1、数据结构的一个操作序列中 所执行的 所有操作的平均时间,来评估该操作的代价。摊还分析 不同于平均情况分析,它并不涉及概率,它可以保证最坏情况下每个操作的平均性能
它是一种平均情况下的 性能分析方法,用于 评估一系列操作的平均代价,而不是 每个单独操作的最坏情况代价
2、摊还分析中 赋予对象的费用 仅仅是用来分析而已,不需要 也不应该出现在程序中。做摊还分析,通常可以获得 对某种特定数据的认识
1、聚合分析
1、利用聚合分析,证明对所有 n,一个n个操作的序列 最坏情况下 需花费的总时间为 T(n)。因此,在最坏情况下, 每个操作的平均代价,或摊还代价为 T(n)/n。此摊还代价 是适用于每个操作的,即使序列中有多种类型的操作也是如此
1.1 栈操作
1、两个基本的栈操作,时间复杂度均为 O(1): PUSH(S, x),POP(S)
由于两个操作都需要 O(1) 时间,假定其代价 均为 O(1)。因此一个n个 PUSH 和 POP 操作的序列的总代价为 n,n 个操作的实际运行时间为 Θ(n)
增加一个新的操作 MULTIPOP(S, k),它删除栈 S 栈顶的 k 个对象,如果栈中对象数少于 k,则将整个栈的内容都弹出。假定 k 是正整数,否则 MULTIPOP 会保持栈不变
MULTIPOP(S, k)
1 while not STACK-EMPTY(S) and k > 0
2 POP(S)
3 k = k - 1
2、在一个包含 s 个对象的栈上执行 MULTIPOP(S, k) 操作的运行时间 是与实际执行的POP操作的次数呈线性关系的,用 PUSH 和 POP 操作的抽象代价 1 来分析描述 MULTIPOP 的代价。while 循环执行的次数等于从栈中弹出的对象数,等于 min(s, k)。每个循环步骤用了一次 POP (第2行)。因此,MULTIPOP 的总代价为 min(s, k),而真正的运行时间为此代价的线性函数
一个由 n 个 PUSH、POP 和 MULTIPOP 组成的操作序列 在一个空栈上的执行情况。序列中 一个 MULTIPOP 操作的最坏情况代价为 O(n),因为栈的大小 最大为 n。因此,任意一个栈操作的最坏情况时间为 O(n),从而 一个 n 个操作的序列的最坏情况代价为 O(n2)
通过单独分析每个操作的最坏情况代价 得到的操作序列的最坏情况时间 O(n²),并不是一个确界
3、通过使用聚合分析,考虑整个序列的 n 个操作,可以得到更好的上界。虽然一个单独的 MULTIPOP 操作可能代价很高,但在一个空栈上执行 n 个 PUSH、POP 和 MULTIPOP 的操作序列,代价至多是 2n
当一个对象压入栈后,至多将其弹出一次。因此,对一个非空的栈,可以执行的 POP 操作的次数 (包括 MULTIPOP 中调用 POP 的次数) 最多与 PUSH 操作的次数相当,即最多 n 次
对任意的 n 值,任意一个由 n 个 PUSH、POP 和 MULTIPOP 组成的操作序列,最多花费 O(n) 的时间。一个操作的平均时间为 O(n) / n = O(1)。在聚合分析中,将每个操作的摊还代价 假定为平均代价。因此,在此例中,所有三种栈操作的摊还代价都是O(1)
