代码学习
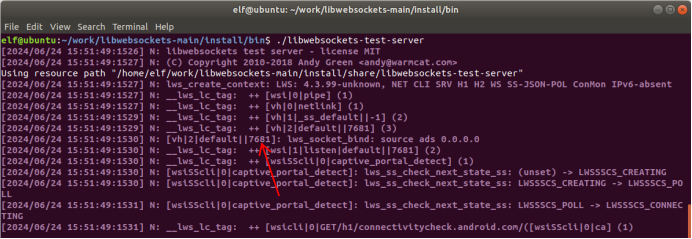
(1)查看运行结果,思考为什么?
[root@ red ~]#VAR1=1
[root@ red ~]#(VAR1=2; echo $VAR1)
[root@ red ~]#echo $VAR1
[root@ red ~]# { VAR1=2; echo $VAR1; }
[root@ red ~]# echo $VAR1
VAR1=1:设置变量VAR1的值为1。(VAR1=2; echo $VAR1):这是一个子 shell 环境,VAR1=2在子 shell 中设置变量VAR1的值为2,然后echo $VAR1打印出子 shell 中的VAR1值,即2。但是,这个子 shell 中的变量改变不会影响父 shell 中的VAR1值。echo $VAR1:打印出父 shell 中的VAR1值,由于上一条命令是在子 shell 中执行的,所以这里的输出仍然是1。{ VAR1=2; echo $VAR1; }:这是一个组命令(group commands),与子 shell 类似,它在当前 shell 的环境中执行,但变量的改变不会影响外部环境。因此,VAR1=2设置的变量只在组命令内部有效,echo $VAR1打印出的是2,但这个改变不会反映到组命令外部。echo $VAR1:再次打印父 shell 中的VAR1值。由于第 4 点中的改变只限于组命令内部,所以这里的输出依然是1。
(2)p1.sh文件的内容如下,运行并查看结果。
array=(Mon Tue Wed Thu Fri Sat Sun)
len="${#array[@]}"
for ((i=0;i<len;i++)); do
echo ${array[i]} # 打印元素
done
# 过程:
[root@red ~]# vi p1.sh
[root@red ~]# chmod u+x p1.sh
[root@red ~]# ./p1.sh
chmod
chmod 权限模式(符号模式 / 数字模式) 文件名
符号模式是通过符号来表示权限的方式(读取(r),写入(w)和执行(x)),包括:
- u:代表所有者的权限
- g:代表所属组的权限
- o:代表其他人的权限
- a:代表所有人的权限(即u、g和o的权限)
- +:增加权限
- -:减少权限
- =:设置权限
要将file.txt文件的所有者权限设置为读写执行,可以使用以下命令:
chmod u=rwx file
数字模式是通过数字来表示权限的方式,每种权限对应一个数字(所有者+所属组+其他人,比如下面的7=1+2+4),而且三个数的顺序刚好是所有者+所属组+其他人,所以所属组和其他人的权限是 0 :
- 读取权限:4
- 写入权限:2
- 执行权限:1
将file.txt文件的所有者权限设置为读写执行,可以使用以下命令:
chmod 700 file.txt
shell 语法
注释:
- 以
#开头的行是注释,不会被执行。
- 以
变量:
- 变量使用
VAR=value格式定义。 - 使用
$VAR来引用变量的值。 - 变量名通常大写以区分普通字符串。
- 变量使用
引号:
- 单引号
' '用于保持字符串的字面意义,不会展开变量。 - 双引号
" "允许变量展开,同时可以包含空格。
- 单引号
字符串:
- 字符串是字符序列,可以用单引号或双引号括起来。
算术运算:
- 使用
$(( ))进行算术运算,例如:$(( 1 + 1 ))。
- 使用
条件语句:
- 使用
if、then、else、elif(else if 的缩写)、fi构建条件语句。
- 使用
循环:
for循环用于遍历列表。while循环在条件为真时不断执行。until循环在条件为假时不断执行。
数组:
- 定义数组:
array=(value1 value2 ...) - 引用数组元素:
${array[index]} - 获取数组长度:
${#array[@]}或${#array[*]}
- 定义数组:
函数:
- 使用
function_name() { ... }定义函数。 - 使用函数名调用函数。
- 使用
输入和输出:
- 使用
<重定向输入。 - 使用
>重定向输出,覆盖文件。 - 使用
>>重定向输出,追加到文件。
- 使用
管道:
- 使用
|将一个命令的输出作为另一个命令的输入。
- 使用
通配符:
*匹配任意数量的字符。?匹配单个字符。
文件测试:
- 使用
[[ ]]进行文件测试,例如[[ -f filename ]]检查文件是否存在。
- 使用
命令替换:
- 使用
$(command)或反引号`command`来执行命令并使用其输出。
- 使用
子 shell:
