector of the special [CLS] token as C 2 R H, and the final hidden vector for the i th input token as Ti 2 R H.
For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. A visualization of this construction can be seen in Figure 2.
翻译:
我们使用WordPiece嵌入(Wu et al ., 2016)和30,000个标记词汇表。每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此token对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被打包成一个单一的序列。我们用两种方法区分句子。首先,我们用一个特殊的token([SEP])将它们分开。其次,我们为每个标记添加一个学习嵌入,表明它是属于句子a还是句子b。如图1所示,我们将输入嵌入表示为E,特殊[CLS]标记的最终隐藏向量表示为c2rh,第i个输入标记的最终隐藏向量表示为Ti 2rh。
对于给定的标记,其输入表示是通过将相应的token、段和位置嵌入相加来构建的。图2显示了该结构的可视化。
总结:
wordpiece:假设按照空格切词,一个词作为一个token,因为数据量较大导致词典特别大,导致计算量过大;如果一个词在整个序列中出现的概率不大,就把这个词切开看它的子序列,如果它的某个子序列是一个词根且出现概率较大,则只保留这个子序列。这样就把相对长的一个词切成了很多段且这些片段经常出现,这样就能用小词典表示大文本
序列的第一次词永远是[CLS],BERT希望[CLS]最后的输出代表整个序列的信息。因为BERT沿用了transformer的自注意力机制,所以即使放在第一个也能看见整个序列
为了把句子从序列中分开:每个句子的最后加一个[SEP]或学一个嵌入层区分句子是第一个还是第二个
每个词进入BERT的向量表示:词本身的embedding+在哪一个句子的embedding+在句子位置的embedding
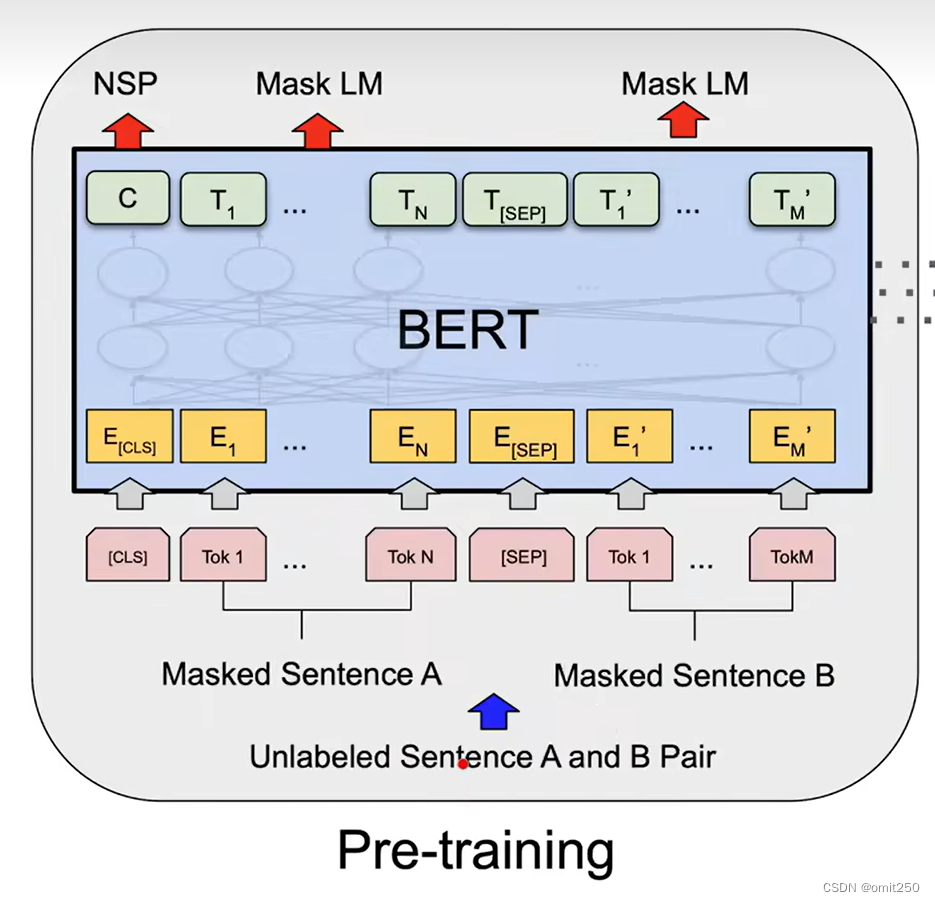
Pre-training BERT
Unlike Peters et al (2018a) and Radford et al
(2018), we do not use traditional left-to-right or right-to-left language models to pre-train BERT.