4、已经证明一个栈操作的平均代价,也就是平均运行时间为 O(1),但并未使用概率分析。实际上得出的 是一个 n 个操作的序列的最坏情况总运行时间 O(n),再除以n得到了 每个操作的平均代价, 或者说摊还代价
1.2 二进制计数器递增
1、一个 k 位二进制计数器递增的问题,计数器的初值为 0。用一个数组 A[0…k-1] 作为计数器,其中 A.length = k。计数器中保存的二进制值为 x 时,x 的最低位保存在 A[0] 中,而最高位保存在 A[k-1] 里,因此 
将1加到计数器的值上
INCREMENT(A)
1 i = 0
2 while i < A.length and A[i] == 1
3 A[i] = 0
4 i = i + 1
5 if i < A.length
6 A[i] = 1
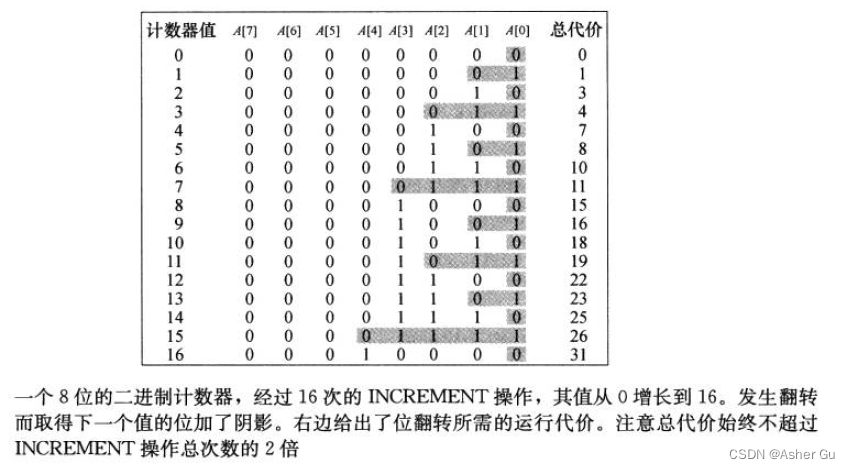
显示了将一个二进制计数器递增16次的情况,希望 1 加在第i位上。如果A[i] = 1,那么加 1 操作会将第 i 位翻转为0,并产生一个进位
与 关于栈的例子 类似,对此算法的运行时间 进行粗略的分析会得到一个正确但不紧的界。最坏情况是 INCREMENT 执行一次花费 Θ(k) 时间,最坏情况是 当数组 A 所有位都为 1 时发生。因此,对初值为 0 的计数器 执行 n 个 INCREMENT 操作 最坏情况下花费 Θ(nk) 时间
对于 n 个 INCREMENT 操作组成的序列,可以得到一个更紧的界——最坏情况下代价为 O(n),因为 不可能每次 INCREMENT 操作都翻转所有的二进制位
每次调用 INCREMENT 时 A[0] 确实都会翻转。而下一位 A[1],则只是每两次调用 翻转一次,这样,对于一个初值为 0 的计数器执行 一个 n 个 INCREMENT 操作的序列,只会使 A[1] 翻转 ⌊n/2⌋ 次。类似地,A[2] 每4次调用才翻转一次,即执行 一个 n 个 INCREMENT 操作的序列 的过程中 翻转 ⌊n/4⌋ 次。对一个初值为0的计数器,在执行一个由 n 个 INCREMENT 操作组成的序列的过程中,A[i] 翻转的次数为 ⌊n/2i⌋ 次 (i = 0, 1, …, k-1)。在执行 INCREMENT 序列的过程中 进行的翻转操作的总数为
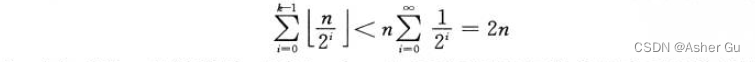
对一个初值为 0 的计数器,执行 一个 n 个 INCREMENT 操作的序列的最坏情况时间为 O(n)。每个操作的平均时间,即摊还代价为 O(n)/n = O(1)
2、假定 对一个数据结构执行一个由 n 个操作组成的操作序列,当 i 严格为2的幂时,第 i 个操作的代价为 i,否则代价为1。使用聚合分析 确定每个操作的摊还代价
设 n 为任意值,第 i 次操作的代价为 c(i)
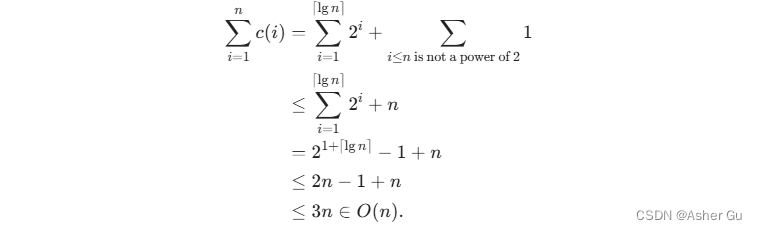
为了找到平均值,除以 n,每次操作的摊还成本是 O(1)
使用核算法计算 摊还分析
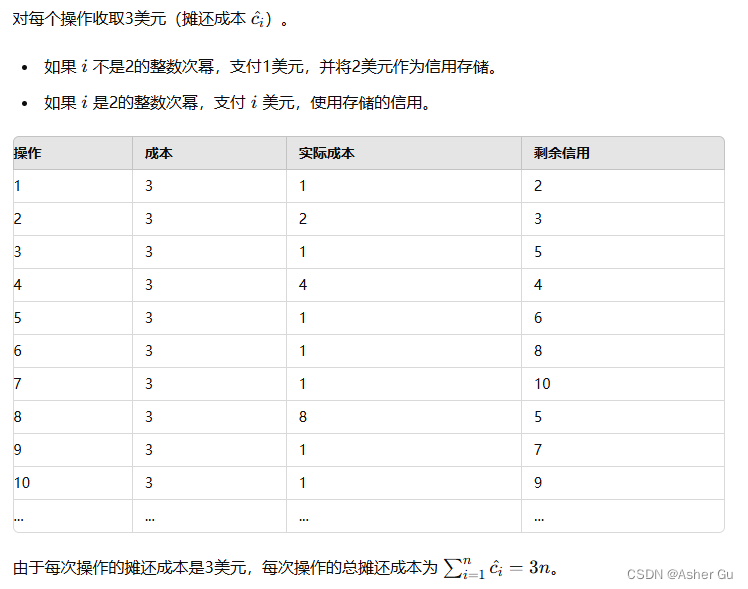
由上面知道 