- 使用圆括号
(command)创建子 shell 执行命令。
- 使用圆括号
命令行参数:
$0是脚本名称。$1、$2等是脚本的参数。$#是参数的数量。$*和$@是所有参数的列表。
环境变量:
- 环境变量通常大写,如
PATH。
- 环境变量通常大写,如
退出状态:
- 使用
exit或return命令退出脚本,并可以返回一个状态码。
- 使用
信号:
- 使用
trap命令捕获信号。
- 使用
Shell 脚本的执行:
- 直接调用脚本:
./scriptname.sh - 使用
source或.命令在当前 shell 环境中执行脚本。
- 直接调用脚本:
(3)p2.sh文件的内容如下,运行并查看结果。
array=(Mon Tue Wed Thu Fri Sat Sun)
for e in "${array[@]}" ; do # 将数组展开
echo $e
done
for e in "${array[*]}" ; do # 将数组当成一个整体 但是包含空格 会被分割为多个元素
echo $e
done # 最终打印为循环遍历两次数组
(7)编辑p4.sh 其内容如下。
echo $# $1 $2 $3 $4 # $# 参数个数
shift
echo $# $1 $2 $3 $4
shift
echo $# $1 $2 $3 $4
set aa bb cc # 重新设置值
echo $# $1 $2 $3 $4
# 运行查看结果。
[root@red ~]# bash p4.sh 10 20 30 40 50
5 10 20 30 40
4 20 30 40 50
3 30 40 50
3 aa bb cc
(9)依次运行下述命令,查看结果(==与=~两边有空格)
[root@red ~]# str="axxyycd"
[root@red ~]# [[ $str == a?b ]]; echo $? # a?b 表示以 'a' 开头,后面跟着 0 或 1 个任意字符,然后是 'b' 命令条件为false, echo $? 将打印上一个命令的退出状态码,即 1
[root@red ~]# [[ $str == a*b ]]; echo $? # 表示以 'a' 开头,后面跟着任意数量(包括 0)的任意字符,然后是 'b' 条件为 true 打印 0
[root@red ~]# str="abcabcabcabcd"
[root@red ~]# [[ $str =~ a ]];echo $? # str 中包含字符 'a',条件为真,打印 0
[root@red ~]# [[ $str =~ abc ]];echo $? # 包含子字符串 "abc",所以 [[ $str =~ abc ]] 将返回 0
[root@red ~]# [[ $str =~ (abc)+ ]]; echo $? # (abc)+ 表示 "abc" 这个模式出现一次或多次
[root@red ~]# [[ $str =~ ^(abc)+$ ]]; echo $? # ^ 和 $ 分别表示字符串的开始和结束,整个表达式表示整个字符串是否只由 "abc" 重复组成 不满足 打印1
[root@red ~]# [[ $str =~ ^(abc)+d$ ]]; echo $? # 是否以 "abc" 重复开始并以 "d" 结束 打印 0
== 和 =(不严格) 都可以判断是否相等
=~ 左侧的字符串能否匹配右侧的正则
(10)文件 p5.sh 内容如下,运行并查看结果
rm –r da # 尝试递归删除目录 da 及其内容
touch b.txt
if [ -f b.txt ] && echo "file" && [ -d da ] && echo " directory" # file
then
echo "one"
else
echo "two" # two
fi
(11)文件p6.sh 内容如下,运行bash p6.sh /root并查看结果
dir=$1
if [ -d $dir ]; then # 检查变量 dir 是否指向一个存在的目录
cd $dir
for fname in * ; do # 对当前目录中的每个文件和目录条目进行遍历 do 表示循环体开始
if [ -f $fname ]; then # 检查当前条目 fname 是否是一个文件 then 表示执行下列语句块
echo $fname
else
echo "$fname invalid file"
fi # 结束 if-else 循环
done # 结束 for 循环
else
echo "bad directory name:$dir"
fi
编程题
(1)设计一个shell脚本,求最小值
min=10000