Instead, we pre-train BERT using two unsupervised tasks, described in this section. This step is presented in the left part of Figure 1.
翻译:
与Peters等人(2018a)和Radford等人不同
(2018),我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。
相反,我们使用本节中描述的两个无监督任务来预训练BERT。此步骤如图1的左侧所示。
Task #1: Masked LM
Intuitively, it is reasonable to believe that a deep bidirectional model is strictly more powerful than either a left-to-right model or the shallow concatenation of a left-toright and a right-to-left model. Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself”, and the model could trivially predict the target word in a multi-layered context.
翻译:
直观地说,我们有理由相信,深度双向模型严格地比从左到右的模型或从左到右和从右到左的浅连接模型更强大。不幸的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件反射将允许每个单词间接“看到自己”,并且该模型可以在多层上下文中轻松预测目标单词。
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. We refer to this procedure as a “masked LM” (MLM), although it is often referred to as a Cloze task in the literature (Taylor, 1953). In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM. In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random. In contrast to denoising auto-encoders (Vincent et al, 2008), we only predict the masked words rather than reconstructing the entire input.
翻译:
为了训练深度双向表示,我们只是随机屏蔽一定比例的输入token,然后预测这些被屏蔽的token。我们将这一过程称为“掩码LM”(MLM),尽管在文献中它通常被称为完形填空任务(Taylor, 1953)。在这种情况下,与掩码token相对应的最终隐藏向量被输入到词汇表上的输出softmax中,就像在标准LM中一样。在我们所有的实验中,我们随机屏蔽了每个序列中15%的WordPiece token。与去噪自编码器(Vincent et al ., 2008)相比,我们只预测被屏蔽的单词,而不是重建整个输入。
Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token. The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Then, Ti will be used to predict the original token with cross entropy loss. We compare variations of this procedure in Appendix C.2.
翻译:
虽然这允许我们获得双向预训练模型,但缺点是我们正在创建预训练和微调之间的不匹配,因为[MASK]token在微调期间没有出现。为了减轻这种情况,我们并不总是用实际的[MASK]token替换“被屏蔽”的单词。训练数据生成器随机选择15%的标记位置进行预测。如果选择了第i个token,我们用(1)80%的时间使用[MASK]token(2)10%的时间使用随机token(3)10%的时间使用未更改的第i个token替换第i个token。然后,利用Ti来预测具有交叉熵损失的原始token。我们在附录C.2中比较了这个过程的变化。
总结:
有个问题是在做掩码时把词元替换成一个特殊的token叫作[Mask],但是在微调时是没有[Mask]的,导致预训练与微调时见到的数据不太一样
最后一种做法可能是对应微调时见不到[Mask]的情况
Task #2: Next Sentence Prediction (NSP)
Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling. In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus. Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext). As we show in Figure 1, C is used for next sentence prediction (NSP).5 Despite its simplicity, we demonstrate in Section 5.1 that pre-training towards this task is very beneficial to both QA and NLI.
翻译:
许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于理解两个句子之间的关系,这是语言建模无法直接捕获的。为了训练一个理解句子关系的模型,我们对一个二值化的下一个句子预测任务进行了预训练,该任务可以从任何单语语料库中轻松生成。具体来说,当为每个预训练示例选择句子A和B时,50%的时间B是A之后的下一个句子(标记为IsNext), 50%的时间B是语料库中的随机句子(标记为NotNext)。如图1所示,C用于下一个句子预测(NSP)尽管它很简单,但我们在5.1节中演示了针对该任务的预训练对QA和NLI都非常有益。
总结:
50%正例,50%负例

这里的flightless是不会飞的意思,但是这个词不常见,所以wordpiece用##把它切开了
The NSP task is closely related to representationlearning objectives used in Jernite et al (2017) and Logeswaran and Lee (2018). However, in prior work, only sentence embeddings are transferred to down-stream tasks, where BERT transfers all parameters to initialize end-task model parameters.