使用势能法计算 摊还分析

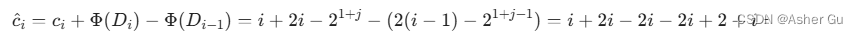 2
2
因此,每次操作的摊还成本是3
2、核算法
1、用 核算法(accounting method)进行摊还分析时,对不同操作 赋予不同费用,赋予某些操作的费用 可能多于或少于 其实际代价。将赋予一个操作的费用 称为它的摊还代价。当一个操作的摊还代价 超过其实际代价时, 将差额存入数据结构中的特定对象,存入的差额 称为信用
对于后续操作中摊还代价 小于 实际代价的情况,信用 可以用来支付差额。可以将一个操作的摊还代价 分解为其实际代价和信用(存入的或用掉的)。不同的操作 可能有不同的摊还代价
2、如果 有通过分析 摊还代价来证明 每个操作的平均代价的最坏情况很小,就应 确保操作序列的总摊还代价 给出了序列总真实代价的上界
如果 ci 表示第 i 个操作的 真实代价,用 ci 表示其摊还代价,则对任意n个操作的序列,要求:
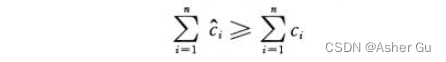
数据结构中 存储的信用 恰好等于 总摊还代价 与 总实际代价的差值,即
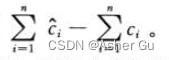
注意保持数据结构中的总信用永远为非负值
2.1 栈操作
1、PUSH:1
POP:1
MULTIPOP:min(k, s)
其中,k 是要提供给MULTIPOP的参数,s 是调用时栈的规模。为这些操作赋予如下 摊还代价:
PUSH:2
POP:0
MULTIPOP:0
将证明,通过 摊还代价 缴费,可以支付 任意的栈操作序列(的实际代价)。数据结构栈 和自助餐店里一叠盘子间的类比。当将一个盘子放在一叠盘子的最上面, 用 1 美元支付压栈操作的实际代价,将剩余的 1 美元存为信用(共缴费2美元)。在任何时间点,栈中的每个盘子 都存储了与之对应的 1 美元的信用
每个盘子存储的 1 美元, 实际上 是作为将来 它被弹出栈时代价的预付费。一个 POP 操作时,并不缴纳任何费用,而是使用存储在栈中的信用 来支付其实际代价
2、对于MULTIPOP操作,可以不额外付任何费用。为了弹出第一个盘子,将其1美元信用取出 支付此POP操作的实际代价。由于 栈中的每个盘子 都存有 1 美元的信用,而栈中的盘子数 始终是非负的,因此 可以保证信用值也总是非负的。因此,对于任意 n 个 PUSH、POP、MULTIPOP 操作组成的序列,总摊还代价为 总实际代价的上界。由于总摊还代价为 O(n),因此总实际代价也是
2.2 二进制计数器递增
1、分析在一个从 0 开始的二进制计数器上执行 INCREMENT 操作。此操作的运行时间 与翻转的位数成正比,因此对此例,可以将翻转的位数 作为操作的代价,再次使用 1 美元表示一个单位的代价(在此例中是翻转 1 位)
对一次置位操作,设其摊还代价为 2 美元。当进行置位时,用 1 美元支付置位操作的实际代价,并将另外 1 美元存为信用,用来支付 将来复位操作的代价。在任何时刻,计数器中 任何为1的位 都有1美元的信用,这样对于未来的复位操作,就无需缴任何费用