for i in 12 5 18 58 -3 80 ;do
if (( i<min )) ;then
(( min=i ))
fi
done
echo " The smallest number is: $min"
(2)设计一个shell脚本,求命令行上所有参数整数和。
sum=0
while (( $# != 0 )) ; do # $# 表示传递给脚本的参数个数
(( sum = sum+$1 )) # 传递给脚本或命令的第一个参数
shift # 改变位置参数的值,使得当前的 $1 变成 $2 同理
done
echo "the sum of arguments is $sum"
(3)读取正整数m,计算各位和,例如123,各位和1+2+3=6
read m
while (( m!=0 )) ;do
(( sum=sum+m%10 ))
(( m=m/10 ))
done
echo $sum
(4)判断回文数(思考回文串)
reverse(){
x=`echo -n $1| rev` # -n 表示不换行 rev 表示翻转字符串
if [[ $x==$1 ]];then
return 0; # 条件为真(即 $x 等于 $1),则返回状态码 0 成功或真值
else
return 1
fi
}
双方括号
[[ ... ]]:
- 用于条件表达式测试。
- 支持模式匹配和正则表达式。
- 可以使用&&和||来组合多个测试条件。
- 某些情况下,可以不用反引号(backticks)或$(...)来执行命令。
- 可以包含空格,因此在处理包含空格的字符串时更加方便。
小括号
((...)):
- 主要用于算术运算和表达式求值。
- 强制Shell执行算术优先级,即使在表达式中有其他运算符。
- 可以用来计算表达式的结果,并将结果赋值给变量。
- 不能用来测试文件存在性或字符串匹配等条件测试。
(6)从100开始找到50个含有7的素数输出,每五个一行。
function isprime(){
n=$1
if((n==2));then
return 0;
fi
local i; # 定义一个遍历
for ((i=2;i<=n/2;i++)); do
if (( n%i == 0 )); then
return 1;
fi
done
return 0;
}
i=100
count=0
while ((count<=50)); do
isprime $i
r=$?
if (( r==0 )) && [[ "$i" =~ 7 ]] ;then
printf "%4d" $i
((count++))
if (( count%5 ==0 ));then
echo ""
fi
fi
((i++))
done
(2)编写shell程序,输出下列图形,行数由键盘输入:
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
要编写一个shell程序输出指定行数的图形,可以使用嵌套循环来完成。
#!/bin/bash
# 读取用户输入的行数
read -p "请输入行数: " rows
# 循环打印每一行
for (( i=1; i<=rows; i++ ))
do
# 打印前导空格,使数字右对齐
for (( j=rows; j>i; j-- ))
do
echo -ne "\t"
done
# 打印数字
for (( k=1; k<=i; k++ ))
do
echo -ne "$k\t"
done
# 换行
echo
done
read -p "请输入行数: " rows:提示用户输入行数并将其存储在变量rows中。- 外层
for循环for (( i=1; i<=rows; i++ )):控制打印的行数。 - 内层
for循环for (( j=rows; j>i; j-- )):打印前导空格,使数字右对齐。 - 第二个内层
for循环for (( k=1; k<=i; k++ )):打印每行的数字。 echo:在每一行的最后换行。
find
find /path/to/search -name 'filename.txt'
find /path/to/search -regex '.*\.txt'
find /path/to/search -type f # f 仅搜索文件 d 仅搜索目录
find /path/to/search -empty # 空文件
find /path/to/search -size +10M # 按文件大小搜索
find /path/to/search -mtime -7 # 搜索过去 7天内被修改的文件
find /path/to/search -name '*.txt' -exec rm {} \; # {} 占位 exec 表示执行命令
