转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
问题复现
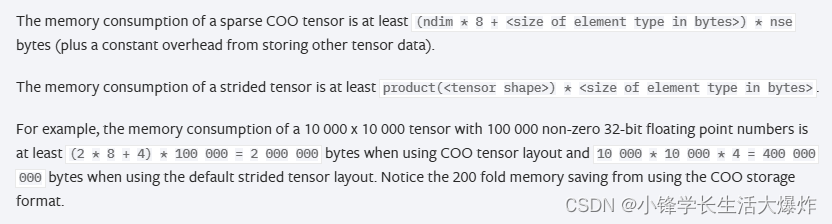
创建一个COO格式的稀疏矩阵,根据计算公式,他应该只占用约5120MB的内存:

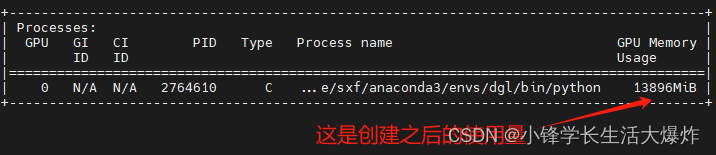
但通过nvidia-smi查看,实际上占用了10240MB:

网上对此的讨论又是没有找到,只好又是自己一点点摸索。
原因分析
对于CUDA的内存问题,那就可以使用torch.cuda.memory_stats()来看他的内存使用情况:
coo_matrix = sparse_matrix.to_sparse_coo()
print(torch.cuda.memory_stats())输出结果:
OrderedDict([('active.all.allocated', 24), ('active.all.current', 6), ('active.all.freed', 18), ('active.all.peak', 8), ('active.large_pool.allocated', 11), ('active.large_pool.current', 6), ('active.large_pool.freed', 5), ('active.large_pool.peak', 8), ('active.small_pool.allocated', 13), ('active.small_pool.current', 0), ('active.small_pool.freed', 13), ('active.small_pool.peak', 2), ('active_bytes.all.allocated', 15313152512), ('active_bytes.all.current', 8598454272), ('active_bytes.all.freed', 6714698240), ('active_bytes.all.peak', 13967163392), ('active_bytes.large_pool.allocated', 15312696832), ('active_bytes.large_pool.current', 8598454272), ('active_bytes.large_pool.freed', 6714242560), ('active_bytes.large_pool.peak', 13967163392), ('active_bytes.small_pool.allocated', 455680), ('active_bytes.small_pool.current', 0), ('active_bytes.small_pool.freed', 455680), ('active_bytes.small_pool.peak', 80896), ('allocated_bytes.all.allocated', 15313152512), ('allocated_bytes.all.current', 8598454272), ('allocated_bytes.all.freed', 6714698240), ('allocated_bytes.all.peak', 13967163392), ('allocated_bytes.large_pool.allocated', 15312696832), ('allocated_bytes.large_pool.current', 8598454272), ('allocated_bytes.large_pool.freed', 6714242560), ('allocated_bytes.large_pool.peak', 13967163392), ('allocated_bytes.small_pool.allocated', 455680), ('allocated_bytes.small_pool.current', 0), ('allocated_bytes.small_pool.freed', 455680), ('allocated_bytes.small_pool.peak', 80896), ('allocation.all.allocated', 24), ('allocation.all.current', 6), ('allocation.all.freed', 18), ('allocation.all.peak', 8), ('allocation.large_pool.allocated', 11), ('allocation.large_pool.current', 6), ('allocation.large_pool.freed', 5), ('allocation.large_pool.peak', 8), ('allocation.small_pool.allocated', 13), ('allocation.small_pool.current', 0), ('allocation.small_pool.freed', 13), ('allocation.small_pool.peak', 2), ('inactive_split.all.allocated', 3), ('inactive_split.all.current', 1), ('inactive_split.all.freed', 2), ('inactive_split.all.peak', 2), ('inactive_split.large_pool.allocated', 1), ('inactive_split.large_pool.current', 1), ('inactive_split.large_pool.freed', 0), ('inactive_split.large_pool.peak', 1), ('inactive_split.small_pool.allocated', 2), ('inactive_split.small_pool.current', 0), ('inactive_split.small_pool.freed', 2), ('inactive_split.small_pool.peak', 1), ('inactive_split_bytes.all.allocated', 20376064), ('inactive_split_bytes.all.current', 12451840), ('inactive_split_bytes.all.freed', 7924224), ('inactive_split_bytes.all.peak', 14548480), ('inactive_split_bytes.large_pool.allocated', 15808000), ('inactive_split_bytes.large_pool.current', 12451840), ('inactive_split_bytes.large_pool.freed', 3356160), ('inactive_split_bytes.large_pool.peak', 12451840), ('inactive_split_bytes.small_pool.allocated', 