INCREMENT 过程至多置位一次(第6行),因此 其总摊还代价最多为2美元。计数器中1的个数 永远不会为负,因此,任何时刻 信用值 都是非负的。对于n个 INCREMENT 操作,总摊还代价为 O(n),为总实际代价的上界
3、势能法
1、势能法 进行摊还分析 并不将预付代价 表示为数据结构中特定对象的信用,而是表示为“势能” 或简称“势”,将势能释放 即可用来支付未来操作的代价。将势能与整个数据结构 而不是特定对象相关联
Di 为数据结构 Di-1 上执行第 i 个操作得到的结果数据结构。势函数 Φ 将每个数据结构 Di 映射到一个实数 Φ(Di),此值 即为关联的数据结构 Di 的势。第 i 个操作的摊还代价 ci^ 用势函数 Φ 定义为:
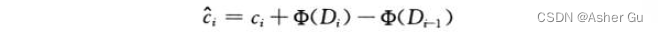
每个操作的摊还代价等于其实际代价加上此操作引起的势能变化,n个操作的总摊还代价为
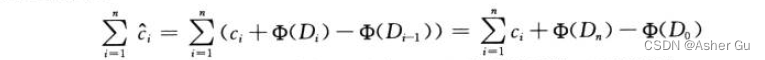
如果能定义一个势函数 Φ,使得 Φ(Dn) ≥ Φ(D0),则总摊还代价 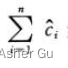 给出了总实际代价
给出了总实际代价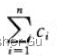 的一个上界
的一个上界
如果对所有 i,要求 Φ(Di) >= Φ(D0)
通常将 Φ(D0) 简单定义为0,然后说明 对于所有i,有 Φ(Di) ≥ 0
2、摊还代价 依赖于势函数的选择。不同的势函数 Φ 会产生不同的摊还代价,但摊还代价仍为实际代价的上界
3.1 栈操作
1、栈操作 PUSH、POP 和 MULTIPOP,将一个栈的势函数 定义为其中对象的数量。对于初始的空栈 D_0,有 Φ(D0) = 0。由于栈中对象数目 永远不可能为负,因此,第 i 步操作得到的栈 D_i 具有非负的势
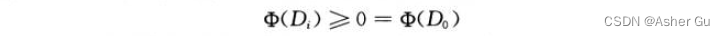
用 Φ 定义的 n 个操作的总摊还代价 即为实际代价的一个上界
PUSH 操作的摊还代价为:
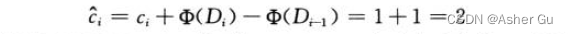
假设第 i 个操作是 MULTIPOP(S, k),将k’ = min(k, s) 个对象弹出栈。对象的实际代价为 k’,势差为:
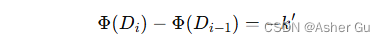
因此,MULTIPOP 的摊还代价为:(对象的实际代价为 k’)
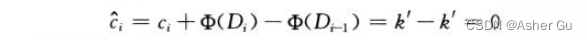
类似地,普通 POP 操作的摊还代价也为0
n个操作的总摊还代价为 O(n)。由于 已经证明了 Φ(Di) ≥ Φ(D0),因此,n个操作的总摊还代价为 总实际代价的上界。所以n个操作的最坏情况下时间为 O(n)