grep
grep [-xxx] 'pattern' file.txt # 搜索字符串 pattern 并打印所有匹配的行
grep -r 'pattern' /path/to/directory # 递归搜索指定目录
-xxx 选项:
- -i 不区分大小写
- -v 排除匹配的行
- -c: 对匹配的行计数
- -n 输出中包括匹配行的行号
- -l 仅打印包含匹配行的文件名
- -h: 抑制包含匹配模式的文件名的显示
cut
cut -d',' -f1,3 filename.csv # filename.csv 中提取第一和第三列,逗号作为分隔符
cut -d' ' -f1 --complement filename.txt # 提取除了第一列以外的所有列
cut -d' ' -f2-4 filename.txt # 第二到第四列
cut -d' ' -f1 filename.txt | grep -v '^$' # 排除空白行
sort
sort [-xxx] filename.txt # 对文件中的行进行默认的升序排列
-xxx选项:
- -n: 数值升序排列
- -r:降序
- -kn:对第 n 列进行排序
- -b:忽略行开头空白字符
- -u:去除重复行
- -t: :指定
:作为分隔符
uniq
通常与 sort 命令结合使用,因为 uniq 只能识别连续的重复行。
sort input.txt | uniq # 过滤掉排序后的连续重复行
sort input.txt | uniq -c # 计算重复行
选项:
- -d: 只打印重复行
- -u:打印不重复的行
- -s:忽略前导空白
- -w 5:设置字段宽度为 5
- -f 2:跳过前两个字段
awk
awk '/pattern/ { print $0 }' input.txt # 打印包含 pattern 的行
awk '{ print $1, $3 }' input.txt # 打印每行的第一个第三个字段
awk '{ num += $1 } END { print num / NR }' input.txt # 计算第一列的平均值
sed
-
- (1) 查找包含字符 “o” 的行(“o” 可以出现任意次数):
sed -n '/o/ p' /etc/passwd - (2) 查找包含一个或多个字符 “o” 的行:
sed -n '/o.*o/p' /etc/passwd - (3) 查找包含两个或多个字符 “o” 的行:
sed -n '/oo.*/p' /etc/passwd
- (1) 查找包含字符 “o” 的行(“o” 可以出现任意次数):
使用
sed将input文件中的\OU字符串修改为(ou):sed 's/\OU/(ou)/g' input > output使用
sed打印input文件中除第3到8行之外的所有行:- 使用
-n和p打印指定行:sed -n -e '1,2p' -e '9,$p' input - 使用
skip到第8行后开始打印:sed -n '1,8!p' input - 使用
sed的模式空间:sed -n '1p;2p;8q;9,$p' input
- 使用
使用
sed将input文件中的 “abcde” 替换为 “EDCBA”:sed 's/abcde/EDCBA/g' input > output写一个命令,去掉某文件中所有的空格符,并将结果存储到
a.txt:tr -s ' ' < original_file > a.txt使用
awk处理student文件:- (1) 列出姓名,平均分,总分(假设第一列是姓名,第二列是科目数,第三列是每科成绩):
awk '{sum+=$3; avg=sum/$2;} END {print "Name:", $1, "Average:", avg, "Total:", sum}' student - (2) 列出有不及格的学生姓名(假设60分为及格):
awk '$3 < 60 {print $1}' student - (3) 列出总分第一名的学生姓名(考虑并列第一的情况):
awk '{sum[$1]+=$3;} END {max=0; for (name in sum) if (sum[name] > max) {max=sum[name]; names=name} else if (sum[name] == max) {names=names " " name}; print "Top scorer(s):", names}' student
- (1) 列出姓名,平均分,总分(假设第一列是姓名,第二列是科目数,第三列是每科成绩):
创建删除和修改
创建新用户