4568064), ('inactive_split_bytes.small_pool.current', 0), ('inactive_split_bytes.small_pool.freed', 4568064), ('inactive_split_bytes.small_pool.peak', 2096640), ('max_split_size', -1), ('num_alloc_retries', 0), ('num_ooms', 0), ('oversize_allocations.allocated', 0), ('oversize_allocations.current', 0), ('oversize_allocations.freed', 0), ('oversize_allocations.peak', 0), ('oversize_segments.allocated', 0), ('oversize_segments.current', 0), ('oversize_segments.freed', 0), ('oversize_segments.peak', 0), ('requested_bytes.all.allocated', 15313145274), ('requested_bytes.all.current', 8598453372), ('requested_bytes.all.freed', 6714691902), ('requested_bytes.all.peak', 13967161592), ('requested_bytes.large_pool.allocated', 15312695031), ('requested_bytes.large_pool.current', 8598453372), ('requested_bytes.large_pool.freed', 6714241659), ('requested_bytes.large_pool.peak', 13967161592), ('requested_bytes.small_pool.allocated', 450243), ('requested_bytes.small_pool.current', 0), ('requested_bytes.small_pool.freed', 450243), ('requested_bytes.small_pool.peak', 80000), ('reserved_bytes.all.allocated', 14250147840), ('reserved_bytes.all.current', 14250147840), ('reserved_bytes.all.freed', 0), ('reserved_bytes.all.peak', 14250147840), ('reserved_bytes.large_pool.allocated', 14248050688), ('reserved_bytes.large_pool.current', 14248050688), ('reserved_bytes.large_pool.freed', 0), ('reserved_bytes.large_pool.peak', 14248050688), ('reserved_bytes.small_pool.allocated', 2097152), ('reserved_bytes.small_pool.current', 2097152), ('reserved_bytes.small_pool.freed', 0), ('reserved_bytes.small_pool.peak', 2097152), ('segment.all.allocated', 10), ('segment.all.current', 10), ('segment.all.freed', 0), ('segment.all.peak', 10), ('segment.large_pool.allocated', 9), ('segment.large_pool.current', 9), ('segment.large_pool.freed', 0), ('segment.large_pool.peak', 9), ('segment.small_pool.allocated', 1), ('segment.small_pool.current', 1), ('segment.small_pool.freed', 0), ('segment.small_pool.peak', 1)])
这里快速推进。实际上我们只需要看reserved_bytes和active_bytes。其中,active_bytes.all.current 表示当前正在使用的所有活跃内存总量。在输出中,这个值为 8598454272 字节,约等于 8192 MB。reserved_bytes.all.current 表示当前已保留的所有内存总量。在输出中,这个值为 14250147840 字节,约等于 13595 MB。
因此,很明显这多出来的内存占用,实际上是reserved_bytes搞的。
- 活跃内存(Active Memory):指当前正在使用的显存量,包括已经分配并且正在使用的内存。
- 保留内存(Reserved Memory):指已经分配但尚未使用的显存量。这些内存空间可能会被保留以备将来使用,或者是由于内存碎片而导致的无法立即分配给新的内存请求。总的来说,保留的所有内存总量是由系统根据实时的内存使用情况和策略进行动态调整和触发的。它的目的是优化内存的分配和释放,以提高系统的性能和稳定性。
解决方案
知道了原因,那么就很好处理了。我们可以通过torch.cuda.empty_cache()清空缓存来删掉这部分保留的内存:
coo_matrix = sparse_matrix.to_sparse_coo()
print('memory_allocated: ', torch.cuda.memory_allocated())
print('memory_reserved: ', torch.cuda.memory_reserved())
torch.cuda.empty_cache()
print('empty_cache done!')
print('memory_allocated: ', torch.cuda.memory_allocated())
print('memory_reserved: ', torch.cuda.memory_reserved())输出:
memory_allocated: 8598454272
memory_reserved: 14250147840
empty_cache done!
memory_allocated: 8598454272
memory_reserved: 8613003264
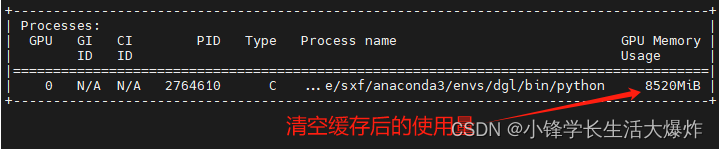
可以看到已经成功删除了多的部分。
碎碎念
1、可能还有其他方法,欢迎评论讨论~
2、如果不是后面不会再有GPU内存申请了,这个保留内存实际还是建议保留的。比如以下这个连续创建矩阵的,那么在创建第二个矩阵的时候,就不会再去申请新的内存,而是会放在保留内存里。因此这样会更高效一点:
A = create_dense_matrix(size, device=env.device)
B = create_dense_matrix(size, device=env.device)