3.2 二进制计数器递增
1、将计数器执行一次 INCREMENT 操作后的势定义为 b_i —— i 次操作后计数器中 1 的个数。假设第 i 个 INCREMENT 操作将t_i 个位复位,则其实际代价 至多为 t_i + 1,因为除了复位 t_i 个位之外,还至多置位1 位。如果 b_i = 0,则第 i 个操作将所有 k 位都复位了,因此 b_i-1= t_i=k。如果 b_i > 0,则 b_i = b_i-1 - t_i + 1 。无论哪种情况, b_i <= b_i-1 - t_i + 1,势差为
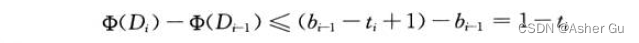
摊还代价为:
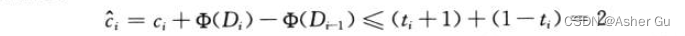
如果计数器从0开始,则 Φ(D0) = 0。由于对所有 i 均有 Φ(Di) ≥ 0,因此,一个 n 个 INCREMENT 操作的序列的总摊还代价是 总实际代价的上界,所以 n 个 INCREMENT 操作的最坏情况时间为 O(n)
2、即使计数器 不是从 0 开始也可以分析。计数器初始时包含 b_0 个1,经过 n 个 INCREMENT 操作后包含 b_n 个1,其中 0 <= b_0, b_n <= k。可以将公式
改写为
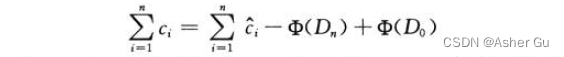
对所有1 ≤ i ≤ n,我们有c_i^ ≤ 2。由于 Φ(D0) = b0 且 Φ(Dn) = b_n,n 个 INCREMENT 操作的总实际代价为:
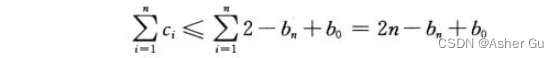
由于b_0 <= k,因此只要 k = O(n),总实际代价就是 O(n)。换句话说,如果至少执行了 n = Ω(k) 个 INCREMENT 操作,不管计数器初值是什么,总实际代价都是 O(n)
3、摊销分析中的势能法和核算法都是用于分析算法或数据结构性能的技术。尽管它们的目标相似,即分析一系列操作的平均性能,但它们的思想和方法有所不同
区别
定义方式:
势能法使用势能函数来 衡量数据结构的状态变化,通过势能变化来计算摊销成本(一般跟数据结构本身有关,比如1的数量,比如 数组当前容量与实际使用容量之差)
核算法使用信用的概念,每次操作支付实际成本并存储额外信用,以便未来操作使用(具体的操作:为每次插入操作支付实际成本并存储额外信用,为每次删除操作使用之前存储的信用)
计算方式:
势能法计算摊销成本时,将实际成本和势能变化结合起来,摊销成本等于实际成本加上势能变化
核算法则通过预存信用,确保所有操作的总费用(实际费用加上存储的信用)能够支付高成本操作
应用场景:
势能法更适合分析数据结构状态变化显著的情况,通过势能函数能直观地表示数据结构的潜在复杂度
核算法更适合分析较为稳定的操作序列,通过预存信用能确保操作序列的平衡
4、势函数的不唯一
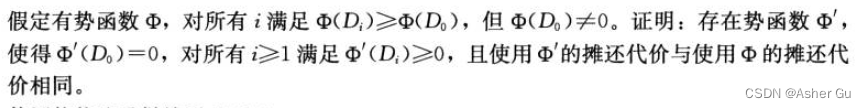