sudo useradd newusername这将创建一个名为
newusername的新用户。修改用户信息:
- 使用
usermod命令可以修改用户的账户信息,例如用户的组、登录shell等。sudo usermod --shell /bin/bash username - 更改用户密码:
sudo passwd username
- 使用
删除用户:
sudo userdel username这将删除用户
username,但保留用户的家目录和文件。删除用户及其家目录:
sudo userdel --remove-home username使用
--remove-home选项可以同时删除用户及其家目录。
文件和目录管理
创建文件或者目录:
touch filename.txt使用
touch命令创建一个空文件。创建目录:
mkdir directoryname使用
mkdir命令创建一个新目录。修改文件或目录权限:
chmod 755 filename.txt使用
chmod命令更改文件或目录的权限。修改文件或目录所有者:
chown newowner filename.txt使用
chown命令更改文件或目录的所有者。删除文件:
rm filename.txt使用
rm命令删除文件。删除目录:
rmdir directoryname使用
rmdir命令删除空目录。如果目录非空,可以使用rm -r directoryname来递归删除目录及其内容。移动或重命名文件/目录:
mv oldname.txt newname.txt使用
mv命令移动或重命名文件和目录。复制文件/目录:
cp source.txt destination.txt cp -r source_directory destination_directory使用
cp命令复制文件,使用-r选项递归复制目录。查看文件内容:
cat filename.txt使用
cat命令查看文件内容。查看文件状态:
ls -l filename.txt使用
ls -l命令查看文件的详细状态,包括权限、所有者、大小和最后修改时间。
mount
mount /dev/sda1 /mnt/mydrive # 将挂载设备 /dev/sda1 到 /mnt/mydrive 目录
mount -o ro /dev/sda1 /mnt/mydrive # 以只读的方式挂载
df -h # 查看挂载的文件系统 df 命令显示磁盘空间使用情况,-h 选项以人类可读的格式(如 GB、MB)显示
umount -f /mnt/mydrive # 强制卸载
正则
- 普通字符:
- 普通字符是正则表达式中最常见的,它们表示搜索匹配自己的字面值。例如,正则表达式
hello匹配包含 “hello” 字符串的文本。
- 普通字符是正则表达式中最常见的,它们表示搜索匹配自己的字面值。例如,正则表达式
- 字符类:
- 使用方括号
[...]定义字符类,匹配方括号内的任何单个字符。例如,[abc]匹配 “a”、“b” 或 “c”。
- 使用方括号
- 范围表达式:
- 在字符类中,可以使用连字符
-表示范围。例如,[a-z]匹配任何小写字母。
- 在字符类中,可以使用连字符
- 否定字符类:
- 使用脱字符
^放在方括号内来否定字符类。例如,[^abc]匹配除了 “a”、“b”、“c” 之外的任何单个字符。
- 使用脱字符
- 重复操作符:
*表示前面的元素零次或多次出现。+表示一次或多次出现。?表示零次或一次出现。{n}表示恰好 n 次出现。{n,}表示至少 n 次出现。{n,m}表示 n 到 m 次出现。.表示任意单个字符。
- 分组:
- 使用圆括号
(...)来创建一个分组,允许对正则表达式的部分进行组合,并可以与捕获组一起使用。
- 使用圆括号
- 选择:
- 使用竖线
|表示选择。例如,cat|dog匹配 “cat” 或 “dog”。
- 使用竖线
- 锚点:
^表示行的开始。$表示行的结束。\b表示单词边界。
- 转义特殊字符:
- 使用反斜杠
\来转义特殊字符,使其失去特殊含义,表示字面值。例如,要匹配点号.,可以使用\.。 \d: 匹配从 0 到 9\D: 表示[^0-9]\s: 它用于匹配文本中的空白区域\w: 所有字母、数字以及下划线\b: 确定单词的起始和结束位置
- 使用反斜杠
在正则表达式中,\w、\s 和 \b 是具有特殊含义的转义序列,分别用于匹配不同的字符集合:
\w:\w匹配任何单个字字符,等同于[a-zA-Z0-9_]。这包括所有字母、数字以及下划线。它不匹配非拉丁字符,如汉字或西里尔字母。
\s:\s匹配任何空白字符,包括空格、制表符(\t)、换行符(\n)、回车符(\r)、垂直制表符(\v)和换页符(\f)。它用于匹配文本中的空白区域。