翻译:
NSP任务与Jernite等人(2017)和Logeswaran和Lee(2018)中使用的表征学习目标密切相关。然而,在之前的工作中,只有句子嵌入被转移到下游任务中,BERT将所有参数转移到下游任务中以初始化任务端模型参数。
Pre-training data
The pre-training procedure largely follows the existing literature on language model pre-training. For the pre-training corpus we use the BooksCorpus (800M words) (Zhu et al, 2015) and English Wikipedia (2,500M words).
For Wikipedia we extract only the text passages and ignore lists, tables, and headers. It is critical to use a document-level corpus rather than a shuffled sentence-level corpus such as the Billion Word Benchmark (Chelba et al, 2013) in order to extract long contiguous sequences.
翻译:
预训练过程在很大程度上遵循了已有的语言模型预训练文献。对于预训练语料库,我们使用BooksCorpus(800万字)(Zhu et al ., 2015)和英语维基百科(2500万字)。
对于维基百科,我们只提取文本段落,而忽略列表、表格和标题。为了提取长连续序列,使用文档级语料库而不是像十亿词基准(Chelba et al, 2013)这样的打乱句子级语料库是至关重要的。
总结:
用文本数据而非随机打乱的句子效果会好
Fine-tuning BERT
Fine-tuning is straightforward since the selfattention mechanism in the Transformer allows BERT to model many downstream tasks— whether they involve single text or text pairs—by swapping out the appropriate inputs and outputs.
For applications involving text pairs, a common pattern is to independently encode text pairs before applying bidirectional cross attention, such as Parikh et al (2016); Seo et al (2017). BERT instead uses the self-attention mechanism to unify these two stages, as encoding a concatenated text pair with self-attention effectively includes bidirectional cross attention between two sentences.
翻译:
微调是直接的,因为Transformer中的自注意机制允许BERT对许多下游任务建模——无论它们涉及单个文本还是文本对——通过交换适当的输入和输出。
对于涉及文本对的应用程序,常见的模式是在应用双向交叉注意之前对文本对进行独立编码,如Parikh等人(2016);Seo等人(2017)。BERT使用自注意机制来统一这两个阶段,因为用自注意编码一个连接的文本对有效地包括两个句子之间的双向交叉注意。
总结:
BERT与Encoder-Decoder框架的区别:BERT能双向看,但是Encoder不能看到Decoder中的东西;BERT做不了机器翻译
For each task, we simply plug in the taskspecific inputs and outputs into BERT and finetune all the parameters end-to-end. At the input, sentence A and sentence B from pre-training are analogous to (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, and (4) a degenerate text-? pair in text classification or sequence tagging. At the output, the token representations are fed into an output layer for tokenlevel tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
翻译:
对于每个任务,我们只需将特定于任务的输入和输出插入到BERT中,并对所有参数进行端到端的微调。在输入端,来自预训练的句子A和句子B类似于:(1)释义中的句子对,(2)蕴涵中的假设-前提对,(3)问答中的问题-段落对,以及(4)退化的文本-?配对文本分类或序列标记。在输出端,token表示被输入输出层用于token级任务,如序列标记或问题回答,而[CLS]表示被输入输出层用于分类,如蕴意或情感分析。
总结:
根据下游任务设计输入输出,模型不需要怎么变,关键是把输入改成需要的句子对
Compared to pre-training, fine-tuning is relatively inexpensive. All of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU, starting from the exact same pre-trained model.7 We describe the task-specific details in the corresponding subsections of Section 4. More details can be found in Appendix A.5.
翻译:
与预训练相比,微调相对便宜。从完全相同的预训练模型开始,论文中的所有结果可以在单个Cloud TPU上最多1小时内复制,或者在GPU上复制几个小时我们将在第4节的相应子节中描述特定于任务的详细信息。详情见附录A.5。
Experiments
GLUE
句子层面的任务,BERT把[CLS]最后的向量拿出来,学习一个输出层W,放进去最后softmax得到标号
 SQuAD v1.1
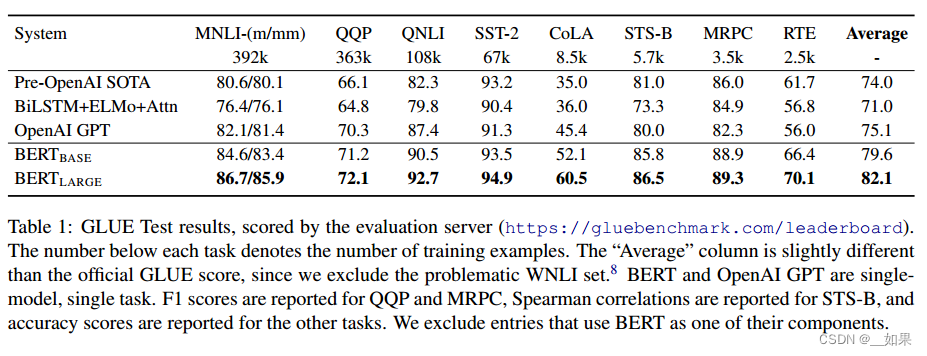
SQuAD v1.1
QA任务:判断词元是不是答案的开头或结尾,学两个向量S和E,分布对应答案开始的概率和答案结束的概率。具体来说就是用第一句话中的每个词元与第二句话中的每个词语相乘再softmax
SWAG
判断两个句子之间的关系
When fine-tuning on the SWAG dataset, we construct four input sequences, each containing the concatenation of the given sentence (sentence A) and a possible continuation (sentence B). The only task-specific parameters introduced is a vector whose dot product with the [CLS] token representation C denotes a score for each choice which is normalized with a softmax layer.