执行一个PUSH、POP和MULTIPOP栈操作的总代价(之前计算的都是分开的)是多少?假定初始时栈中包含 s_0 个对象,结果包含 s_n 个对象

4、动态表
1、可能 无法预先知道 会将多少个对象存储在表中。为一个表分配 一定的内存空间,随后可能会发现不够用。于是必须 为其重新分配更大的空间,并将所有对象 从原表中复制到新的空间中
如果从表中删除了很多对象,可能为其重新分配一个更小内存的内存空间就是值得的,虽然插入和删除操作 可能会引起扩张或收缩, 从而 有较高的实际代价, 但它们的摊还代价都是 O(1)。如何保证动态表中的空闲空间相对平均不超过总空间的比例 永远不超过一个常量分数
2、TABLE-INSERT 将一个数据项插入表中,它占用一个槽,即保存一个数据项的空间。TABLE-DELETE 从表中删除一个数据项,从而释放一个槽。 用什么样的数据结构 来组织动态表并不重要, 可以 使用指针,堆 或者 散列列表
将一个非空表 T 的装载因子 α(T) 定义为 表中存储的数据项的数量 除以表的规模(槽的数量)。赋予空表(没有数据项)的规模为 0, 并将其装载因子定义为 1。如果一个动态表的装载因子被限定在一个常量之下, 则其空闲空间 相对于总空间的比例不超过一个常数
首先分析只允许插入数据项的情况,然后考虑既允许插入也允许删除的—般情况
4.1 表扩张
1、当试图 向填满的表插入一个数据项时, 我们可以 扩张 表 —— 分配一个包含更多槽的新表。由于 总是需要 表位于连续的内存空间中,因此必须为更大的新表分配一个新的数组,然后 将数据项从旧表复制到新表中
一个常用的分配新表的启发式策略是:为新表分配2倍于旧表的槽。如果只允许插入操作,那么装载因子总是保持在 1/2 以上,因此,浪费的空间永远不会超过总空间的一半
属性T.table 保存指向表的存储空间的指针,T.num 保存表中的数据项数量,T.size 保存表的规模(槽数)。初始时令表为空:T.num = T.size = 0
TABLE-INSERT(T, x)
1 if T.size == 0
2 allocate T.table with 1 slot
3 T.size = 1
4 if T.num == T.size
5 allocate newtable with 2 * T.size slots
6 insert all items in T.table into newtable
7 free T.table
8 T.table = newtable
9 T.size = 2 * T.size
10 insert x into T.table
11 T.num = T.num + 1
可以 将每次基本插入操作的代价 设定为 1, 然后 用基本插入操作的次数描述 TABLE-INSERT 的运行时间
第 5 行和第 7 行 分配与释放内存空间的开销 是由第 6 行的数据复制代价决定的。 5~9 行执行一次扩张动作
分析对一个空表执行 n 个 TABLE-INSERT 操作的代价,第 i 个操作的代价 c_i。如果当前表满,会发生一次扩张,则 c_i = i:第 10 行基本插入操作的代价为1,再加上第 6 行将数据项 从旧表复制到新表的代价 i-1。如果执行 n 个操作,一个操作的最坏情况时间为 O(n),从而可得 n 个操作总运行时间的上界 O(n2)
这不是一个紧确界,因为在执行 n 个 TABLE-INSERT 操作的过程中,扩张操作是很少的
仅当 i - 1 恰为 2 的幂时,第 i 个操作才会引起一次扩张。一次插入操作的摊还代价 实际上是 O(1),可以用聚合分析来证明这一点。第 i 个操作的代价为