\b:\b匹配一个单词边界。单词边界通常是指一个单词字符(\w)和非单词字符(\W或任何非\w的字符)之间的位置。特殊地,字符串的开头和结尾也被视为单词边界。\b常用于确定单词的起始和结束位置,以便进行诸如单词匹配的操作。
示例:
匹配一个单词(假设单词由字母、数字或下划线组成):
\b\w+\b匹配一个或多个空格:
\s+匹配一个句子,假设句子以点号结束,并且句子中单词之间由空格分隔:
\b[A-Za-z0-9_]+\b(?:\s+[A-Za-z0-9_]+)*\.匹配一个行首或行尾的空白字符:
^\s+|\s+$匹配一个字符串中的所有单词边界,可以用来统计字符串中的单词数量:
\b
其他知识点
passwd 文件的每一行用“:”分隔为7个字段,各个字段的内容如下。
用户名:加密口令:UID: GID:用户的描述信息:主目录:命令解释器(登录shell)
比如:
user1:x:1002:1002::/home/user1:/bin/bash
cat /etc/group 查看 group 文件:
组名称:组口令(一般为空,用x占位):GID:组成员列表
比如:
user1:x:1002:
文件各种属性信息中的文件类型权限中的文件类型:
- 普通文件(-):
- 表示这是一个标准文件。
- 例如:
-rw-r--r--表示一个普通文件,具有读和写权限的设置。
- 目录(d):
- 表示这是一个目录。
- 例如:
drwxr-xr-x表示一个目录,具有写权限和执行(访问)权限。
- 符号链接(l):
- 表示这是一个指向另一个文件或目录的符号链接。
- 例如:
lrwxrwxrwx表示一个符号链接,具有读、写和执行权限。
- 字符设备文件(c):
- 表示这是一个字符设备文件。
- 例如:
crw-r--r--表示一个字符设备文件,通常用于设备如键盘或串行端口。
- 块设备文件(b):
- 表示这是一个块设备文件。
- 例如:
brw-r--r--表示一个块设备文件,通常用于设备如硬盘。
- FIFO(命名管道,p):
- 表示这是一个 FIFO 命名管道,用于进程间通信。
- 例如:
prw-r--r--表示一个 FIFO 命名管道。
- 套接字(s):
- 表示这是一个套接字文件,用于进程间通信或网络通信。
- 例如:
srwxr-xr-x表示一个套接字。
文件类型是文件权限字符串的第一个字符,紧接着是关于文件所有者、所属组和其他用户权限的设置。使用 ls -l 命令可以查看文件的权限和类型。例如:
-rw-r--r-- 1 user group 1024 Jan 01 00:00 file.txt
drwxr-xr-x 2 user group 4096 Jan 01 00:00 directory
lrwxrwxrwx 1 user group 12 Jan 01 00:00 symlink -> target
crw--w----+ 1 root tty 136, 2 Jan 01 00:00 /dev/ttyS0
使用 firewalld 服务使用 firewall 命令。
free 命令主要用于查看系统内存、虚拟内存大小以及占用情况。
cat 命令用于滚动显示文件内容,将多个文件合并成一个。
ls 用于列出文件或者目录信息。
实验一
(一)文件与目录操作命令
查看用户所处当前目录:
pwd切换到
/目录:cd /拷贝文件到
/root目录:cp /etc/inittab /root/统计文件的字节数、行数、字数:
wc -c /etc/inittab wc -l /etc/inittab wc -w /etc/inittab在
/root目录下创建test目录:mkdir /root/test复制
/etc目录及其内容到test目录:cp -r /etc/* /root/test/将
test目录改名为test2:mv /root/test /root/test2删除
test2目录:rm -r /root/test2
(二)grep
查找含有 ‘a’ 的行:
grep 'a' filename.txt查找含有多个 ‘a’ 的行:
grep -E 'a+' filename.txt查找只有 ‘a’ 的行:
grep '^a$' filename.txt查找有连续 ‘a’ 的行:
grep -E 'a{2,}' filename.txt查找全是 ‘a’ 的行:
grep -E '^a+$' filename.txt查找没有 ‘a’ 的行:
grep -v 'a' filename.txt查找空行:
grep -E '^$' filename.txt统计 ‘redhat’ 出现的次数:
grep 'redhat' filename.txt | wc -l
(三)find
列出所有
.c文件:find . -name '*.c'列出所有文件:
find .列出最近 20 天内更新过的文件:
find . -mtime -20查找
/var/log目录中更改时间在 7 日以前的普通文件:find /var/log -type f -mtime +7 -exec ls -l {} \;查找文件属主具有读、写权限的文件:
find . -type f -perm /u=rw查找文件长度为 0 的普通文件:
find . -type f -size 0查找
/root下 3 分钟内访问过的*.txt文件并复制:find /root -name "*.txt" -amin -3 -exec cp {} /tmp \;
(四)sort, cut, uniq 等命令
按 Java 和离散数学成绩排序:
sort -t' ' -k 5,5n -k 4,4nr student.txt提取姓名和 Linux 成绩:
cut -d' ' -f 1,6 student.txt按籍贯统计学生人数:
cut -d' ' -f 2 student.txt | sort | uniq -c找出 C 语言成绩最高的前五名学生:
sort -t' ' -k 3,3nr student.txt | head -5找出 C 语言不同成绩及出现次数:
cut -d' ' -f 3 student.txt | sort | uniq -c
实验二
绝大部分上面都讲过,这里挑一些没讲的重点写下。
把目录test及其下的所有文件的所有者改成st1,所属组改成st1
chown -R st1:st1 test
umask 命令用于设置默认文件权限掩码。当运行 umask 命令时,它会显示当前的掩码值。如果运行 umask 003,它会将掩码设置为 003。
查看当前 umask 值:
umask这会显示一个四位八进制数字(默认为
0022)。设置 umask 为
003:umask 003这不会有任何输出,但会改变 umask 设置。
使用
touch命令创建一个新文件af.txt:touch af.txt查看
af.txt的权限:ls -l af.txt这会输出类似如下的信息:
-rw-rw-r-- 1 user group 0 date time af.txt
默认情况下,新文件的权限是 666(rw-rw-rw-),表示所有者、组和其他用户都有读写权限。
umask 的作用是从默认权限中减去(掩码)相应的权限位。因此:
- 默认文件权限:
666 - umask:
003
计算新的文件权限:
- 默认文件权限减去 umask:
666 - 003 = 664(即 rw-rw-r–)
这意味着新创建的文件 af.txt 会有权限 664,即所有者和组用户有读写权限,而其他用户只有读取权限。
新建组 student
groupadd student
新建用户userl,指定其主目录为/userl,组为st1,附加组为student,指定shell为/bin/bash
useradd -d /userl -g st1 -G student -s /bin/bash userl
修改用户 userl 的个人说明:
usermod -c "This is a test" userl
修改用户 user1 密码过期时间:
passwd -e user1
更改用户 userl 的密码:
passwd userl
加锁用户 user1:
usermod -L user1
删除用户 user1 并删除其主目录:
userdel -r user1
将用户 st2 添加到附加组 student:
usermod -a -G student st2
将用户 st2 从附加组 student 中删除:
gpasswd -d st2 student
压缩和解压
打包
test目录为test.tar:tar -cf test.tar test打包并压缩
test目录为test.tar.gz:tar -czf test.tar.gz test查看
test.tar中的文件目录列表:tar -tf test.tar复制并解压
test.tar.gz到test1目录:mkdir test1 cp test.tar.gz test1 cd test1 tar -xzvf test.tar.gz ls -l
sed
输出1-3行之外的行:
sed '1,3d' test.txt显示含有两个及以上 ‘p’ 的行:
sed -n '/p.*p/p' test.txt显示含有连续两个及以上 ‘p’ 的行:
sed -n '/pp/p' test.txt含有重复字母的行:
sed -n '/\(.\)\1/p' test.txt含有连续重复字母的行:
sed -n '/\(.\)\1\1/p' test.txt删除第三行:
sed '3d' test.txt将替换第三行为 ‘abc123’:
sed '3cabc123' test.txt将所有的 ‘na’ 替换为 ‘12’:
sed 's/na/12/g' test.txt将所有3个长度的单词两边加 # 号:
sed 's/\b\(\w\{3\}\)\b/#\1#/g' test.txt将文中 ‘a’ 替换为 ‘1’, ‘b’ 替换为 ‘2’, ‘c’ 替换为 ‘3’:
sed 'y/abc/123/' test.txt将含有 ‘apple’ 或 ‘pear’ 的行,其中的 ‘red’ 替换成 ‘xxx’:
sed -n '/\(apple\|pear\)/s/red/xxx/p' test.txt将文件中以 ‘a’ 开头的并且含有 ‘red’ 的行中的所有 ‘sky’ 替换成 ‘xxx’:
sed -n '/^a.*red/s/sky/xxx/p' test.txt将 ‘red’ 或 ‘sky’ 替换为 ‘xxx’:
sed 's/red\|sky/xxx/g' test.txt将 ‘sky’ 替换为 ‘xxx’, 将 ‘red’ 替换为 ‘yyy’:
sed -e 's/sky/xxx/g' -e 's/red/yyy/g' test.txt在第3行后添加一行内容为 “hello world”:
sed '3a hello world' test.txt显示不以 ‘a’ 开始的行:
sed '/^a/!p' test.txt
awk
输出含有 ‘o’ 同时含有 ‘f’ 的行:
awk '/o/ && /f/' test.txt输出含有 ‘o’ 或含有 ‘f’ 的行:
awk '/o/ || /f/' test.txt输出第3列或第5列小于60的行:
awk '$3<60 || $5<60' student.txt打印每个人的姓名和总分:
awk '{sum = $3 + $4 + $5 + $6; print $1, sum}' student.txt打印有不及格的学生信息:
awk '$3<60 || $4<60 || $5<60 || $6<60 || $7<60' student.txt打印没有不及格的学生信息:
awk '$3>=60 && $4>=60 && $5>=60 && $6>=60 && $7>=60' student.txt计算第4列的平均成绩:
awk '{sum += $4} END {print sum/NR}' student.txt分别统计第5列成绩在不同分数段的人数:
awk '{score=int($5/10); if (score<6) score=5; if (score==10) score=9; freq[score]++} END {for (i=0; i<=9; i++) print i*10"->"(i*10+9)",", freq[i]}' student.txt总分最高的学生信息,考虑有并列的情况:
awk '{sum=$3+$4+$5+$6+$7; if (sum>max) {max=sum; delete arr} if (sum==max) arr[$1]++;} END {for (name in arr) print name, max}' student.txt
关于 mount 和 umount 的使用,以下是一些基本的命令和步骤:
mount 和 umount
访问U盘:
① 挂载U盘:
假设 U盘 被识别为/dev/sdb1(请注意,实际设备名可能不同),你可以使用以下命令挂载它到/mnt目录:sudo mount /dev/sdb1 /mnt② 使用U盘:
进入挂载点,创建文件:cd /mnt sudo touch a.test sudo touch haoxiugong这些文件将出现在 U盘 上,你可以在 Windows 下查看它们。
③ 卸载U盘:
使用以下命令卸载 U盘:sudo umount /mnt访问iso文件:
从群中下载
javaex.iso并拷贝到/root目录下。① 挂载iso文件:
挂载/root目录下的javaex.iso:sudo mount -o loop /root/javaex.iso /mnt这里
-o loop选项创建一个回环设备,它将.iso文件挂载为一个虚拟光驱。② 使用iso文件:
进入挂载点,你可以访问.iso文件中的内容:cd /mnt ls这将列出
.iso文件中的文件和目录。③ 卸载iso文件:
使用以下命令卸载.iso文件:sudo umount /mnt