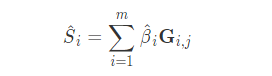我们现在继续对于群体遗传学进行统计建模,书接上回,我们讨论了孤雌生殖的物种违反哈代温伯格遗传比例的例子,那我们现在来看多于两个等位基因的情况的计算。
如果没有看过之前文章的同学,可以先去看一下之前的文章:
多等位基因情况
到目前为止,我们一直专注于一个双等位基因(bi-allelic)系统,其中一个等位基因的频率表示为p,另一个等位基因的频率表示为(1-p)。然而,基因型预测可以很容易地扩展到超过两个等位基因。由于我们总是假设完全随机交配,我们理论上预期的纯合子数量仍然将等于p²,无论我们考虑多少个等位基因。一组j个等位基因的预期纯合率会是每个等位基因频率平方的和。

p1 <- 0.2
p2 <- 0.3
p3 <- 0.5
sum(sapply(c(p1,p2,p3),function(x) x^2))假设我们有三个等位基因频率,p1、p2和p3,并希望计算总体预期的纯合子基因型频率
这给了我们一个总体的纯合子基因型频率为38%。然后我们可以相当容易地得到一个预期的杂合子频率:

多位点情况
接下来让我们读取一个来自东地中海地区阿勒颇松(Pinus halepensis)的真实多采样等位基因数据集,整理这些数据,并计算我们预期的以及观察到的杂合子频率(改编自Gershberg等人,2016)。使用popgenr包,安装请看前面的博客:

基因型中的数据都来自微卫星。微卫星是由短重复的核苷酸组成特征的DNA片段。这类遗传标记因其高度变异(即具有高突变率)而常用于研究。让我们用str()函数来了解一下数据:
library("popgenr")
data(genotypes)
str(genotypes)
我们可以看到这个数据框有181个观测值(行)和20列。其中十八列代表不同的位点,每个独特的数字是一个不同的等位基因,前两列是每个样本的个体ID($ID)和种群分配($Pop)。我们想要编写一个迭代代码来遍历数据集进行计算;为了简化这个过程,我们先对数据进行一些简化处理。
rownames(genotypes) <- genotypes$ID
genotypes <- genotypes[,-c(1,2)]根据这个数据集的设置,每个个体有两列,代表在一棵采样的二倍体松树中一个位点的两个拷贝。让我们计算数据集中位点的总数。对数据框使用length()函数应该只返回列的数量。由于每个位点由两列表示,我们可以将其除以2得到采样的位点总数:
(num.loci <- (length(genotypes))/2)现在我们知道我们正在处理九个不同的位点。接下来我们需要弄清楚每个位点实际上有多少个等位基因。我们将使用for循环来为每个位点进行等位基因计数。、
Hom_exp <- NULL
Het_exp <- NULL
Hom_obs <- NULL
Het_obs <- NULL
for(n in 1:(num.loci)){ # 对于每一个基因座
current <- n*2-1 # 计算当前基因座的起始位置
locus <- c(genotypes[,current],genotypes[,current+1]) # 获取当前基因座的两个等位基因
alleles <- unique(locus) # 获取该基因座的所有独特等位基因
alleles <- alleles[alleles!=-1] # 移除非等位基因标记(例如缺失数据标记为-1)
p_allele <- NULL # 初始化等位基因频率向量
for(a in 1:length(alleles)){ # 对于每个独特的等位基因
p_allele <- c(p_allele,
sum(alleles[a]==locus)/sum(locus!=-1)) # 计算等位基因频率
}
Hom_exp <- c(Hom_exp, sum(sapply(p_allele,
function(x) x^2))) # 期望纯合子频率是每个等位基因频率的平方和
obs <- 0 # 初始化观察到的纯合子计数
for(i in 1:length(genotypes[,current])){ # 对于当前基因座的每个个体
if(genotypes[i, current]!=-1){ # 如果等位基因不是缺失数据
if(genotypes[i, current]==genotypes[i,current+1]){ # 如果两个等位基因相同
obs <- obs+1 # 增加纯合子计数
}
}
}
Hom_obs <- c(Hom_obs,obs/(sum(locus!=-1)/2)) # 观察到的纯合子频率是纯合子计数除以有效等位基因总数的一半
}在R语言中,极少数会使用繁琐的循环,但是为了处理这里的数据我们不得不这样做,所以这也是为什么我们课题组会使用Java进行计算,我简述一下这个代码的意思:我们写一个循环遍历每个基因座(locus)--内部循环计算每个等位基因的频率--计算期望纯合子频率--计算观察到的纯合子频率:
现在要找到预期和观察到的杂合子频率,我们只需从频率的总和中减去我们的纯合子频率:
Het_exp <- 1- Hom_exp
Het_obs <- 1- Hom_obs让我们绘制这九个位点的观察到的杂合度频率与预期杂合度频率的对比图,看看它们之间的关系如何。我们将从简单地使用plot绘制Het_obs和Het_exp开始,然后绘制一条回归线。我们将使用lm(线性模型)函数来估计数据集之间的线性关系(最小二乘线性回归)
# 绘制观测值与期望值的散点图
plot(Het_obs, Het_exp)
# 添加线性回归线
abline(lm(Het_exp ~ Het_obs))
# 进行线性回归分析并打印摘要
reg <- summary(lm(Het_exp ~ Het_obs))
print(reg)
# 提取并打印决定系数(r-squared)
rr <- reg$r.squared
rrlabel <- paste("r-squared =", round(rr, digits = 3))
text(0.6, 0.2, rrlabel)
# 提取并打印P值
pv <- reg$coefficients[2, 4]
pvlabel <- paste("P-value =", pv)
text(0.6, 0.15, pvlabel)

查看我们的图,我们应该看到一个很好的验证,即哈代-温伯格预测可以扩展到多个位点,在这种情况下,它在预测广泛的杂合性值方面表现得相当好。
下一篇博客我们将讲述血液型及血液等位基因频率的内容,欢迎大家点赞关注!