n 个 TABLE-INSERT 操作的总代价为

包含至多 n 个代价为 1 的操作,由于 n 个 TABLE-INSERT 操作的总代价以 3n 为上界, 因此, 单一操作的摊还代价至多为 3
2、通过使用 核算法, 处理每个数据项要付出 3 次基本插入操作的代价:将它插入当前表中, 当表扩张时移动他,当表扩张时 移动另一个已经移动过一次的数据项。假定表的规模在一次扩张后 变成 m,则表中保存了 m/2 个数据项,且 它当前没有存储任何信用。
为每次插入操作 付3美元,立即发生的基本插入操作 花去1美元。将另外的 1美元 存储起来作为 插入数据项的信用。将最后1美元 存储起来作为已在表中 m/2 个数据项中 某一个的信用(已经把信用花掉的,再给1个),当表中保存了 m 个数据项已满时,每个数据项预存储存了 1 美元,用于支付扩张时 基本插入操作的代价
3、用势能法来分析 n 个 TABLE-INSERT 操作的序列,定义一个势函数 Φ, 在扩张操作之后其值为 0, 而表满时 其值为表的规模,这样 就可以用势能来 支付下次扩张的代价
势函数 定义为

当一次扩张后, 我们有 T.num = T.size / 2,因此 Φ(T) = 0。表总是至少半满的, 即 T.num ≥ T.size / 2,于是 Φ(T) 总是非负的。因此,n 个 TABLE-INSERT 操作的摊还代价之和 给出了实际代价之和的上界
为了分析第 i 个TABLE-INSERT操作的摊还代价,令 mum_i 表示第 i 个操作后 表中数据项的数量,size_i 表示第 i 个操作后表的总规模,Φ_i 表示第 i 个橾作后的势。初始时,num_0 = 0 ,size_0 = 0 及 Φ_0 = 0
如果第 i 个 TABLE-INSERT 操作没有触发扩张,那么有 size_i = size_i-1, 此操作的摊还代价为

如果第 i 个 TABLE-INSERT 操作触发了一次扩张, 则有 size_i = 2⋅size_i − 1,及 size_i -1 = num_i−1 = num_i - 1,这意味着 size_i = 2⋅(num_i − 1),因此,此操作的摊还代价为