翻译:
当对SWAG数据集进行微调时,我们构建了四个输入序列,每个序列包含给定句子(句子A)和可能的延续(句子B)的连接。引入的唯一特定于任务的参数是一个向量,其与[CLS]标记表示C的点积表示每个选择的分数,该分数用softmax层进行规范化。
Ablation Studies
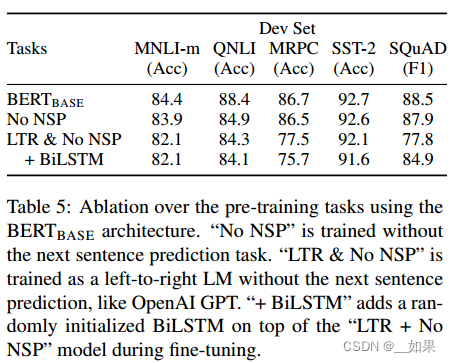
假设去掉下一个句子的预测;假设从左到右看;假设加上一个双向的LSTM
Effect of Model Size
It has long been known that increasing the model size will lead to continual improvements on large-scale tasks such as machine translation and language modeling, which is demonstrated by the LM perplexity of held-out training data shown in Table 6. However, we believe that this is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained. Peters et al (2018b) presented mixed results on the downstream task impact of increasing the pre-trained bi-LM size from two to four layers and Melamud et al (2016) mentioned in passing that increasing hidden dimension size from 200 to 600 helped, but increasing further to 1,000 did not bring further improvements. Both of these prior works used a featurebased approach — we hypothesize that when the model is fine-tuned directly on the downstream tasks and uses only a very small number of randomly initialized additional parameters, the taskspecific models can benefit from the larger, more expressive pre-trained representations even when downstream task data is very small.
翻译:
人们早就知道,增加模型大小将导致机器翻译和语言建模等大规模任务的持续改进,表6所示的训练数据的LM困惑度证明了这一点。然而,我们相信这是第一个令人信服地证明扩展到极端模型尺寸也会导致非常小规模任务的巨大改进的工作,前提是模型已经得到充分的预训练。Peters等人(2018b)对将预训练的bi-LM大小从两层增加到四层的下游任务影响给出了不同的结果,Melamud等人(2016)顺便提到,将隐藏维度大小从200增加到600有所帮助,但进一步增加到1000并没有带来进一步的改善。这两项先前的工作都使用了基于特征的方法——我们假设,当模型直接在下游任务上进行微调,并且只使用非常少量的随机初始化附加参数时,特定于任务的模型可以从更大、更有表现力的预训练表征中受益,即使下游任务数据非常小。
Feature-based Approach with BERT
假设不用BERT做微调,而是把BERT的特征作为静态特征输入进去会怎么样
结果表明效果没有微调那么好
Conclusion
Recent empirical improvements due to transfer learning with language models have demonstrated that rich, unsupervised pre-training is an integral part of many language understanding systems. In particular, these results enable even low-resource tasks to benefit from deep unidirectional architectures. Our major contribution is further generalizing these findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
翻译:
最近由语言模型迁移学习的经验改进表明,丰富的无监督预训练是许多语言理解系统的组成部分。特别是,这些结果使低资源任务也能从深度单向架构中受益。我们的主要贡献是进一步将这些发现推广到深度双向架构,允许相同的预训练模型成功地处理广泛的NLP任务。