4.2 表扩张和收缩
1、为了限制浪费的空间,可以在装载因子变得太小时 对表进行收缩操作。表收缩与表扩张是类似的操作:当表中的数据项数量下降到太少时,分配一个新的更小的表,然后 将数据项从旧表复制到新表中。之后 可以释放旧表占用的内存空间,将其 归还内存管理系统
当插入一个数据项到满表时 应该将数据规模加倍,删除一个数据项 导致表空间利用率不到一半时 就应该将表规模减半。可以保证表的装载因子 永远不会低于 1/2,但遗憾的是,这会导致操作的摊还代价过大
对一个表T执行 n 个操作,其中 n 恰好是2的幂,前 n/2 个操作是插入,其总代价为 Θ(n)。在插人序列结束时,
T.num = T.size = n/2。接下来的 n/2 个操作是这样的
插入、删除、删除、插入、插入、删除、删除、插入、插入、…
第一个插入操作导致 表规模扩张至 n。接下来两个删除操作 导致表规模收缩至 n/2,接下来两个插入操作引起另一次扩张,以此类推。每次扩张和收缩的代价为 Θ(n),而收缩和扩张的代价为 Θ(n),而收缩和扩张的次数为 Θ(n)。因此,n个操作的总代价为 Θ(n2),使得每个操作的摊还代价为 Θ(n)
2、在表扩张之后, 无法删除足够多的数据项 来为收缩操作支付费用; 类似地, 在表收缩之后, 无法插入足够多的数据项来支付扩张操作
可以改进此策略, 允许表的装载因子低于 1/2。当向一个满表插入一个新数据项时, 仍然将表规模加倍,但只有当装载因子小于 1/4 而不是 1/2 时, 我们才将表规模减半。因此 装载因子的下界为1/4
当扩张或收缩表时,已经存储了足够的势 来支付复制所有数据项至新表的代价(T.num)
需要这样一个势函数:当装载因子 增长为1或下降为1/4时,势函数值 增长为 T.num。而表扩张或收缩之后,装载因子重新变回 1/2,而表的势 降回到0
对于分析,需要假定 无论何时表中数据项数量 下降为 0, 都会将表占用的内存空间释放掉。也就是说, 若 T. num = 0,则 T. size = 0
用势能法分析 n 个 TABLE-INSERT 和 TABLE-DELETE 操作组成的序列的代价。 首先定义一个势函数 Φ,在扩张或收缩操作之后其值为 0,而当装载因子增长到 1 或降低到 1/4 时,积累到 足够支付扩张或收缩操作代价的值(T.num)。将非空表 T 的装载因子定义为 α(T) = T.num / T.size。由于对空表 T.num = T.size = 0 且 α(T) = 1,因此无论表是否为空,总是有 T.num = α(T) * T.size。势函数定义为

势永远不可能为负。因此,用势函数 Φ 定义的操作序列的总摊还代价是 总实际代价的上界
当装载因子为 1/2 时,势为0。当装载因子为1时,T.size = T.num,意味着 Φ(T) = T.num, 因此,势足够支付 插入操作引起的表扩张的代价。当 装载因子为 1/4 时,有 T.size = 4*T.num,这也意味着 Φ(T) = T.num,势也是够支付删除操作引起的表收缩的代价

令 c_i 表示第 i 个操作的实际代价,c_i^ 为用势函数 Φ 定义的摊还代价,num_i 表示表中第 i 个操作后存储的数据项的数量,size 表示第 i 个操作后表的规模, α_i 表示第 i 个操作后的装载因子, Φ_i 表示第 i 个操作后的势。 初始时,num_0 = 0,size_0 = 0,α_0 = 1,Φ_0 = 0
3、首先分析第 i 个操作为 TABLE-INSERT 的情况。若 α_i−1 >= 1/2, 分析与上节表扩张的分析相同。无论表是否扩张, 操作的摊还代价至多为 3。若 α_i−1 < 1/2,则第 i 个操作不能令表扩张,因为只有当 α_i−1 =1 时表才会扩张(表满了才扩张)。若 α_i 也小于 1/2(自然 α_i-1 < 1/2),则第 i 个操作的摊还代价为(根据 Φ(T) 分段函数给出式子)

若 α_i−1 < 1/2 但 α_i ≥ 1/2,则

因此, 一个 TABLE-INSERT 操作的摊还代价至多为 3
4、第 i 个操作是 TABLE-DELETE 的情况。在此情况下,num_i = num_i−1 − 1,若 α_i −1 < 1/2,则必须考虑删除操作是否引起表收缩。如果未引起表收缩操作,则 size_i = size_i−1 且操作的摊还代价为

若 α_i−1 < 1/2 且第 i 个操作触发了收缩操作,则操作的实际代价为 c_i = num_i +1, 因为我们删除了 一个数据项,又移动了 num_i 个数据项。size_i / 2 = size_i−1 / 4 = num_i +1, 因此操作的摊还代价为

当第 i 个操作是 TABLE-DELETE 且 α_i ≥ 1/2 时, 摊还代价上界是一个常数
如果α_i−1 ≥ 1/2,表删除不能收缩,所以c_i=1,size_i = size_i−1

总之, 由于每个操作的摊还代价的上界是一个常数, 在一个动态表上执行任意 n 操作的实际运行时间是 O(n)